
用卷积神经网络和自注意力机制实现QANet(问答网络)
在这篇文章中,我们将解决自然语言处理(具体是指问答)中最具挑战性但最有趣的问题之一。我们将在Tensorflow中实现Google的QANet。就像它的机器翻译对应的Transformer网络一样,QANet根本不使用RNN,这使得训练/测试更快。
我假设你已经掌握了Python和Tensorflow的一些知识。
Question Answering是计算机科学在过去几年中取得了一些快速进展的领域。问答的一个典型例子是IBM的Watson在2011年参加的著名智力竞赛节目Jeopardy!,与传奇冠军布拉德鲁特和肯詹宁斯同台竞技,并赢得了第一名。
在这篇文章中,我们将重点关注开放领域的阅读理解,其中的问题可以来自任何领域,从美国流行歌星到抽象概念。阅读理解是一种问答,我们给出了一个段落,并且提出专门选出可以从段落中回答的问题。

IBM Watson在Jeopardy与Ken Jennings(左)和Brad Rutter(右)竞争!在2011年。来源:https://blog.ted.com/how-did-supercomputer-watson-beat-jeopardy-champion-ken-jennings-experts-discuss/
数据集(SQuAD)
我们将在这篇文章中使用的数据集称为斯坦福问答数据集(SQUAD)。 SQuAD有一些问题我们将回过头来看,它可能不是机器阅读理解的最佳数据集,但却是最广泛被研究的。如果您对可用于阅读理解的不同数据集感到好奇,还可以查看这个很棒的NLP数据集列表。
SQUAD的一个特点是问题的答案在于段落里面。以下是SQuAD格式的示例。
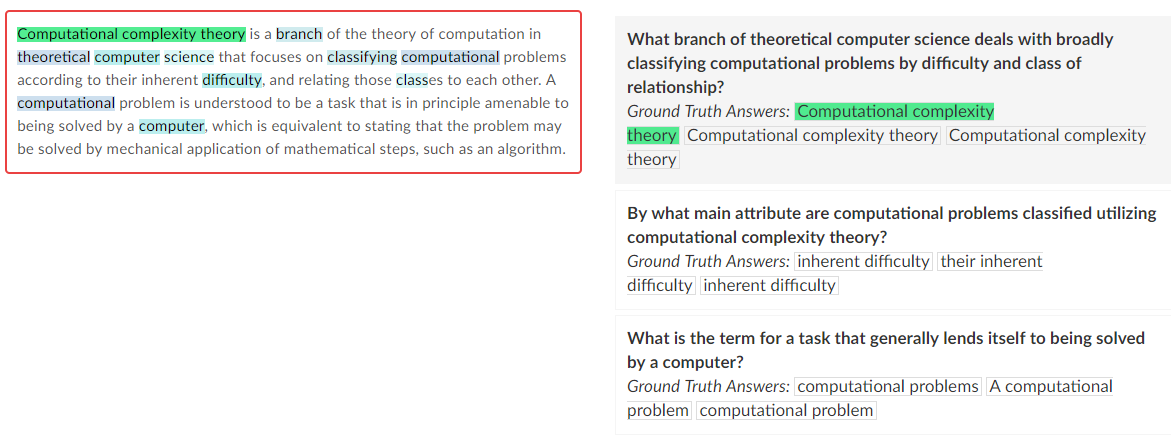
斯坦福问题问答数据集的一个例子。
资料来源:https://rajpurkar.github.io/SQuAD-explorer/
正如我们从上面的例子中可以看到的那样,无论问题多么容易或困难,这个问题的答案总是在段落本身内。
但首先,让我们来看看我们期望解决的各种问题和答案。通常情况下,问题本身已经是段落段的释义版本。例如,
P: “Computational complexity theory is a branch of the theory of computation in theoretical computer science that focuses on classifying computational problems according to their inherent difficulty, and relating those classes to each other. A computational problem is understood to be a task that is in principle amenable to being solved by a computer, which is equivalent to stating that the problem may be solved by mechanical application of mathematical steps, such as an algorithm.”
Q: “What is the term for a task that generally lends itself to being solved by a computer?”
