
使用Keras进行深度学习:(一)Keras 入门
本文是全系列中第8 / 9篇:Keras 从入门到精通
Keras是Python中以CNTK、Tensorflow或者Theano为计算后台的一个深度学习建模环境。相对于其他深度学习的计算软件,如:Tensorflow、Theano、Caffe等,Keras在实际应用中有一些显著的优点,其中最主要的优点就是Keras已经高度模块化了,支持现有的常见模型(CNN、RNN等),更重要的是建模过程相当方便快速,加快了开发速度。
笔者使用的是基于Tensorflow为计算后台。接下来将介绍一些建模过程的常用层、搭建模型和训练过程,而Keras中的文字、序列和图像数据预处理,我们将在相应的实践项目中进行讲解。
1.核心层(各层函数只介绍一些常用参数,详细参数介绍可查阅Keras文档)
1.1全连接层:神经网络中最常用到的,实现对神经网络里的神经元激活。
Dense(units, activation=’relu’, use_bias=True)
参数说明:
units: 全连接层输出的维度,即下一层神经元的个数。
activation:激活函数,默认使用Relu。
use_bias:是否使用bias偏置项。
1.2激活层:对上一层的输出应用激活函数。
Activation(activation)
参数说明:
Activation:想要使用的激活函数,如:’relu’、’tanh’、‘sigmoid’等。
1.3Dropout层:对上一层的神经元随机选取一定比例的失活,不更新,但是权重仍然保留,防止过拟合。
Dropout(rate)
参数说明:
rate:失活的比例,0-1的浮点数。
1.4Flatten层:将一个维度大于或等于3的高维矩阵,“压扁”为一个二维矩阵。即保留第一个维度(如:batch的个数),然后将剩下维度的值相乘作为“压扁”矩阵的第二个维度。
Flatten()
1.5Reshape层:该层的作用和reshape一样,就是将输入的维度重构成特定的shape。
Reshape(target_shape)
参数说明:
target_shape:目标矩阵的维度,不包含batch样本数。
如我们想要一个9个元素的输入向量重构成一个(None, 3, 3)的二维矩阵:
Reshape((3,3), input_length=(16, ))
1.6卷积层:卷积操作分为一维、二维、三维,分别为Conv1D、Conv2D、Conv3D。一维卷积主要应用于以时间序列数据或文本数据,二维卷积通常应用于图像数据。由于这三种的使用和参数都基本相同,所以主要以处理图像数据的Conv2D进行说明。
Conv2D(filters, kernel_size, strides=(1, 1), padding=’valid’)
参数说明:
filters:卷积核的个数。
kernel_size:卷积核的大小。
strdes:步长,二维中默认为(1, 1),一维默认为1。
Padding:补“0”策略,’valid‘指卷积后的大小与原来的大小可以不同,’same‘则卷积后大小与原来大小一致。
1.7池化层:与卷积层一样,最大统计量池化和平均统计量池化也有三种,分别为MaxPooling1D、MaxPooling2D、MaxPooling3D和AveragePooling1D、AveragePooling2D、AveragePooling3D,由于使用和参数基本相同,所以主要以MaxPooling2D进行说明。
MaxPooling(pool_size=(2,2), strides=None, padding=’valid’)
参数说明:
pool_size:长度为2的整数tuple,表示在横向和纵向的下采样样子,一维则为纵向的下采样因子。
padding:和卷积层的padding一样。
1.8循环层:循环神经网络中的RNN、LSTM和GRU都继承本层,所以该父类的参数同样使用于对应的子类SimpleRNN、LSTM和GRU。
Recurrent(return_sequences=False)
return_sequences:控制返回的类型,“False”返回输出序列的最后一个输出,“True”则返回整个序列。当我们要搭建多层神经网络(如深层LSTM)时,若不是最后一层,则需要将该参数设为True。
1.9嵌入层:该层只能用在模型的第一层,是将所有索引标号的稀疏矩阵映射到致密的低维矩阵。如我们对文本数据进行处理时,我们对每个词编号后,我们希望将词编号变成词向量就可以使用嵌入层。
Embedding(input_dim, output_dim, input_length)
参数说明:
Input_dim:大于或等于0的整数,字典的长度即输入数据的个数。
output_dim:输出的维度,如词向量的维度。
input_length:当输入序列的长度为固定时为该长度,然后要在该层后加上Flatten层,然后再加上Dense层,则必须指定该参数,否则Dense层无法自动推断输出的维度。
该层可能有点费解,举个例子,当我们有一个文本,该文本有100句话,我们已经通过一系列操作,使得文本变成一个(100,32)矩阵,每行代表一句话,每个元素代表一个词,我们希望将该词变为64维的词向量:
Embedding(100, 64, input_length=32)
则输出的矩阵的shape变为(100, 32, 64):即每个词已经变成一个64维的词向量。
2.Keras模型搭建
讲完了一些常用层的语法后,通过模型搭建来说明Keras的方便性。Keras中设定了两类深度学习的模型,一类是序列模型(Sequential类);一类是通用模型(Model类),接下来我们通过搭建下图模型进行讲解。
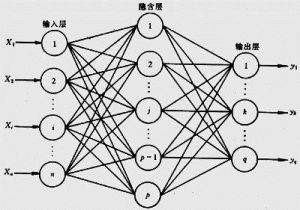
图 1:两层神经网络
假设我们有一个两层神经网络,其中输入层为784个神经元,隐藏层为32个神经元,输出层为10个神经元,隐藏层使用relu激活函数,输出层使用softmax激活函数。分别使用序列模型和通用模型实现如下:

