
学习Dataset类的来龙去脉,使用干净的代码结构,同时最大限度地减少在训练期间管理大量数据的麻烦。

神经网络训练在数据管理上可能很难做到“大规模”。
PyTorch 最近已经出现在我的圈子里,尽管对Keras和TensorFlow感到满意,但我还是不得不尝试一下。令人惊讶的是,我发现它非常令人耳目一新,非常讨人喜欢,尤其是PyTorch 提供了一个Pythonic API、一个更为固执己见的编程模式和一组很好的内置实用程序函数。我特别喜欢的一项功能是能够轻松地创建一个自定义的Dataset对象,然后可以与内置的DataLoader一起在训练模型时提供数据。
在本文中,我将从头开始研究PyTorchDataset对象,其目的是创建一个用于处理文本文件的数据集,以及探索如何为特定任务优化管道。我们首先通过一个简单示例来了解Dataset实用程序的基础知识,然后逐步完成实际任务。具体地说,我们想创建一个管道,从The Elder Scrolls(TES)系列中获取名称,这些名称的种族和性别属性作为一个one-hot张量。你可以在我的网站上找到这个数据集。
Dataset类的基础知识
Pythorch允许您自由地对“Dataset”类执行任何操作,只要您重写两个子类函数:
-返回数据集大小的函数,以及
-函数的函数从给定索引的数据集中返回一个样本。
数据集的大小有时可能是灰色区域,但它等于整个数据集中的样本数。因此,如果数据集中有10000个单词(或数据点、图像、句子等),则函数“uuLen_uUu”应该返回10000个。
PyTorch使您可以自由地对Dataset类执行任何操作,只要您重写改类中的两个函数即可:
__len__函数:返回数据集大小__getitem__函数:返回对应索引的数据集中的样本
数据集的大小有时难以确定,但它等于整个数据集中的样本数量。因此,如果您的数据集中有10,000个样本(数据点,图像,句子等),则__len__函数应返回10,000。
一个简单示例
首先,创建一个从1到1000所有数字的Dataset来模拟一个简单的数据集。我们将其适当地命名为NumbersDataset。
from torch.utils.data import Dataset
class NumbersDataset(Dataset):
def __init__(self):
self.samples = list(range(1, 1001))
def __len__(self):
return len(self.samples)
def __getitem__(self, idx):
return self.samples[idx]
if __name__ == '__main__':
dataset = NumbersDataset()
print(len(dataset))
print(dataset[100])
print(dataset[122:361])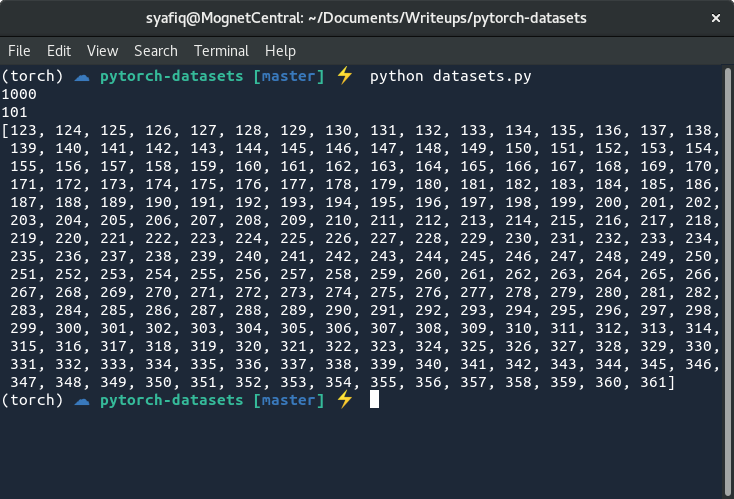
很简单,对吧?首先,当我们初始化NumbersDataset时,我们立即创建一个名为samples的列表,该列表将存储1到1000之间的所有数字。列表的名称是任意的,因此请随意使用您喜欢的名称。需要重写的函数是不用我说明的(我希望!),并且对在构造函数中创建的列表进行操作。如果运行该python文件,将看到1000、101和122到361之间的值,它们分别指的是数据集的长度,数据集中索引为100的数据以及索引为121到361之间的数据集切片。
扩展数据集
让我们扩展此数据集,以便它可以存储low和high之间的所有整数。
from torch.utils.data import Dataset
class NumbersDataset(Dataset):
def __init__(self, low, high):
self.samples = list(range(low, high))
def __len__(self):
