
作者|GUEST
编译|VK
来源|Analytics Vidhya
介绍

检验是统计学中最基本的概念之一。不仅在数据科学中,假设检验在各个领域都很重要。想知道怎么做?让我们举个例子。现在有一个lifebuoy沐浴露。
沐浴露厂商声称,它杀死99.9%的细菌。他们怎么能这么说呢?必须有一种测试技术来证明这种说法是正确的。所以假设检验用来证明一个主张或任何假设。
目录
-
假设检验的定义
-
零和替代假设检验
-
简单假设检验和复合假设检验
-
单尾和双尾检验
-
临界区
-
I型和II型错误。
-
统计学意义
-
信心水平
-
重要程度
-
P值
这个博客将这些概念分解成小部分,这样你就能理解它们的动机和用途。当你读完这个博客,假设检验的基础知识就会很清楚了!!
假设检验的定义
假设是关于参数值(均值、方差、中值等)的陈述、假设或主张。
假设是对你周围世界的某件事的有根据的猜测。它应该可以通过实验或观察来测试。
比如说,如果我们说“多尼是有史以来最好的印度队长”,这是一个假设,我们是根据他担任队长期间球队的平均输赢情况做出的。我们可以根据所有的匹配数据来测试这个语句。
零假设和替代假设检验
零假设是在假设为真的前提下,检验假设是否可能被拒绝。类似无罪的概念。我们假定无罪,直到我们有足够的证据证明嫌疑人有罪。
简单地说,我们可以把零假设理解为已经被接受的陈述,例如,天空是蓝色的。我们已经接受这个声明。
用H0表示。
替代假设补充了零假设。它与原假设相反,替代假设和原假设一起覆盖了总体参数的所有可能值。
用H1表示。
让我们用一个例子来理解这一点:
一家肥皂公司声称他们的产品平均杀死99%的细菌。为了检验这家公司的主张,我们将提出零和替代假设。
零假设(H0):平均值等于99%
替代假设(H1):平均值不等于99%。
注意:当我们检验一个假设时,我们假设原假设是真的,直到样本中有足够的证据证明它是假的。在这种情况下,我们拒绝原假设而支持替代假设。
如果样本不能提供足够的证据让我们拒绝零假设,我们不能说零假设是真的,因为它仅仅基于样本数据。零假设成立需要研究整个总体数据。
简单假设检验和复合假设检验
当一个假设指定了参数的精确值时,这是一个简单的假设,如果它指定了一个值的范围,则称为复合假设。例如
-
某电单车公司声称某车型每升平均行驶里程为100公里,这是一个简单假设的案例。
-
一个班学生的平均年龄大于20岁。这是一个复合假设。
单尾和双尾假设检验
如果替代假设在两个方向(小于和大于)给出了在零假设中指定的参数值的替代,则称为双尾检验。
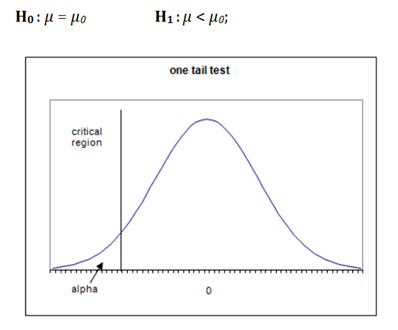
如果替代假设只在一个方向(小于或大于)给出了在零假设中指定的参数值的替代,则称为单尾检验。例如
- H0:平均值等于100
- H1:平均值不等于100
根据H1,平均值可以大于或小于100。这是一个双尾检验的例子
同样,
- H0:平均值>=100
- H1:平均值<100
在这里,平均值不到100。这叫做单尾检验。
拒绝域
拒绝域是样本空间中的拒绝区域,如果计算值在其中,那么我们就拒绝零假设。
让我们用一个例子来理解这一点:
假设你想租一套公寓。你从不同的真实国家网站列出了所有可用的公寓。你的预算是15000卢比/月。你不能再花那么多钱了。你所订的公寓清单的价格从7000/月到30000/月不等。
你从列表中随机选择一个公寓,并假设以下假设:
-
H0:你要租这套公寓。
-
H1:你不会租这套公寓。
现在,既然你的预算是1.5万,你必须拒绝所有高于这个价格的公寓。
在这里所有价格超过15000成为你的拒绝域。如果随机公寓的价格在这个区域,你必须拒绝你的零假设,如果公寓的价格不在这个区域,你就不能拒绝你的零假设。
根据替代假设,拒绝域位于概率分布曲线的一条或两条尾巴上。拒绝域是与概率分布曲线中的截止值相对应的预定义区域。用α表示。
临界值是将支持或拒绝零假设的值分隔开的值,并根据alpha进行计算。
