
作者|Low Wei Hong
编译|VK
来源|Medium

当我还是一名大学生的时候,我很好奇自动提取简历信息是如何工作的。我将准备各种格式的简历,并上传到招聘网站,以测试背后的算法是如何工作的。我想自己尝试建一个。因此,在最近几周的空闲时间里,我决定构建一个简历解析器。
一开始,我觉得很简单。只是用一些模式来挖掘信息,结果发现我错了!构建简历解析器很困难,简历的布局有很多种,你可以想象。
例如,有些人会把日期放在简历的标题前面,有些人不把工作经历的期限写在简历上,有些人不会在简历上列出公司。这使得简历解析器更难构建,因为没有要捕获的固定模式。
经过一个月的工作,根据我的经验,我想和大家分享哪些方法工作得很好,在开始构建自己的简历分析器之前,你应该注意哪些事情。
在详细介绍之前,这里有一段视频短片,它显示了我的简历分析器的最终结果(https://youtu.be/E-yMeqjXzEA)
数据收集
我在多个网站上搜了800份简历。简历可以是PDF格式,也可以是doc格式。
我使用的工具是Google的Puppeter(Javascript)从几个网站收集简历。
数据收集的一个问题是寻找一个好的来源来获取简历。在你能够发现它之后,只要你不频繁地访问服务器,抓取一部分就可以了。
之后,我选择了一些简历,并手动将数据标记到每个字段。标记工作的完成是为了比较不同解析方法的性能。
预处理数据
剩下的部分,我使用Python。有几个包可用于将PDF格式解析为文本,如PDF Miner、Apache Tika、pdftotree等。让我比较一下不同的文本提取方法。
使用PDF Miner的一个缺点是,在处理简历时,简历的格式类似于Linkedin的简历,如下所示。
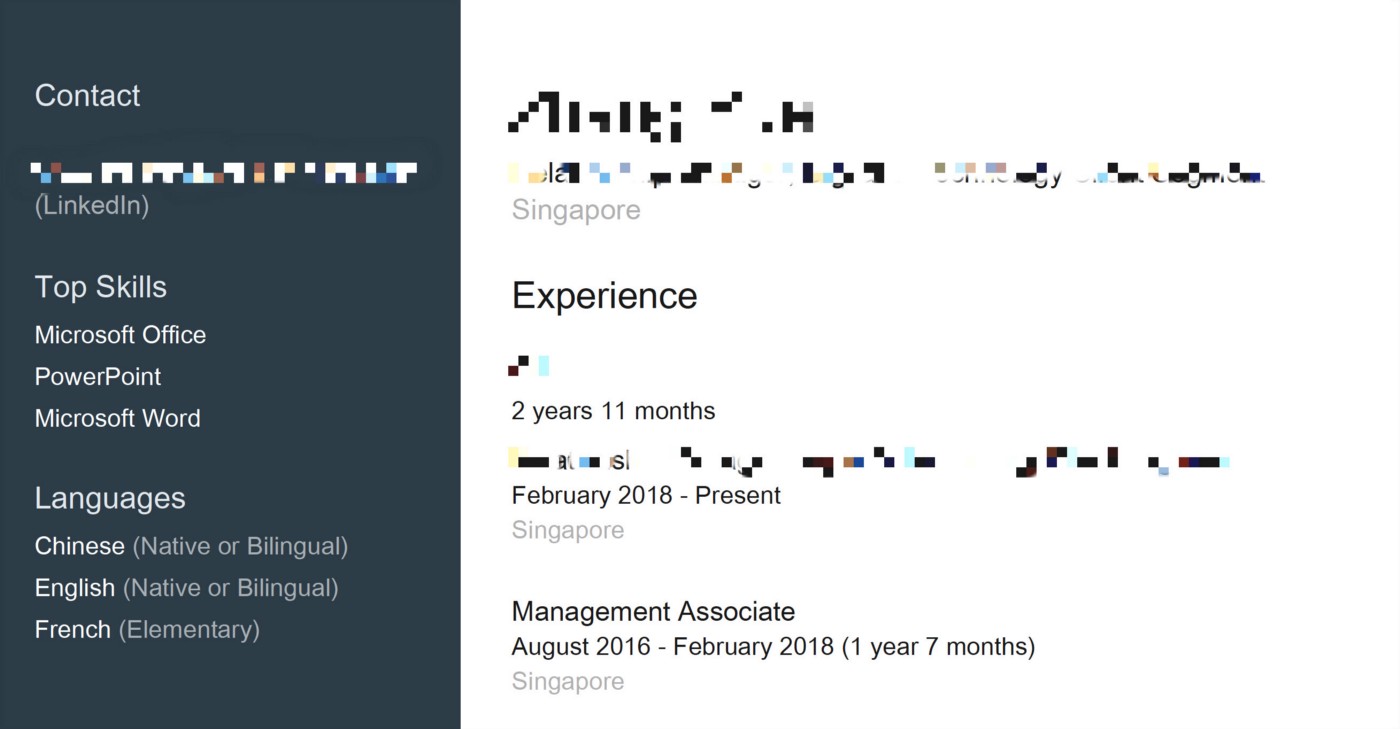
PDF Miner阅读PDF的方式是逐行的。因此,如果发现左右两部分的文本位于同一行,则将它们组合在一起。因此,正如你可以想象的那样,在随后的步骤中提取信息将更加困难。
另一方面,pdftree将省略所有的’n’字符,因此提取的文本将类似于文本块。因此,很难将它们分成多个部分。
因此,我使用的工具是Apache Tika,它似乎是解析PDF文件的更好选择,而对于docx文件,我使用docx包来解析。
数据提取流程概述
这是棘手的部分。有几种方法可以解决这个问题,但我将与你分享我发现的最佳方法和Baseline方法。
Baseline方法
我们先来谈谈Baseline方法。我使用的Baseline方法是首先为每个部分(这里我指的是经验、教育、个人细节和其他部分)抽取关键字,然后使用regex匹配它们。