return len(self.samples)
def __getitem__(self, idx):
return self.samples[idx]
if __name__ == '__main__':
dataset = NumbersDataset(2821, 8295)
print(len(dataset))
print(dataset[100])
print(dataset[122:361])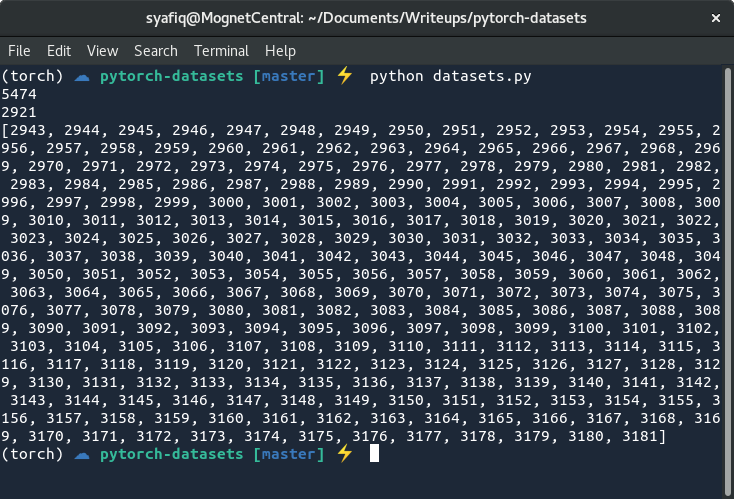
运行上面代码应在控制台打印5474、2921和2943到3181之间的数字。通过编写构造函数,我们现在可以将数据集的low和high设置为我们的想要的内容。这个简单的更改显示了我们可以从PyTorch的Dataset类获得的各种好处。例如,我们可以生成多个不同的数据集并使用这些值,而不必像在NumPy中那样,考虑编写新的类或创建许多难以理解的矩阵。
从文件读取数据
让我们来进一步扩展Dataset类的功能。PyTorch与Python标准库的接口设计得非常优美,这意味着您不必担心集成功能。在这里,我们将
- 创建一个全新的使用Python I/O和一些静态文件的
Dataset类 - 收集TES角色名称(我的网站上有可用的数据集),这些角色名称分为种族文件夹和性别文件,以填充
samples列表 - 通过在
samples列表中存储一个元组而不只是名称本身来跟踪每个名称的种族和性别。
TES名称数据集具有以下目录结构:
.
|-- Altmer/
| |-- Female
| `-- Male
|-- Argonian/
| |-- Female
| `-- Male
... (truncated for brevity)(为了简洁,这里进行省略)
`-- Redguard/
|-- Female
`-- Male每个文件都包含用换行符分隔的TES名称,因此我们必须逐行读取每个文件,以捕获每个种族和性别的所有字符名称。
import os
from torch.utils.data import Dataset
class TESNamesDataset(Dataset):
def __init__(self, data_root):
self.samples = []
for race in os.listdir(data_root):
race_folder = os.path.join(data_root, race)
for gender in os.listdir(race_folder):
gender_filepath = os.path.join(race_folder, gender)
with open(gender_filepath, 'r') as gender_file:
for name in gender_file.read().splitlines():
self.samples.append((race, gender, name))
def __len__(self):
return len(self.samples)
def __getitem__(self, idx):
return self.samples[idx]
if __name__ == '__main__':
dataset = TESNamesDataset('/home/syafiq/Data/tes-names/')
print(len(dataset))
print(dataset[420])我们来看一下代码:首先创建一个空的samples列表,然后遍历每个种族(race)文件夹和性别文件并读取每个文件中的名称来填充该列表。然后将种族,性别和名称存储在元组中,并将其添加到samples列表中。运行该文件应打印19491和('Bosmer', 'Female', 'Gluineth')(每台计算机的输出可能不太一样)。让我们看一下将数据集的一个batch的样子:
# 将main函数改成下面这样:
if __name__ == '__main__':
