
作者|Rahul Agarwal
编译|Flin
来源|towardsdatascience

每当我开始一个新的项目时,我发现自己一次又一次地创建一个深度学习机器。
从安装Anaconda开始,最后为Pytorch和Tensorflow创建不同的环境,这样它们就不会相互干扰。而在这中间,你不可避免地会搞砸,从头开始。这种情况经常发生多次。
这不仅是对时间的巨大浪费,它也是令人恼火的。通过所有的堆栈溢出线程,我们经常想知道究竟出了什么问题。
那么,有没有一种方法可以更有效地做到这一点呢?
在这个博客中,我将尝试在EC2上以最小的努力建立一个深度学习服务器,这样我就可以专注于更重要的事情。
本博客明确地由两部分组成:
- 设置一个预先安装了深度学习库的Amazon EC2机器。
- 使用TMUX和SSH隧道设置Jupyter notebook。
别担心,这不像听起来那么难。只需按照步骤操作,然后单击“下一步”。
设置Amazon EC2计算机
我假设你拥有一个AWS账户,并且可以访问AWS控制台。如果没有,你可能需要注册一个Amazon AWS账户。
- 首先,我们需要转到“Services”选项卡以访问EC2仪表板。
- 在EC2仪表板上,你可以从创建实例开始。
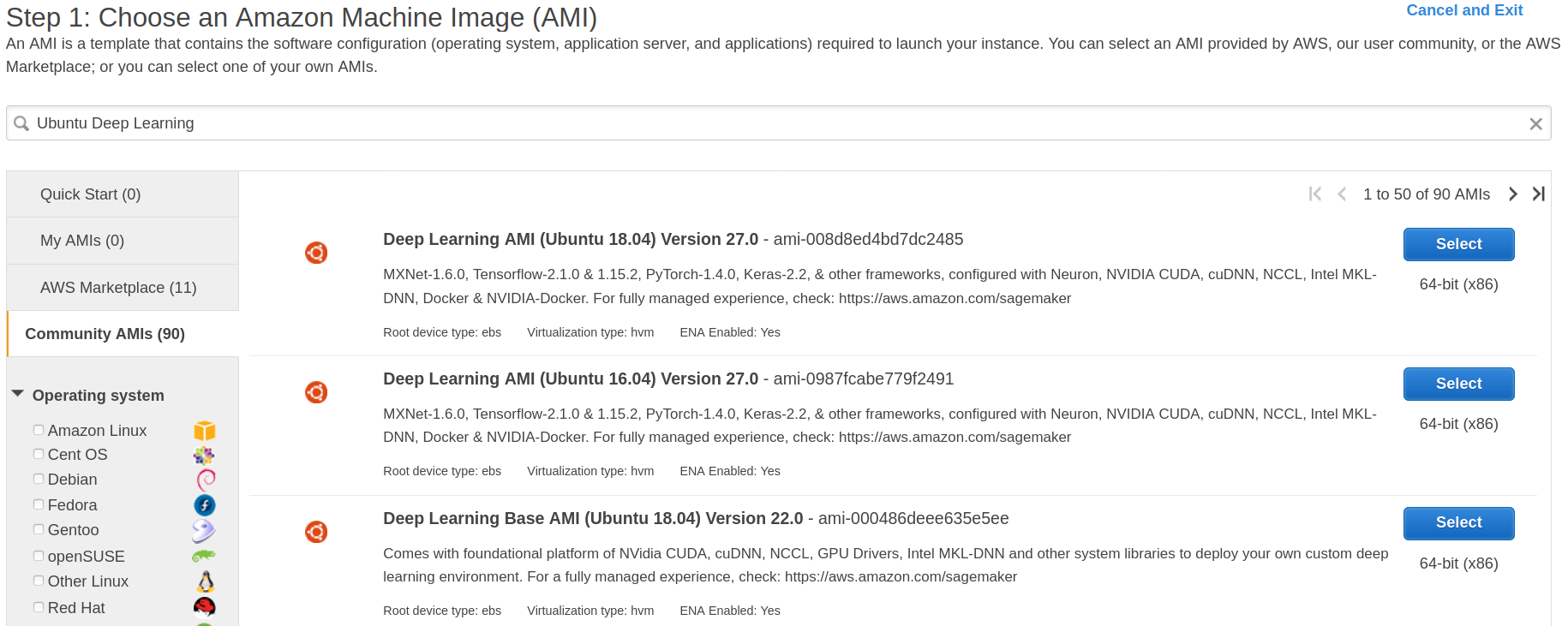
- 亚马逊向社区AMI(亚马逊机器映像)预装了深度学习软件。要访问这些AMI,你需要查看社区AMI,并在“搜索”选项卡中搜索“ Ubuntu深度学习”。你可以选择其他任何Linux风格,但是我发现Ubuntu对于满足我的深度学习需求最为有用。在当前设置中,我将使用深度学习AMI(Ubuntu 18.04)27.0版
-
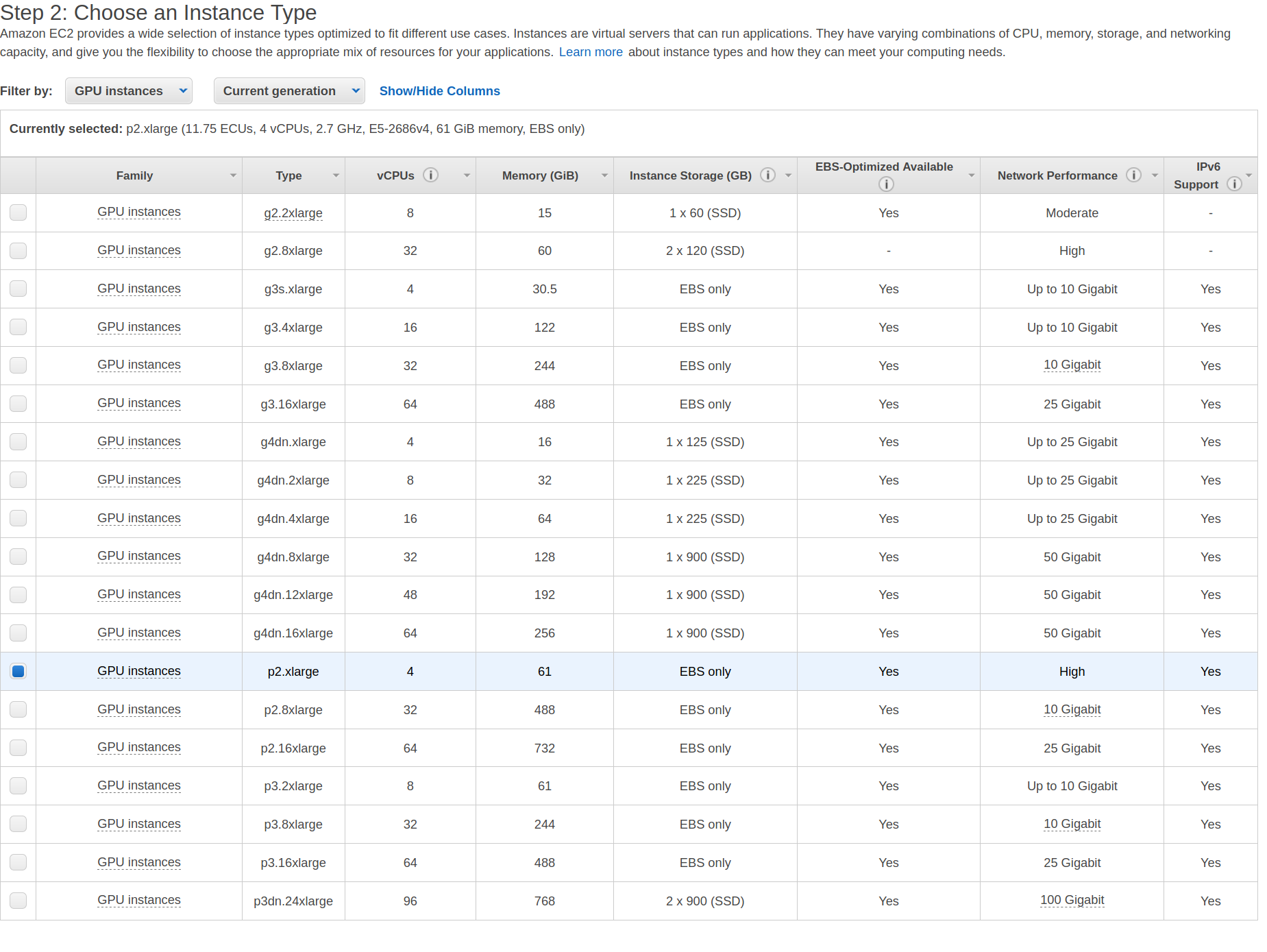