A: “computational problem”
从用粗体突出显示的词语中可以清楚地看出,这个问题是从该段落中解释的。此属性使SQuAD问题本身比开放域问题回答问题更容易。因为我们现在需要做的就是从段落中找到一个句子,该句子在语义上与问题匹配,并从上下文中提取共同的语义或句法因素。虽然我们仍然需要解决语义和句法提取,但这比从可能有数万个单词的字典中找到答案要容易得多。
SQUAD的负面问题
上面提到的属性让我们使用一些技巧来轻松预测给定段落的答案。然而,这也给使用SQuAD训练的模型带来了一些问题。因为这些模型在很大程度上依赖于从段落中找到正确的句子,所以它们容易受到插入段落的对抗性句子的影响,这些句子类似于问题,但旨在欺骗网络。这是一个例子,

SQuAD的对抗性示例。资料来源:https://arxiv.org/pdf/1707.07328.pdf
以蓝色突出显示的句子是为欺骗网络而插入的对抗性示例。对于人类读者来说,它没有改变问题的答案:“超级碗XXXIII中38岁的四分卫的名字是什么?”,因为对抗性的判决正在谈论冠军杯XXXIV。然而,对于网络而言,对抗性句子与问题的对比情况要好于基本真实句子。
模型网络(QANet)
我们选择QANet模型的原因是这个模型简单。由于其简单的架构,它可以轻松实现,并且比大多数网络更快地进行相同任务的训练。 QANet架构可以从下图中看到:
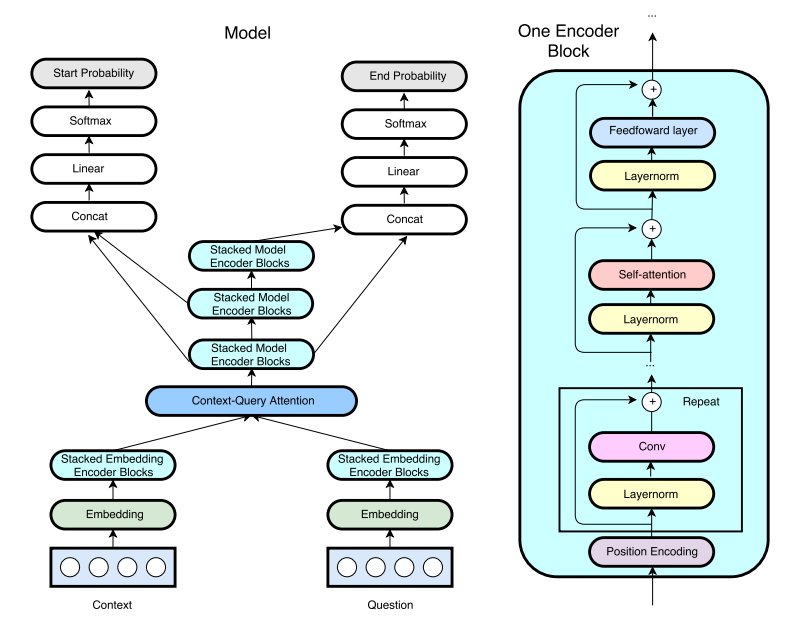
网络架构概述。资料来源:https://openreview.net/pdf?id = B14TlG-RW
模型网络可以分为大约3个部分。
1.词嵌入
2.编码器
3.注意力机制
词嵌入是将文本输入(段落和问题)转换为密集低维向量形式。这是通过类似于本文的方法完成的。
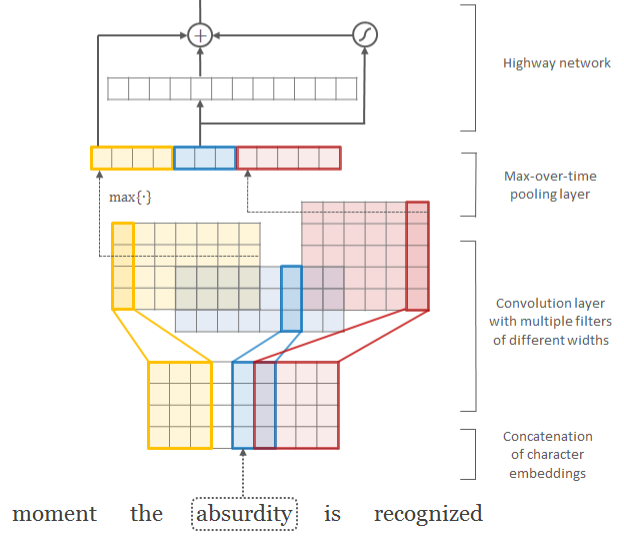
字符感知语言建模。资料来源:https://arxiv.org/pdf/1508.06615.pdf
我们的方法非常相似。唯一的区别是我们的卷积滤波器使用固定的内核大小5。在将它们放到高速网络之前,我们还将单词表示与最大池化字符表示连接起来。
编码器是模型的基本构建块。编码器模块的细节可以从上图的右侧看到。编码器由位置编码,层标准化,深度可分离1d卷积,自注意力机制和前馈层组成。
最后,自注意力层是网络的核心构建块,在这里问题和段落之间发生融合。 QANet使用BiDAF 中使用的三线性注意功能(trilinear attention function)。
让我们开始吧!