dataset = TESNamesDataset('/home/syafiq/Data/tes-names/')
print(dataset[10:60])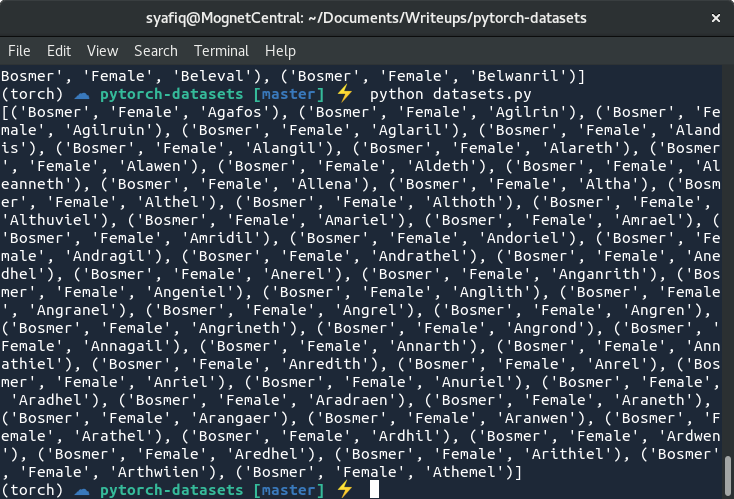
正如您所想的,它的工作原理与列表完全相同。对本节内容进行总结,我们刚刚将标准的Python I/O 引入了PyTorch数据集中,并且我们不需要任何其他特殊的包装器或帮助器,只需要单纯的Python代码。实际上,我们还可以包括NumPy或Pandas之类的其他库,并且通过一些巧妙的操作,使它们在PyTorch中发挥良好的作用。让我们现在来看看在训练时如何有效地遍历数据集。
用DataLoader加载数据
尽管Dataset类是创建数据集的一种不错的方法,但似乎在训练时,我们将需要对数据集的samples列表进行索引或切片。这并不比我们对列表或NumPy矩阵进行操作更简单。PyTorch并没有沿这条路走,而是提供了另一个实用工具类DataLoader。DataLoader充当Dataset对象的数据馈送器(feeder)。如果您熟悉的话,这个对象跟Keras中的flow数据生成器函数很类似。DataLoader需要一个Dataset对象(它延伸任何子类)和其他一些可选参数(参数都列在PyTorch的DataLoader文档中)。在这些参数中,我们可以选择对数据进行打乱,确定batch的大小和并行加载数据的线程(job)数量。这是TESNamesDataset在循环中进行调用的一个简单示例。
# 将main函数改成下面这样:
if __name__ == '__main__':
from torch.utils.data import DataLoader
dataset = TESNamesDataset('/home/syafiq/Data/tes-names/')
dataloader = DataLoader(dataset, batch_size=50, shuffle=True, num_workers=2)
for i, batch in enumerate(dataloader):
print(i, batch)当您看到大量的batch被打印出来时,您可能会注意到每个batch都是三元组的列表:第一个元组包含种族,下一个元组包含性别,最后一个元祖包含名称。
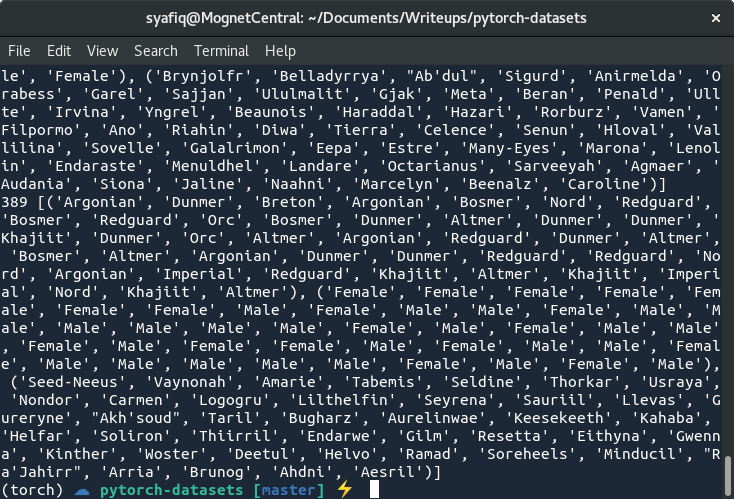
等等,那不是我们之前对数据集进行切片时的样子!这里到底发生了什么?好吧,事实证明,DataLoader以系统的方式加载数据,以便我们垂直而非水平来堆叠数据。这对于一个batch的张量(tensor)流动特别有用,因为张量垂直堆叠(即在第一维上)构成batch。此外,DataLoader还会为对数据进行重新排列,因此在发送(feed)数据时无需重新排列矩阵或跟踪索引。
张量(tensor)和其他类型
为了进一步探索不同类型的数据在DataLoader中是如何加载的,我们将更新我们先前模拟的数字数据集,以产生两对张量数据:数据集中每个数字的后4个数字的张量,以及加入一些随机噪音的张量。为了抛出DataLoader的曲线球,我们还希望返回数字本身,而不是张量类型,是作为Python字符串返回。__getitem__函数将在一个元组中返回三个异构数据项。
from torch.utils.data import Dataset
import torch
class NumbersDataset(Dataset):
def __init__(self, low, high):
self.samples = list(range(low, high))
def __len__(self):
return len(self.samples)
def __getitem__(self, idx):
n = self.samples[idx]
successors = torch.arange(4).float() + n + 1