图 2:导入相关库

图 3:序列模型实现
使用序列模型,首先我们要实例化Sequential类,之后就是使用该类的add函数加入我们想要的每一层,从而实现我们的模型。

图 4:通用模型实现
使用通用模型,首先要使用Input函数将输入转化为一个tensor,然后将每一层用变量存储后,作为下一层的参数,最后使用Model类将输入和输出作为参数即可搭建模型。
从以上两类模型的简单搭建,都可以发现Keras在搭建模型比起Tensorflow等简单太多了,如Tensorflow需要定义每一层的权重矩阵,输入用占位符等,这些在Keras中都不需要,我们只要在第一层定义输入维度,其他层定义输出维度就可以搭建起模型,通俗易懂,方便高效,这是Keras的一个显著的优势。
3.模型优化和训练
3.1compile(optimizer, loss, metrics=None)
参数说明:
optimizer:优化器,如:’SGD‘,’Adam‘等。
loss:定义模型的损失函数,如:’mse’,’mae‘等。
metric:模型的评价指标,如:’accuracy‘等。
3.2fit(x=None, y=None, batch_size=None, epochs=1, verbose=1, validation_split=0.0)
参数说明:
x:输入数据。
y:标签。
batch_size:梯度下降时每个batch包含的样本数。
epochs:整数,所有样本的训练次数。
verbose:日志显示,0为不显示,1为显示进度条记录,2为每个epochs输出一行记录。
validation_split:0-1的浮点数,切割输入数据的一定比例作为验证集。

图 5:优化和训练实现
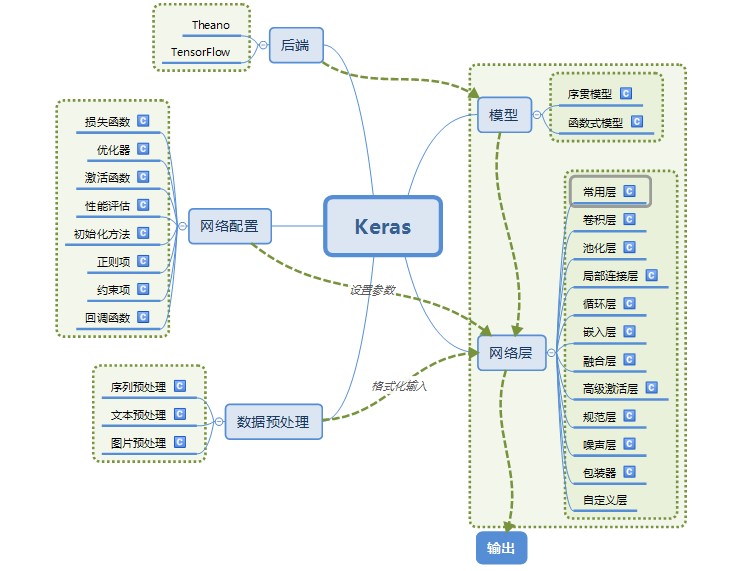
最后用以下图片总结keras的模块,下一篇文章我们将会使用keras来进行项目实践,从而更好的体会Keras的魅力。
原创文章,作者:Ray,如若转载,请注明出处:https://panchuang.net/2018/03/15/%e4%bd%bf%e7%94%a8keras%e8%bf%9b%e8%a1%8c%e6%b7%b1%e5%ba%a6%e5%ad%a6%e4%b9%a0%ef%bc%9a%ef%bc%88%e4%b8%80%ef%bc%89keras-%e5%85%a5%e9%97%a8/

评论列表(2条)
挺好的,问下下一篇什么时候更新
谢谢,刚刚已经更新了!