实现
为简单起见,我们跳过数据处理步骤并直接进行神经网络。
词嵌入
首先,我们定义输入占位符。一旦我们定义了占位符,我们就会用词嵌入作为单词输入,并使用字符嵌入作为字符输入。
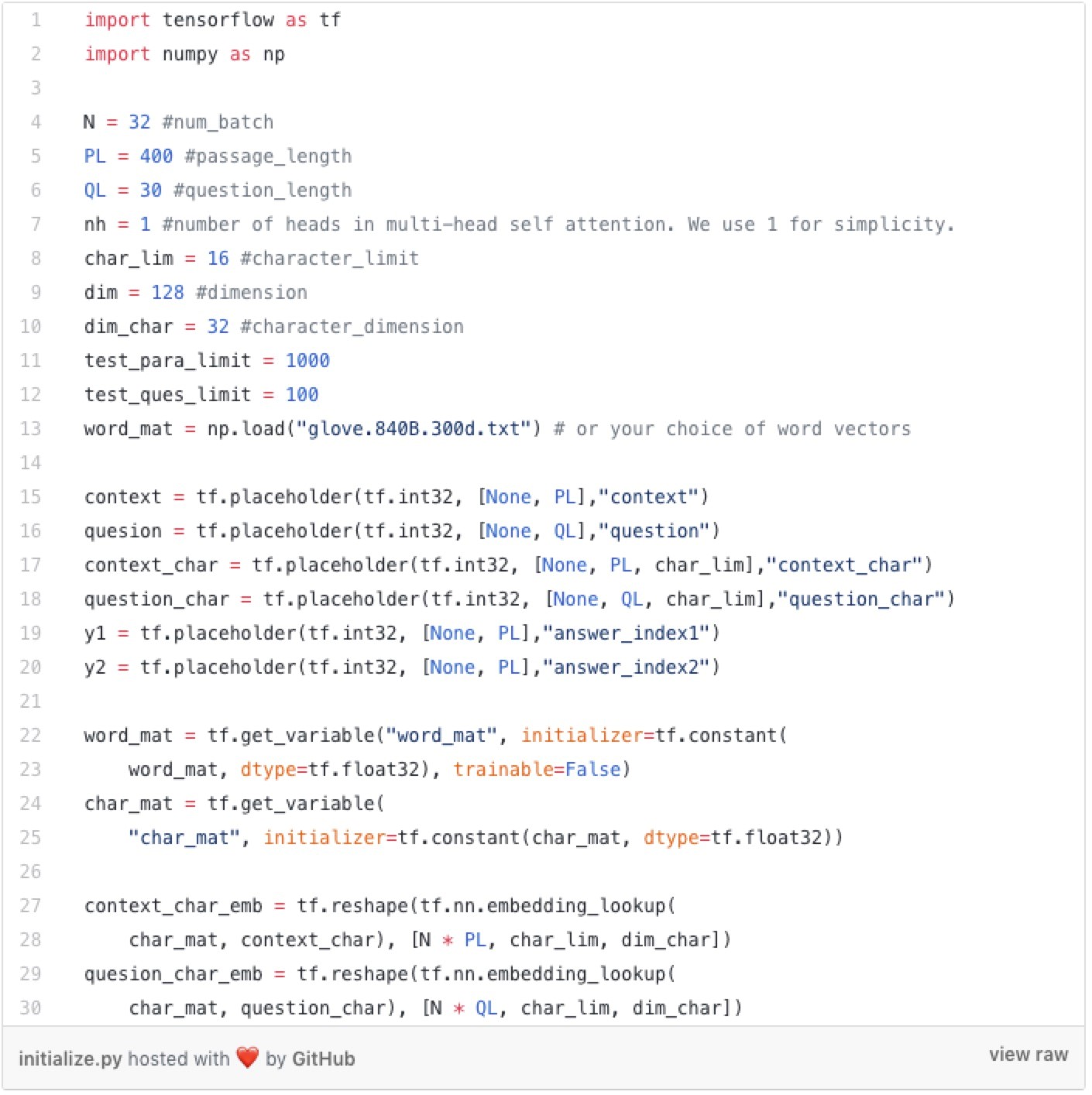
然后我们将它们通过1层1维卷积神经网络,最大池化,连接词+ 字符表示,最后通过2层高速网络。