noisy = torch.randn(4) + successors
return n, successors, noisy
if __name__ == '__main__':
from torch.utils.data import DataLoader
dataset = NumbersDataset(100, 120)
dataloader = DataLoader(dataset, batch_size=10, shuffle=True)
print(next(iter(dataloader)))请注意,我们没有更改数据集的构造函数,而是修改了__getitem__函数。对于PyTorch数据集来说,比较好的做法是,因为该数据集将随着样本越来越多而进行缩放,因此我们不想在Dataset对象运行时,在内存中存储太多张量类型的数据。取而代之的是,当我们遍历样本列表时,我们将希望它是张量类型,以牺牲一些速度来节省内存。在以下各节中,我将解释它的用处。
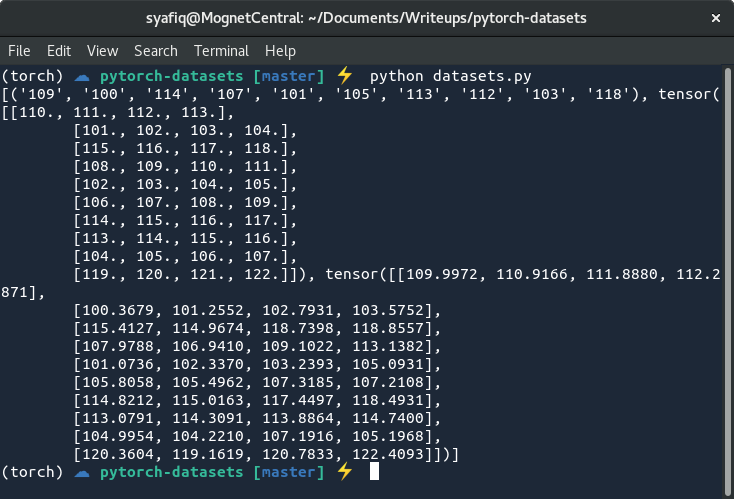
观察上面的输出,尽管我们新的__getitem__函数返回了一个巨大的字符串和张量元组,但是DataLoader能够识别数据并进行相应的堆叠。字符串化后的数字形成元组,其大小与创建DataLoader时配置的batch大小的相同。对于两个张量,DataLoader将它们垂直堆叠成一个大小为10x4的张量。这是因为我们将batch大小配置为10,并且在__getitem__函数返回两个大小为4的张量。
通常来说,DataLoader尝试将一批一维张量堆叠为二维张量,将一批二维张量堆叠为三维张量,依此类推。在这一点上,我恳请您注意到这对其他机器学习库中的传统数据处理产生了翻天覆地的影响,以及这个做法是多么优雅。太不可思议了!如果您不同意我的观点,那么至少您现在知道有这样的一种方法。
完成TES数据集的代码
让我们回到TES数据集。似乎初始化函数的代码有点不优雅(至少对于我而言,确实应该有一种使代码看起来更好的方法。请记住我说过的,PyTorch API是像python的(Pythonic)吗?数据集中的工具函数,甚至对内部函数进行初始化。为清理TES数据集的代码,我们将更新TESNamesDataset的代码来实现以下目的:
- 更新构造函数以包含字符集
- 创建一个内部函数来初始化数据集
- 创建一个将标量转换为独热(one-hot)张量的工具函数
- 创建一个工具函数,该函数将样本数据转换为种族,性别和名称的三个独热(one-hot)张量的集合。
为了使工具函数正常工作,我们将借助scikit-learn库对数值(即种族,性别和名称数据)进行编码。具体来说,我们将需要LabelEncoder类。我们对代码进行大量的更新,我将在接下来的几小节中解释这些修改的代码。
import os
from sklearn.preprocessing import LabelEncoder
from torch.utils.data import Dataset
import torch
class TESNamesDataset(Dataset):
def __init__(self, data_root, charset):
self.data_root = data_root
self.charset = charset
self.samples = []
self.race_codec = LabelEncoder()
self.gender_codec = LabelEncoder()
self.char_codec = LabelEncoder()
self._init_dataset()
def __len__(self):
return len(self.samples)
def __getitem__(self, idx):
race, gender, name = self.samples[idx]