选择AMI后,可以选择“实例类型”。在这里,你可以指定系统中所需的CPU,内存和GPU的数量。亚马逊提供了许多根据个人需求选择的选项。你可以使用“过滤依据”过滤器过滤GPU实例。
在本教程中,我使用了p2.xlarge实例,该实例为NVIDIA K80 GPU提供了2,496个并行处理内核和12GiB的GPU内存。要了解不同的实例类型,你可以查看下方链接中的文档,并查看价格。
- 你可以在第4步中更改连接到机器的存储。如果你不预先添加存储,也可以,因为以后也可以这样做。我将存储空间从90 GB更改为500 GB,因为大多数深度学习需求都需要适当的存储空间。

- 仅此而已,你可以在进入最终审阅实例设置屏幕之后启动实例。单击启动后,你将看到此屏幕。只需在“Key pair name”中输入任何密钥名称,然后单击“Download Key Pair”即可。你的密钥将按照你提供的名称下载到计算机上。对我来说,它被保存为“aws_key.pem”。完成后,你可以单击“Launch Instances”启动实例。
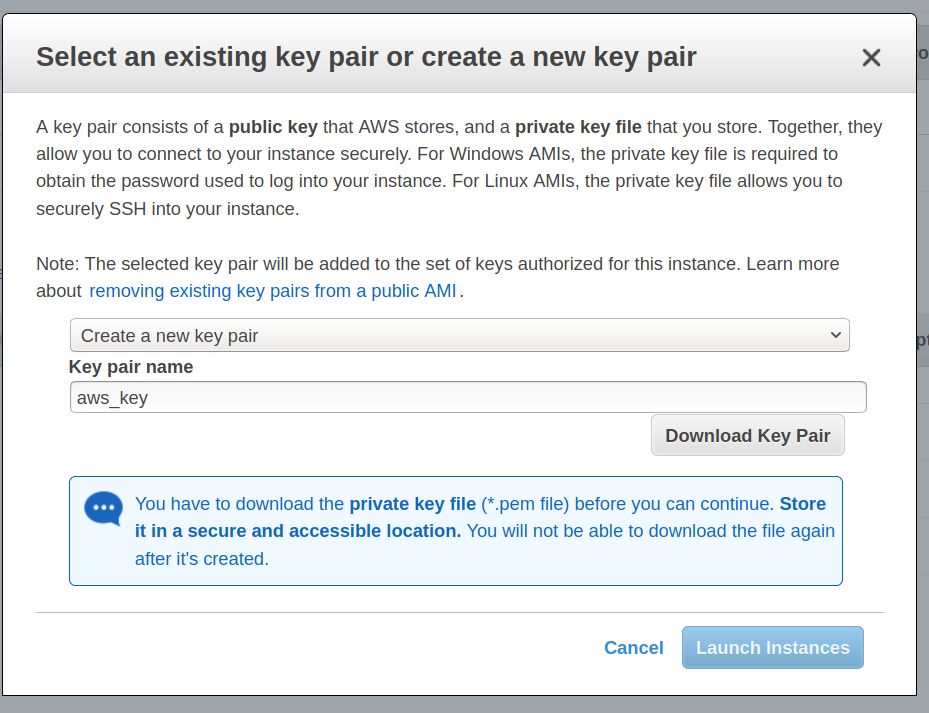
请确保此密钥对的安全,因为每当你要登录实例时都需要这样做。
- 现在,你可以单击下一页上的“View Instances”以查看你的实例。这是你的实例的样子:
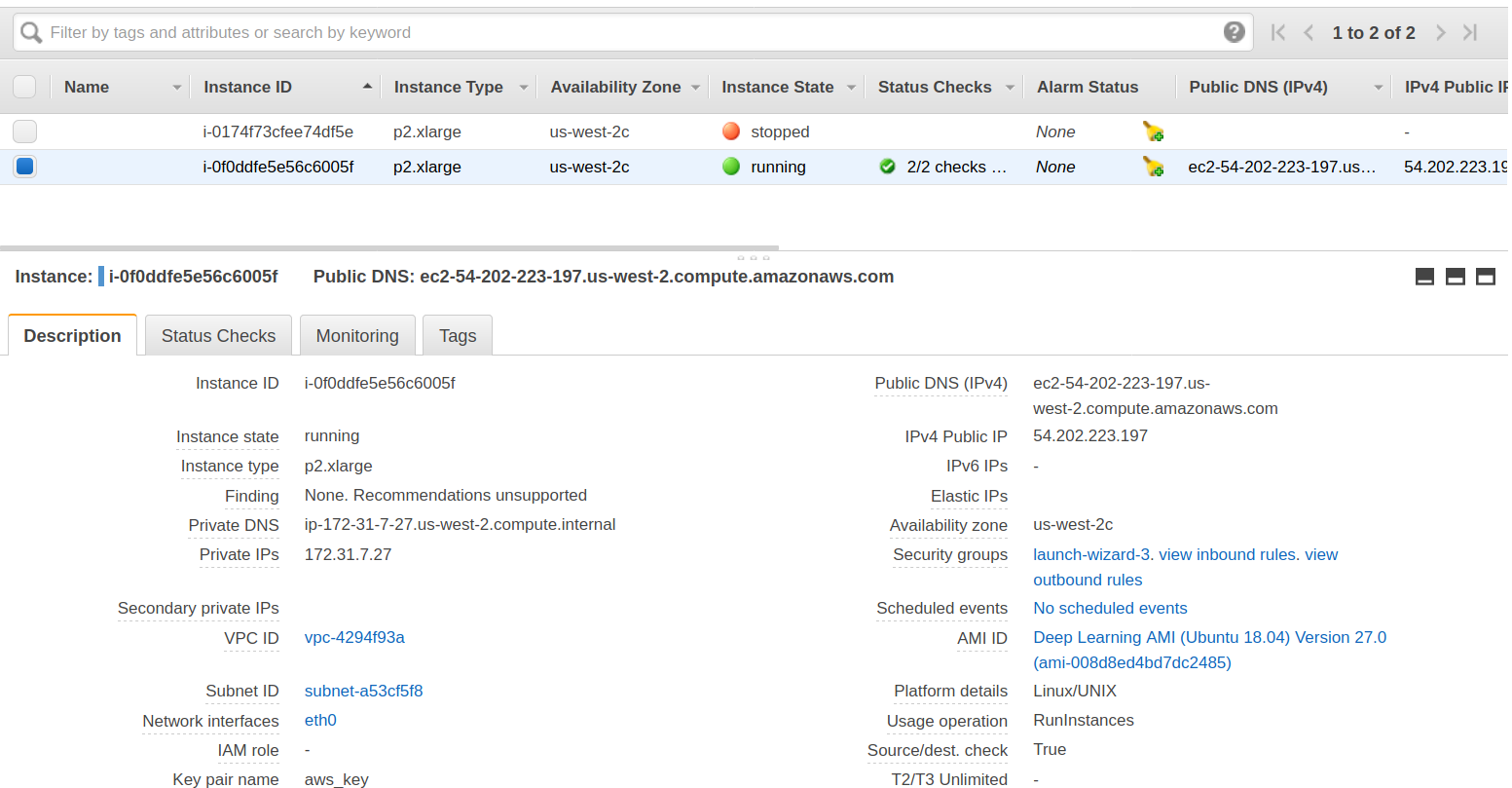
- 要连接到你的实例,只需在本地计算机上打开一个终端窗口,然后浏览到保存密钥对文件并修改一些权限的文件夹。
chmod 400 aws_key.pem完成此操作后,你将可以通过SSH连接到你的实例。SSH命令的格式为:
ssh -i“ aws_key.pem” ubuntu @ <你的PublicDNS(IPv4)>对我来说,命令是:
ssh -i“ aws_key.pem” ubuntu@ec2-54-202-223-197.us-west-2.compute.amazonaws.com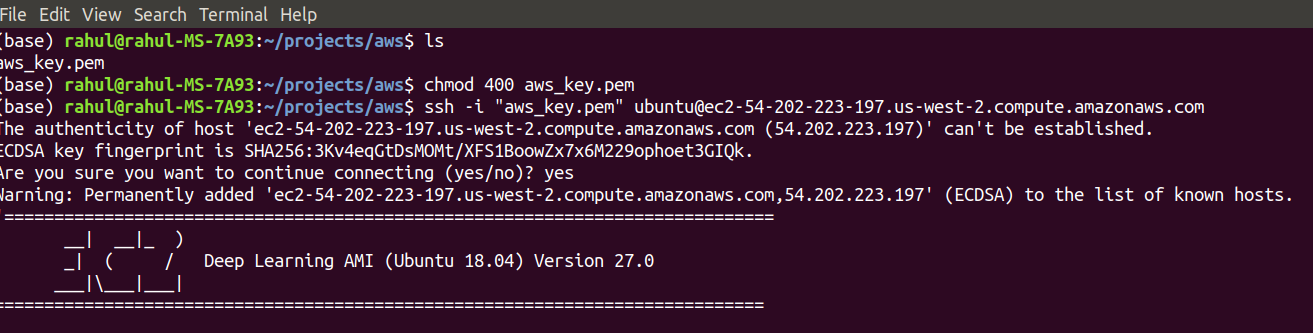
另外,请记住,一旦关闭实例,公用DNS可能会更改。
- 你已经准备好机器并准备就绪。本机包含不同的环境,这些环境具有你可能需要的各种库。这台特定的机器具有MXNet,Tensorflow和Pytorch,以及不同版本的python。最好的事情是,我们已经预先安装了所有这些功能,因此开箱即用。
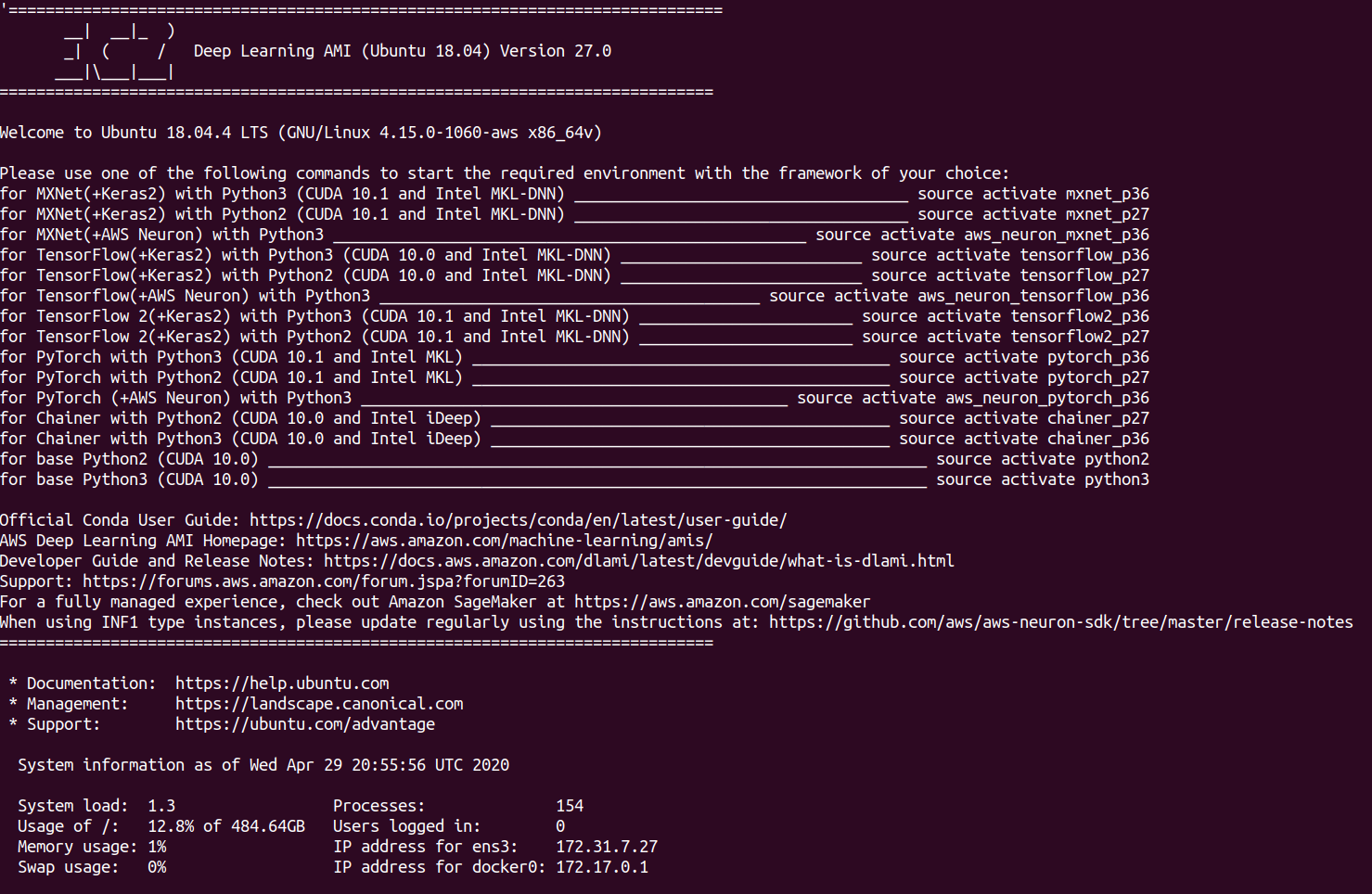
设置Jupyter Notebook
但是,仍然需要使用一些东西才能充分使用计算机。其中之一就是Jupyter Notebook。要在计算机上设置Jupyter Notebook,我建议使用TMUX和隧道。让我们逐步设置Jupyter Notebook。