我们在“卷积”和“高速网络”功能中加入“重用”参数的原因是我们希望对段落和问题使用相同的网络。“卷积”和“高速网络”功能是我们Tensorflow实现的卷积神经网络和高速网络。
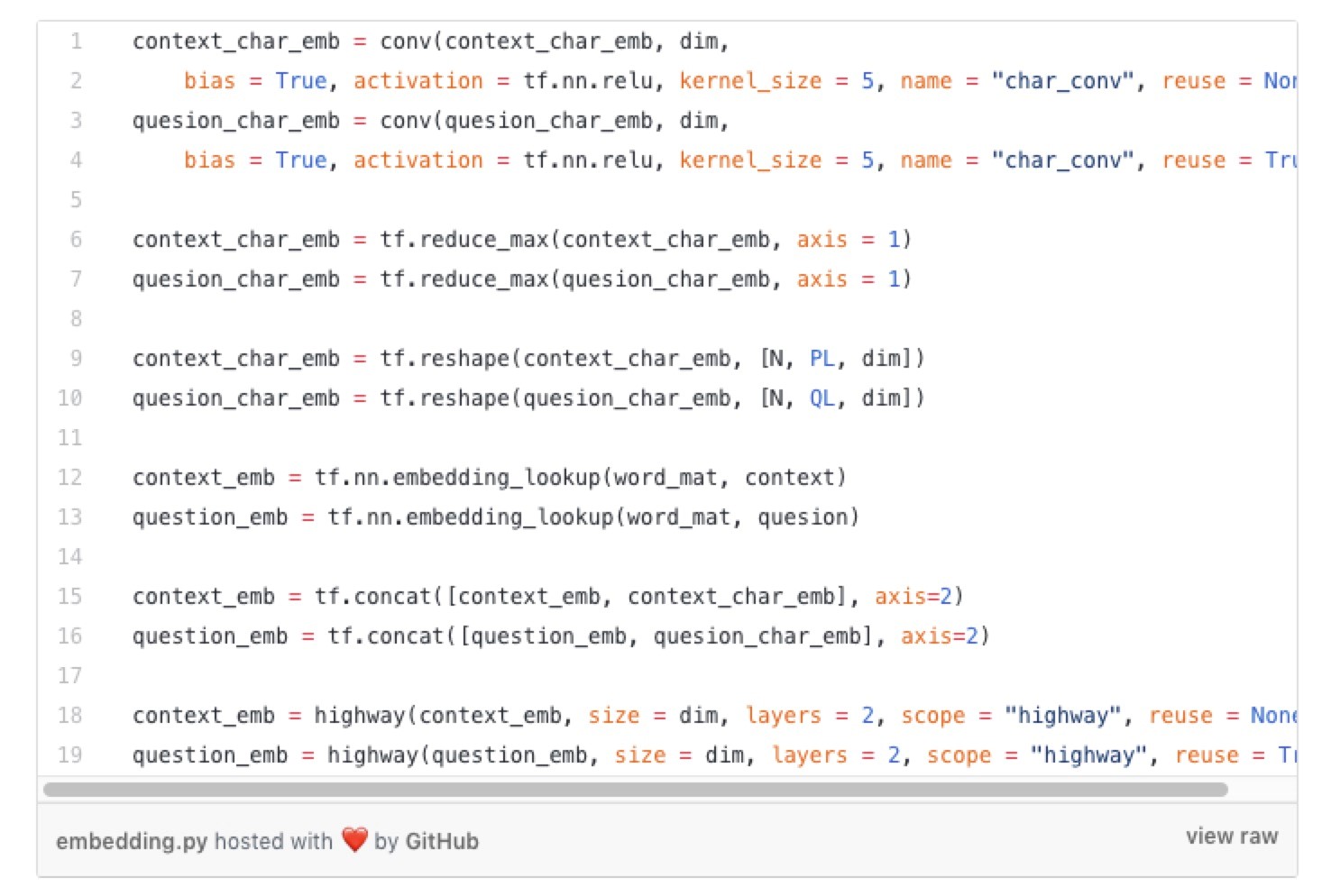
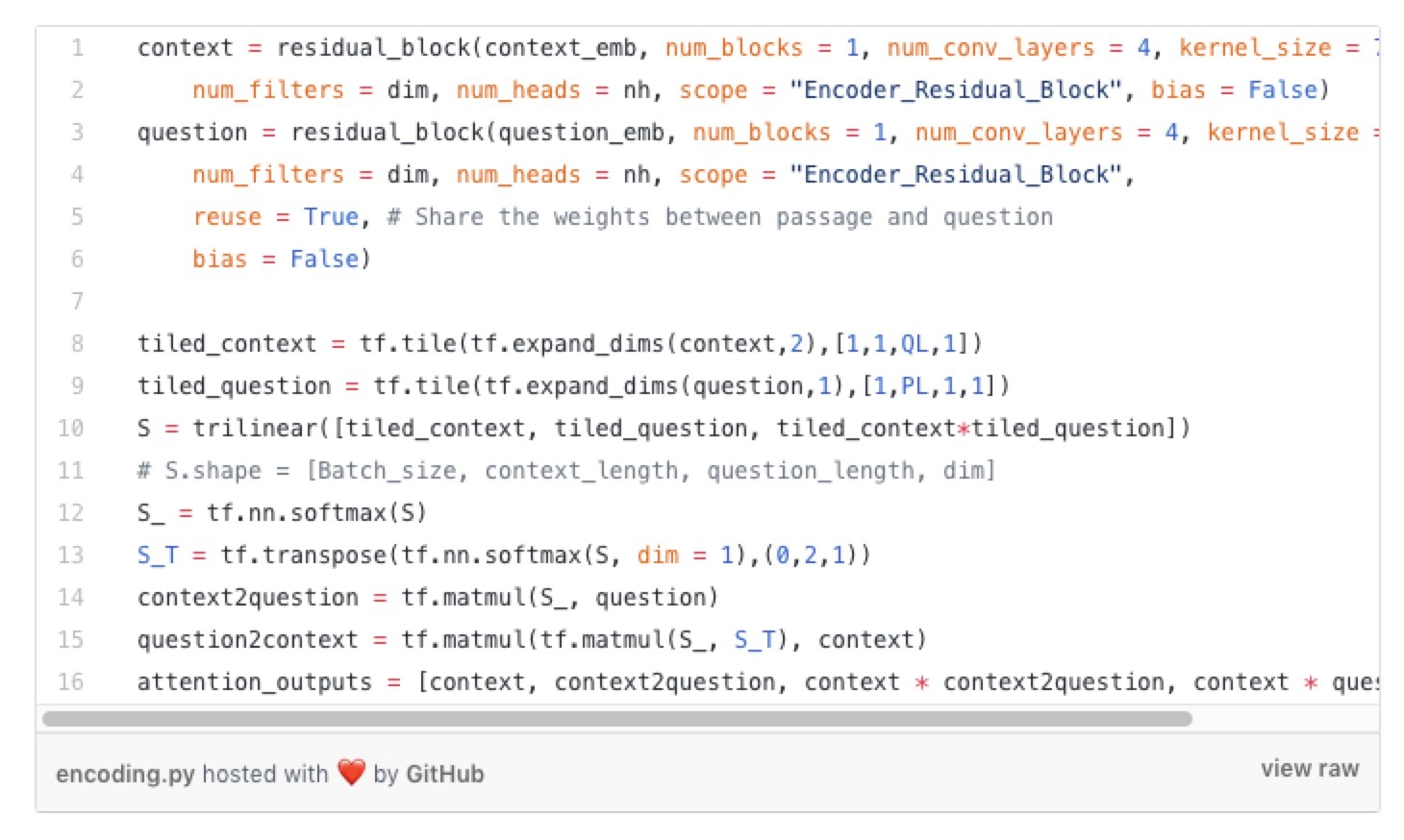
我们将嵌入层的输出放入编码器层以生成相应的上下文和问题表示。