return self.one_hot_sample(race, gender, name)
def _init_dataset(self):
races = set()
genders = set()
for race in os.listdir(self.data_root):
race_folder = os.path.join(self.data_root, race)
races.add(race)
for gender in os.listdir(race_folder):
gender_filepath = os.path.join(race_folder, gender)
genders.add(gender)
with open(gender_filepath, 'r') as gender_file:
for name in gender_file.read().splitlines():
self.samples.append((race, gender, name))
self.race_codec.fit(list(races))
self.gender_codec.fit(list(genders))
self.char_codec.fit(list(self.charset))
def to_one_hot(self, codec, values):
value_idxs = codec.transform(values)
return torch.eye(len(codec.classes_))[value_idxs]
def one_hot_sample(self, race, gender, name):
t_race = self.to_one_hot(self.race_codec, [race])
t_gender = self.to_one_hot(self.gender_codec, [gender])
t_name = self.to_one_hot(self.char_codec, list(name))
return t_race, t_gender, t_name
if __name__ == '__main__':
import string
data_root = '/home/syafiq/Data/tes-names/'
charset = string.ascii_letters + "-' "
dataset = TESNamesDataset(data_root, charset)
print(len(dataset))
print(dataset[420])修改的构造函数初始化
构造函数这里有很多变化,所以让我们一点一点地来解释它。您可能已经注意到构造函数中没有任何文件处理逻辑。我们已将此逻辑移至_init_dataset函数中,并清理了构造函数。此外,我们添加了一些编码器,来将原始字符串转换为整数并返回。samples列表也是一个空列表,我们将在_init_dataset函数中填充该列表。构造函数还接受一个新的参数charset。顾名思义,它只是一个字符串,可以将char_codec转换为整数。
已增强了文件处理功能,该功能可以在我们遍历文件夹时捕获种族和性别的唯一标签。如果您没有结构良好的数据集,这将很有用;例如,如果Argonians拥有一个与性别无关的名称,我们将拥有一个名为“Unknown”的文件,并将其放入性别集合中,而不管其他种族是否存在“Unknown”性别。所有名称存储完毕后,我们将在由种族,性别和名称构成数据集来初始化编码器。
工具函数
我们添加了两个工具函数:to_one_hot和one_hot_sample。to_one_hot使用数据集的内部编码器将数值列表转换为整数列表,然后再调用看似不适当的torch.eye函数。实际上,这是一种巧妙的技巧,可以将整数列表快速转换为一个向量。torch.eye函数创建一个任意大小的单位矩阵,其对角线上的值为1。如果对矩阵行进行索引,则将在该索引处获得值为1的行向量,这是独热向量的定义!
