按时间归档:2017年11月27日
-
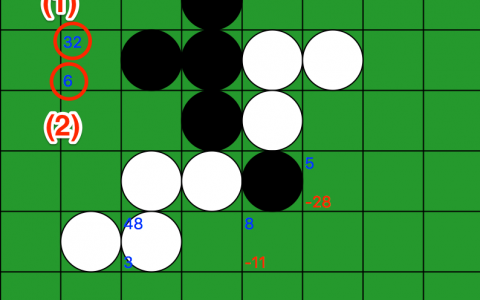
基于 AlphaGo Zero 的思想实现的黑白棋强化学习【附实战对局结果和一个国际象棋项目】
简介 Reversi reinforcement learning by AlphaGo Zero methods. 环境 Python 3.6.3 tensorflow-gpu:…
-
利用 AutoML 进行大规模图像分类和对象检测
文 / Google Brain 团队研究科学家 Barret Zoph、Vijay Vasudevan、Jonathon Shlens 和 Quoc Le 几个月之前,我们推出了…