残差块实现位置编码 – > 层正则化- >深度可分离卷积 – >自注意力机制 – >前馈网络。
现在我们有了上下文和问题表示,我们使用称为三线性注意力机制(trilinear attention)的注意力函数将它们融合在一起。融合输出现在具有关于该问题的上下文的丰富信息。同样,我们将上下文-问题和问题-上下文信息与上下文连接起来,并作为编码器层的下一个输入。
最后,我们有输出层,它接收注意力层输出并将它们编码成一个密集的向量。这是SQuAD的特性有用的地方。因为我们知道答案在段落的某个地方,所以对于段落中的每个单词,我们只需要计算单词作为答案的概率。实际上,我们计算两个概率。相应单词属于答案开头的概率和相应单词属于答案结尾的概率。这样,我们不需要从大字典中找出答案,并且有效地计算概率。
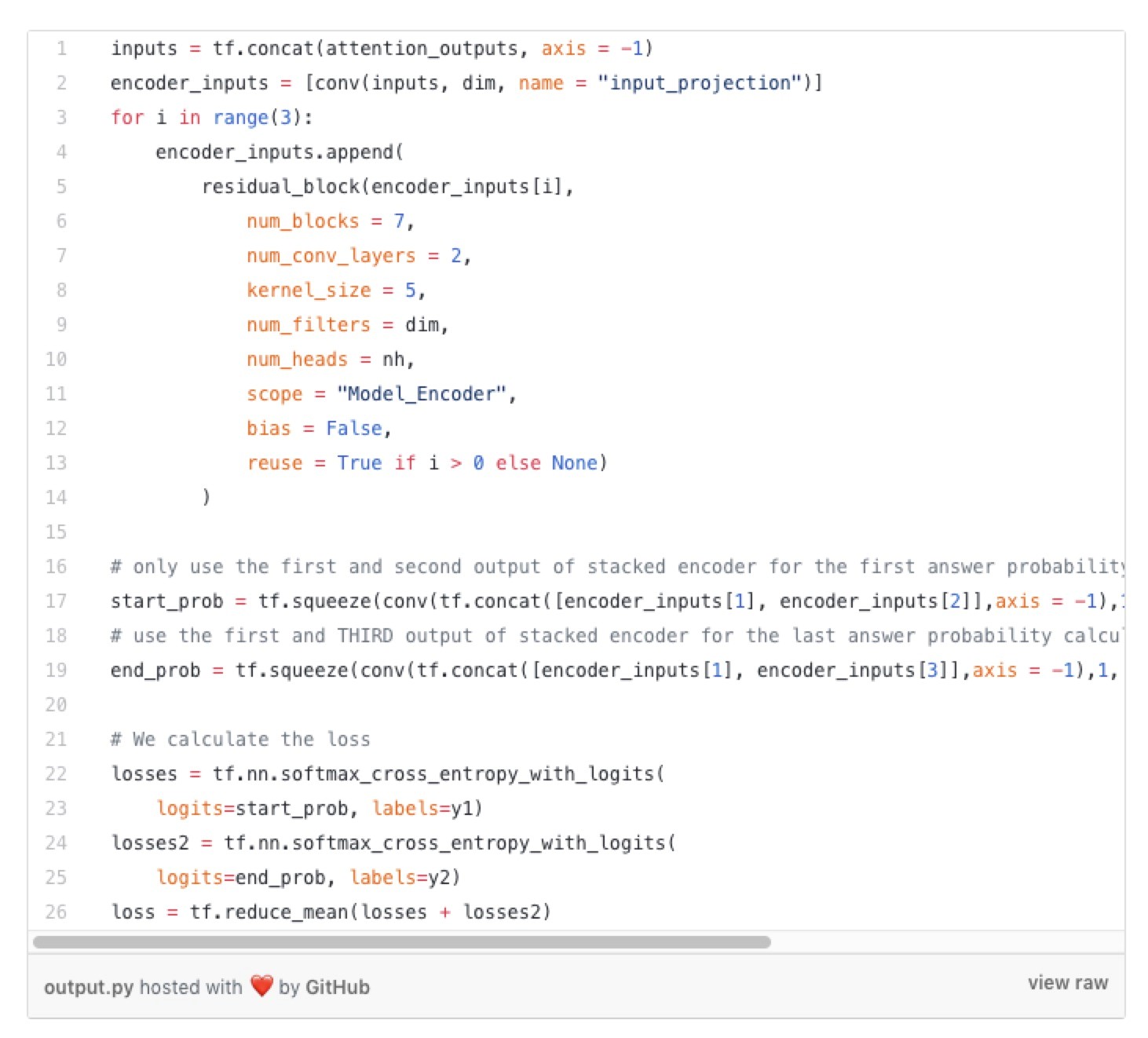
结束了!