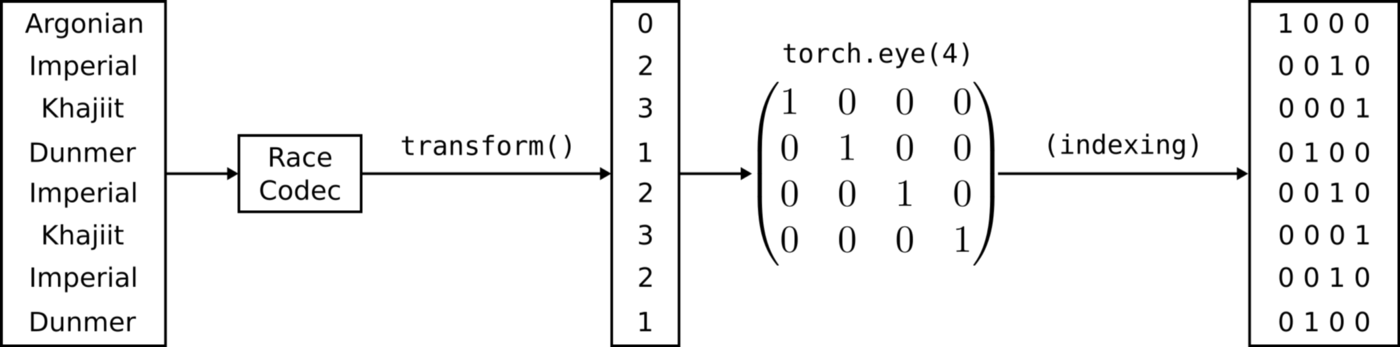
因为我们需要将三个数据转换为张量,所以我们将在对应数据的每个编码器上调用to_one_hot函数。one_hot_sample将单个样本数据转换为张量元组。种族和性别被转换为二维张量,这实际上是扩展的行向量。该向量也被转换为二维张量,但该二维向量包含该名称的每个字符每个独热向量。
__getitem__调用
最后,__getitem__函数的代码已更新为仅在one_hot_sample给定种族,性别和名称的情况下调用该函数。注意,我们不需要在samples列表中预先准备张量,而是仅在调用__getitem__函数(即DataLoader加载数据流时)时形成张量。当您在训练期间有成千上万的样本要加载时,这使数据集具有很好的可伸缩性。
您可以想象如何在计算机视觉训练场景中使用该数据集。数据集将具有文件名列表和图像目录的路径,从而让__getitem__函数仅读取图像文件并将它们及时转换为张量来进行训练。通过提供适当数量的工作线程,DataLoader可以并行处理多个图像文件,可以使其运行得更快。PyTorch数据加载教程有更详细的图像数据集,加载器,和互补数据集。这些都是由torchvision库进行封装的(它经常随着PyTorch一起安装)。torchvision用于计算机视觉,使得图像处理管道(例如增白,归一化,随机移位等)很容易构建。
回到原文。数据集已经构建好了,看来我们已准备好使用它进行训练……
……但我们还没有
如果我们尝试使用DataLoader来加载batch大小大于1的数据,则会遇到错误:
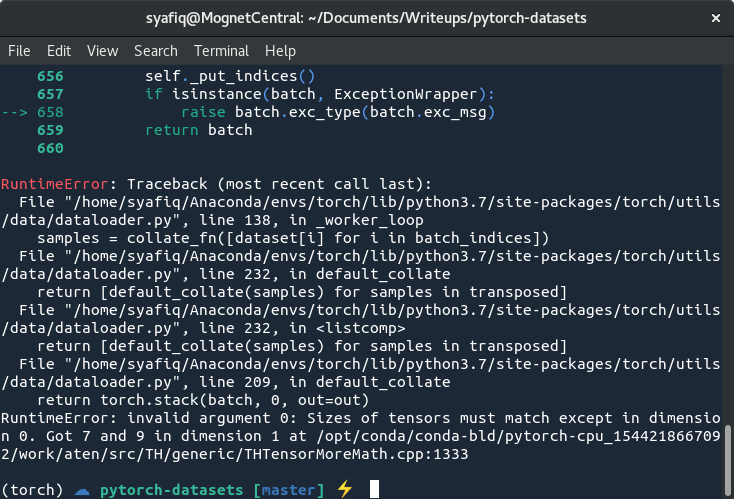
您可能已经看到过这种情况,但现实是,文本数据的不同样本之间很少有相同的长度。结果,DataLoader尝试批量处理多个不同长度的名称张量,这在张量格式中是不可能的,因为在NumPy数组中也是如此。为了说明此问题,请考虑以下情况:当我们将“ John”和“ Steven”之类的名称堆叠在一起形成一个单一的独热矩阵时。’John’转换为大小4xC的二维张量,’Steven’转换为大小6xC二维张量,其中C是字符集的长度。DataLoader尝试将这些名称堆叠为大小2x?xC三维张量(DataLoader认为堆积大小为1x4xC和1x6xC)。由于第二维不匹配,DataLoader抛出错误,导致它无法继续运行。
可能的解决方案
为了解决这个问题,这里有两种方法,每种方法都各有利弊。
- 将批处理(batch)大小设置为1,这样您就永远不会遇到错误。如果批处理大小为1,则单个张量不会与(可能)不同长度的其他任何张量堆叠在一起。但是,这种方法在进行训练时会受到影响,因为神经网络在单批次(batch)的梯度下降时收敛将非常慢。另一方面,当批次大小不重要时,这对于快速测试时,数据加载或沙盒测试很有用。