稍后我们将看到更多的例子,我们将清楚地知道如何选择α。
根据另一种假设,拒绝域出现了三种情况:
案例1)这是一个双尾检验。
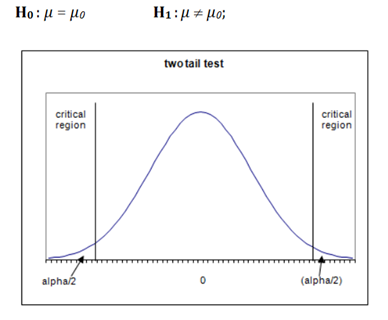
案例2)这种情况也被称为左尾检验。
案例3)这种情况也被称为右尾检验。

I型和II型错误
因此,第一类和第二类错误是假设检验的重要课题之一。让我们把这个话题分解成更小的部分来简化它。
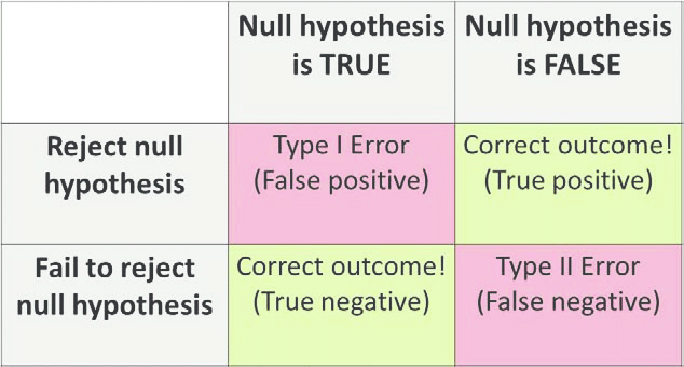
一个假正例(I型错误)——当你拒绝一个真的零假设时。
假负性(II型错误)——当你接受一个错误的零假设时。
-
犯I型错误(假正例)的概率等于临界区α的显著性水平或大小。
α=P[当H0为真时拒绝H0]
-
犯II型错误(假阴性)的概率等于β。
β=P[当H1为真时不拒绝H0]
例子:
这个人因犯有入室盗窃罪而被捕。由法官组成的陪审团必须裁定有罪或无罪。
H0:人是无辜的
H1:人有罪
第一类错误是如果陪审团判定某人有罪[拒绝接受H0],尽管此人是无辜的[H0是真的]。
第二类错误将是当陪审团释放该人[不拒绝H0]虽然该人有罪[H1是真的]。
统计学意义
为了理解这个话题,让我们考虑一个例子:假设有一家糖果厂每天生产500克的糖果。工厂维修后的一天,一名工人声称他们不再生产500克的糖果,可能是少了或多了。
那么,这名工人凭什么宣称这一错误?那么,我们应该在哪里画一条线来决定糖果条重量的变化呢?这一决定/界限在统计学上具有重要意义。
置信水平
顾名思义,我们有多自信:我们在做决定时有多自信。LOC(置信水平)应大于95%。不接受低于95%的置信度。
显著性水平(α)
显著性水平,用最简单的术语来说,就是当事实上是真的时,错误地拒绝零假设的临界概率。这也称为I型错误率。
这是I类错误的概率。它也是拒绝域的大小。
一般来说,在测试中,它是非常低的水平,如0.05(5%)或0.01(1%)。
如果H0在5%的显著性水平上没有被拒绝,那么我们可以说我们的零假设是正确的,有95%的把握。
P值
假设我们在1%的显著性水平上进行假设检验。
H0:平均值<X(我们只是假设一个单尾检验的情况。)
我们得到临界值(基于我们使用的测试类型),发现我们的测试统计值大于临界值。因此,我们必须在这里拒绝零假设,因为它位于拒绝域。
如果零假设在1%时被拒绝,那么可以肯定的是,在更高的显著性水平上,比如5%或10%,它会被拒绝。
如果我们的显著性水平低于1%,那么我们是否也必须拒绝我们的假设呢?
是的,有可能发生上述情况,而“p值”正在发挥作用。
p值是可以拒绝零假设的最小显著性水平。
这就是为什么现在很多测试都给出p值,而且它更受欢迎,因为它给出的信息比临界值更多。
-
对于右尾检验:
p值=P[检验统计量>=检验统计量的观察值]
-
对于左尾检验:
p值=p[检验统计量<=检验统计量的观察值]
-
对于双尾检验:
p值=2*p[检验统计量>=|检验统计量的观察值|]
p值决策
我们比较p值和显著性水平(alpha)对零假设做出决定。
-
如果p值大于alpha,我们不拒绝零假设。
-
如果p值小于alpha,我们拒绝零假设。
原文链接:https://www.analyticsvidhya.com/blog/2020/07/hypothesis-testing-68351/
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
原创文章,作者:磐石,如若转载,请注明出处:https://panchuang.net/2020/09/01/%e5%81%87%e8%ae%be%e6%a3%80%e9%aa%8c%ef%bc%9a%e4%bd%bf%e7%94%a8p%e5%80%bc%e6%9d%a5%e6%8e%a5%e5%8f%97%e6%88%96%e6%8b%92%e7%bb%9d%e4%bd%a0%e7%9a%84%e5%81%87%e8%ae%be/