训练和演示
与其他基于RNN的模型相比,QANet训练相对较快。与流行的BiDAF网络相比,QANet的性能提升约5~6倍。我们用 60,000次全局步骤训练网络,在GTX1080 GPU上大约需要6个小时。
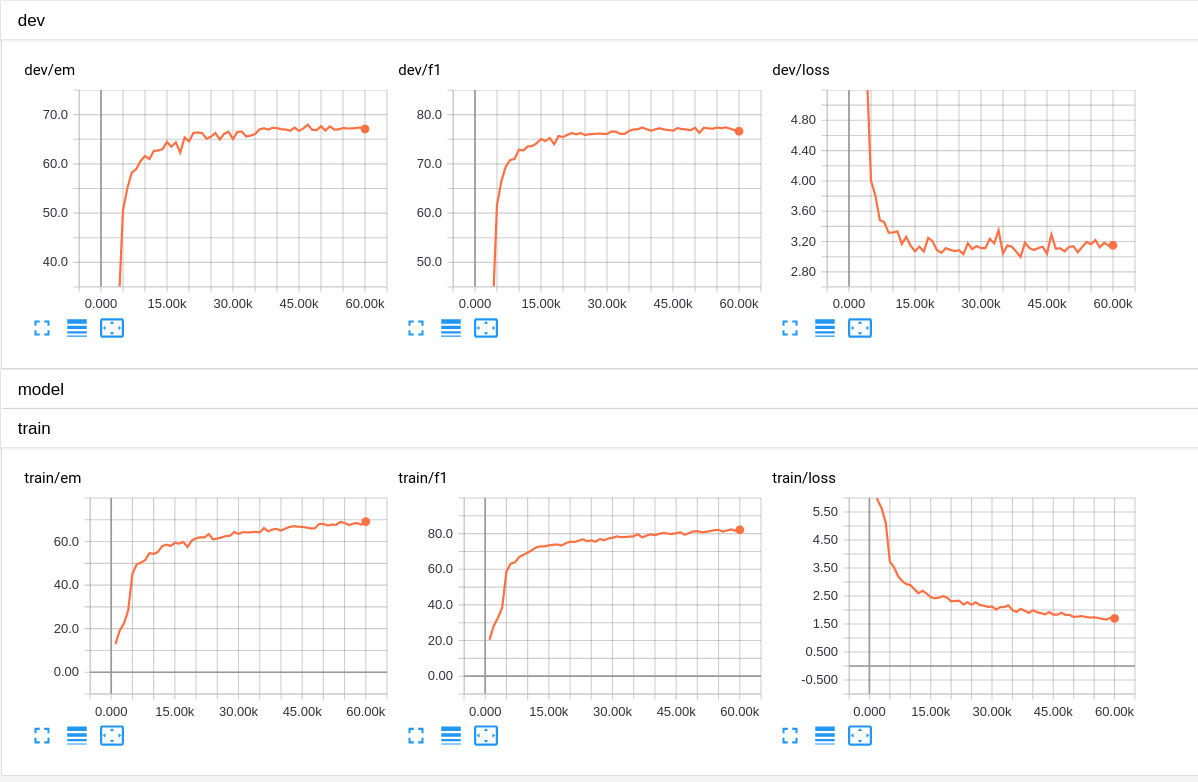
在Tensorboard中可视化结果。顶部图是验证集结果,底部是训练集结果。 “em”完全匹配,“f1”是F1得分。
这是非常简约的方法,但我希望它能帮助您理解基于神经网络的问答!如果您对他们有疑问,请发表评论,我会尽力回答您的问题。
感谢您的阅读,请在评论中留下问题或反馈!