- 通过使用空字符填充或截断名称来获得固定的长度。截短长的名称或用空字符来填充短的名称可以使所有名称格式正确,并具有相同的输出张量大小,从而可以进行批处理。不利的一面是,根据任务的不同,空字符可能是有害的,因为它不能代表原始数据。
由于本文的目的,我将选择第二个方法,您只需对整体数据管道进行很少的更改即可实现此目的。请注意,这也适用于任何长度不同的字符数据(尽管有多种填充数据的方法,请参见NumPy和PyTorch中的选项部分)。在我的例子中,我选择用零来填充名称,因此我更新了构造函数和_init_dataset函数:
...
def __init__(self, data_root, charset, length):
self.data_root = data_root
self.charset = charset + '\0'
self.length = length
...
with open(gender_filepath, 'r') as gender_file:
for name in gender_file.read().splitlines():
if len(name) < self.length:
name += '\0' * (self.length - len(name))
else:
name = name[:self.length-1] + '\0'
self.samples.append((race, gender, name))
...首先,我在构造函数引入一个新的参数,该参数将所有传入名称字符固定为length值。我还将\0字符添加到字符集中,用于填充短的名称。接下来,数据集初始化逻辑已更新。缺少长度的名称仅用\0填充,直到满足长度的要求为止。超过固定长度的名称将被截断,最后一个字符将被替换为\0。替换是可选的,这取决于具体的任务。
而且,如果您现在尝试加载此数据集,您应该获得跟您当初所期望的数据:正确的批(batch)大小格式的张量。下图显示了批大小为2的张量,但请注意有三个张量:
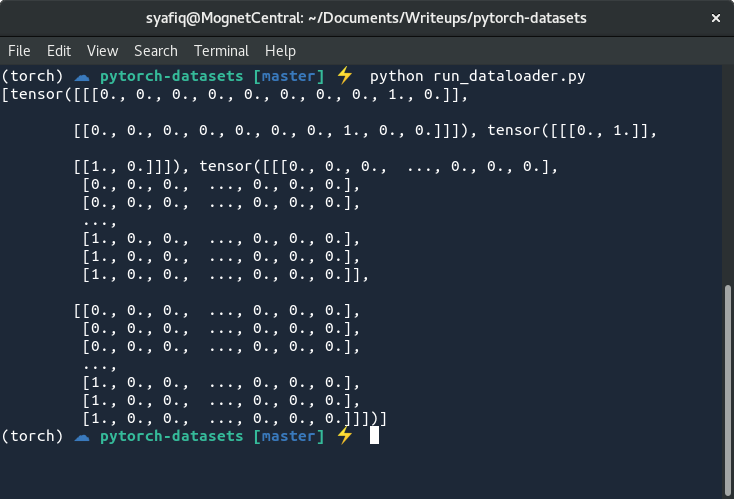
- 堆叠种族张量,独热编码形式表示该张量是十个种族中的某一个种族
- 堆叠性别张量,独热编码形式表示数据集中存在两种性别中的某一种性别
- 堆叠名称张量,最后一个维度应该是
charset的长度,第二个维度是名称长度(固定大小后),第一个维度是批(batch)大小。
数据拆分实用程序
所有这些功能都内置在PyTorch中,真是太棒了。现在可能出现的问题是,如何制作验证甚至测试集,以及如何在不扰乱代码库并尽可能保持DRY的情况下执行验证或测试。测试集的一种方法是为训练数据和测试数据提供不同的data_root,并在运行时保留两个数据集变量(另外还有两个数据加载器),尤其是在训练后立即进行测试的情况下。