例如,我想提取大学的名称。因此,我首先找到一个包含大多数大学的网站,并将其删除。然后,我使用regex检查是否可以在特定的简历中找到这个大学名称。如果找到了,这条信息将从简历中提取出来。
这样,我就可以构建一个Baseline方法,用来比较其他解析方法的性能。
最佳方法
这是我发现的最好的方法。
首先,我将把纯文本分成几个主要部分。例如,经验、教育、个人细节和其他。我要做的是为每个主要部分的标题设置一组关键字,例如工作经验、教育、总结、其他技能等等。
当然,你可以尝试建立一个机器学习模型来实现分离,但我选择了最简单的方法。
之后,将有一个单独的脚本来分别处理每个主要部分。每个脚本都将定义自己的规则,这些规则来提取每个字段的信息。每个脚本中的规则实际上都相当复杂。由于我希望这篇文章尽可能简单,所以我现在不会透露。
我使用的机器学习方法之一是区分公司名称和职务。我在这里使用机器学习模型的原因是,我发现有一些明显的模式可以区分公司名称和职务,例如,当你看到关键字“Private Limited”或“Pte Ltd”时,你肯定它是一个公司名称。
我在哪里能得到训练数据?
我从greenbook中搜集数据以获取公司名称,并从这个Github仓库中下载了职位列表(https://github.com/fluquid/find_job_titles)。
在得到数据后,我只训练了一个非常简单的朴素贝叶斯模型,它可以将职称分类的准确率提高至少10%。
总之,我解析简历解析器的策略是分而治之。
评估
我使用的评估方法是fuzzy-wuzzy方法(去重子集匹配)。比如说
- s=共同单词的数量
- s1=单词列表的交集
- s2=单词列表的交集+str1的剩余单词
- s3=单词列表的交集+str2的剩余单词
接下来的计算公式
token_set_ratio = max(fuzz.ratio(s, s1), fuzz.ratio(s, s2), fuzz.ratio(s, s3))
我使用token_set_ratio的原因是,如果解析的结果与标记的结果具有更多的公共标记,则意味着解析器的性能更好。
原文链接:https://towardsdatascience.com/how-to-build-a-简历-parsing-tool-ae19c062e377
原创文章,作者:磐石,如若转载,请注明出处:https://panchuang.net/2020/05/31/%e6%9e%84%e5%bb%ba%e7%ae%80%e5%8e%86%e8%a7%a3%e6%9e%90%e5%b7%a5%e5%85%b7/