英文原文链接:
https://medium.com/@minsangkim/implementing-question-answering-networks-with-cnns-5ae5f08e312b
项目链接:
https://github.com/NLPLearn/QANet
以上为原文,以下是实测训练截图:
训练时间和文章中提到的基本一致,使用 GTX 980 时间稍微长一些。
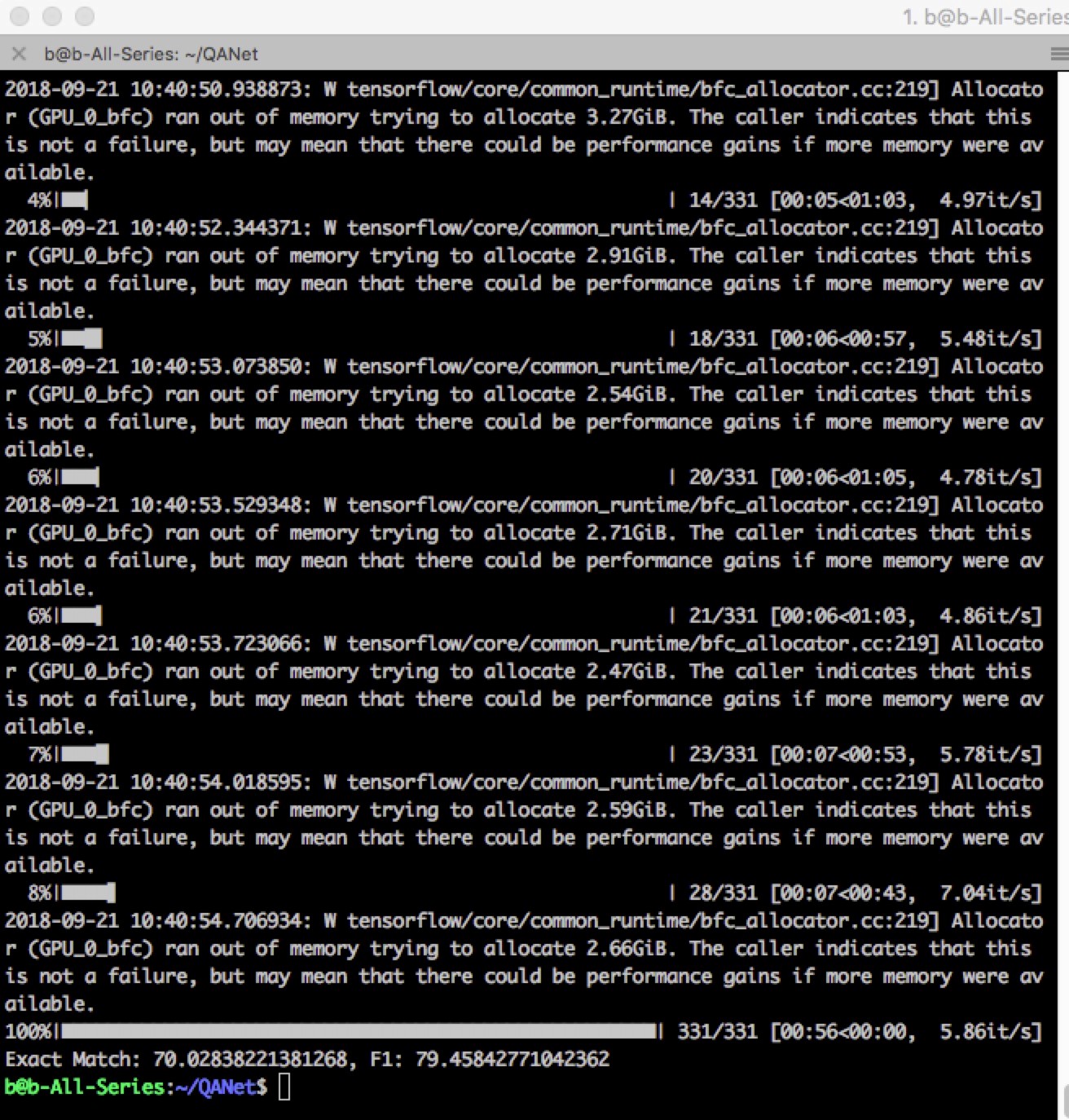
原创文章,作者:磐石,如若转载,请注明出处:https://panchuang.net/2018/09/26/%e7%94%a8%e5%8d%b7%e7%a7%af%e7%a5%9e%e7%bb%8f%e7%bd%91%e7%bb%9c%e5%92%8c%e8%87%aa%e6%b3%a8%e6%84%8f%e5%8a%9b%e6%9c%ba%e5%88%b6%e5%ae%9e%e7%8e%b0qanet%ef%bc%88%e9%97%ae%e7%ad%94%e7%bd%91%e7%bb%9c/