如果您想从训练集中创建验证集,那么可以使用PyTorch数据实用程序中的random_split 函数轻松处理这一问题。random_split 函数接受一个数据集和一个划分子集大小的列表,该函数随机拆分数据,以生成更小的Dataset对象,这些对象可立即与DataLoader一起使用。这里有一个例子。
通过使用内置函数轻松拆分自定义PyTorch数据集来创建验证集。
事实上,您可以在任意间隔进行拆分,这对于折叠交叉验证集非常有用。我对这个方法唯一的不满是你不能定义百分比分割,这很烦人。至少子数据集的大小从一开始就明确定义了。另外,请注意,每个数据集都需要单独的DataLoader,这绝对比在循环中管理两个随机排序的数据集和索引更干净。
结束语
希望本文能使您了解PyTorch中Dataset和DataLoader实用程序的功能。与干净的Pythonic API结合使用,它可以使编码变得更加轻松愉快,同时提供一种有效的数据处理方式。我认为PyTorch开发的易用性根深蒂固于他们的开发理念,并且在我的工作中使用PyTorch之后,我从此不再回头使用Keras和TensorFlow。我不得不说我确实错过了Keras模型随附的进度条和fit /predict API,但这是一个小小的挫折,因为最新的带TensorBoard接口的PyTorch带回了熟悉的工作环境。尽管如此,目前,PyTorch是我将来的深度学习项目的首选。
我鼓励以这种方式构建自己的数据集,因为它消除了我以前管理数据时遇到的许多凌乱的编程习惯。在复杂情况下,Dataset 是一个救命稻草。我记得必须管理属于一个样本的数据,但该数据必须来自三个不同的MATLAB矩阵文件,并且需要正确切片,规范化和转置。如果没有Dataset和DataLoader组合,我不知如何进行管理,特别是因为数据量巨大,而且没有简便的方法将所有数据组合成NumPy矩阵且不会导致计算机崩溃。
最后,查看PyTorch数据实用程序文档页面 ,其中包含其他类别和功能,这是一个很小但有价值的实用程序库。您可以在我的GitHub上找到TES数据集的代码,在该代码中,我创建了与数据集同步的PyTorch中的LSTM名称预测变量。让我知道这篇文章是有用的还是不清楚的,以及您将来是否希望获得更多此类内容。
原文链接:https://towardsdatascience.com/building-efficient-custom-datasets-in-pytorch-2563b946fd9f
原创文章,作者:磐石,如若转载,请注明出处:https://panchuang.net/2020/07/17/%e5%9c%a8pytorch%e4%b8%ad%e6%9e%84%e5%bb%ba%e9%ab%98%e6%95%88%e7%9a%84%e8%87%aa%e5%ae%9a%e4%b9%89%e6%95%b0%e6%8d%ae%e9%9b%86/