- 使用TMUX运行Jupyter Notebook
我们将首先使用TMUX在实例上运行Jupyter Notebook。我们主要使用它,以便即使终端连接丢失,我们的笔记本电脑仍然可以运行。
为此,你将需要使用以下命令创建一个新的TMUX会话:
tmux new -s StreamSession完成后,你将看到一个新屏幕,底部带有绿色边框。你可以使用jupyter notebook命令在此计算机上启动Jupyter Notebook 。你将看到类似以下内容:
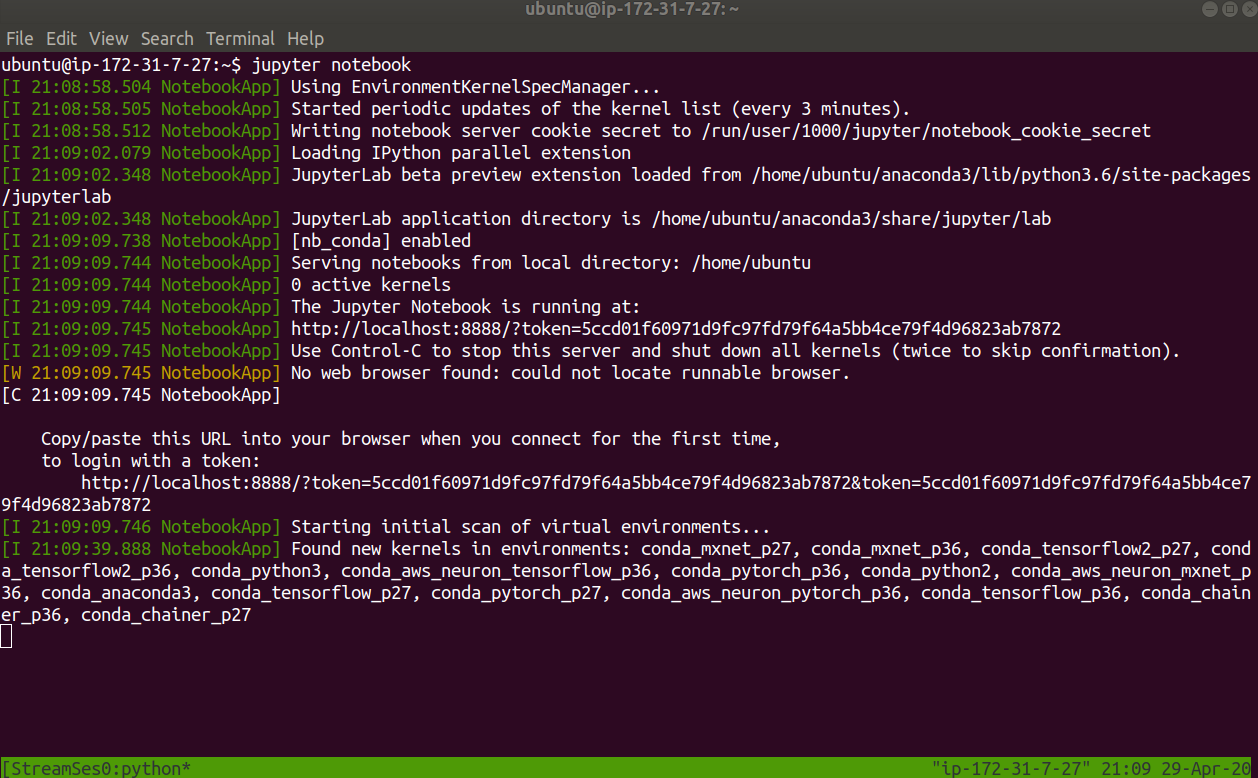
复制登录URL将是有益的,这样以后以后尝试登录到jupyter notebook时,我们将能够获取令牌。就我而言,它是:
http://localhost:8888/?token=5ccd01f60971d9fc97fd79f64a5bb4ce79f4d96823ab7872下一步是分离TMUX会话,以便它在后台继续运行,即使你离开ssh shell。要做到这一点,只需按Ctrl+B,然后按D(按D时不要按Ctrl),你将返回到初始屏幕,显示你已从TMUX会话中分离的消息。

如果需要,可以使用以下方法重新连接到会话:
tmux attach -t StreamSession- SSH隧道访问本地浏览器上的notebook
第二步是进入Amazon实例,以便在本地浏览器上获取Jupyter notebook。如我们所见,Jupyter notebook实际上运行在云实例的本地主机上。我们如何访问它?我们使用SSH隧道。不用担心,这很简单。只需在本地机器终端窗口上使用以下命令:
ssh -i“ aws_key.pem” -L <本地计算机端口>:localhost:8888 ubuntu @ <你的PublicDNS(IPv4)>对于这种情况,我使用了:
ssh -i "aws_key.pem" -L 8001:localhost:8888 ubuntu@ec2-54-202-223-197.us-west-2.compute.amazonaws.com这意味着,如果我在本地计算机浏览器中打开localhost:8001,则可以使用Jupyter Notebook。我当然可以。现在,我们只需输入在先前的步骤之一中已经保存的令牌即可访问notebook。对我来说令牌是5ccd01f60971d9fc97fd79f64a5bb4ce79f4d96823ab7872
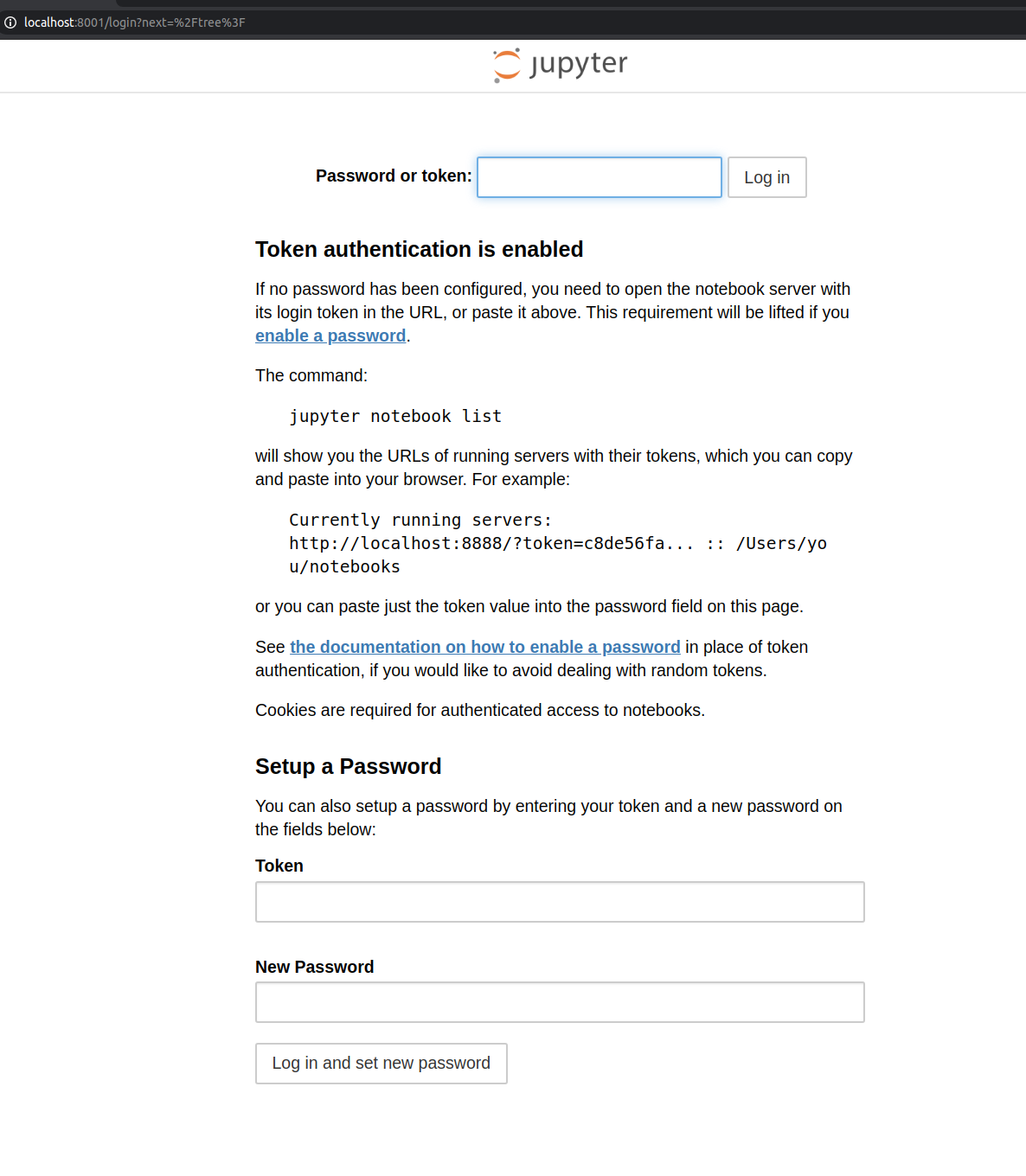
你只需使用你的令牌登录即可。
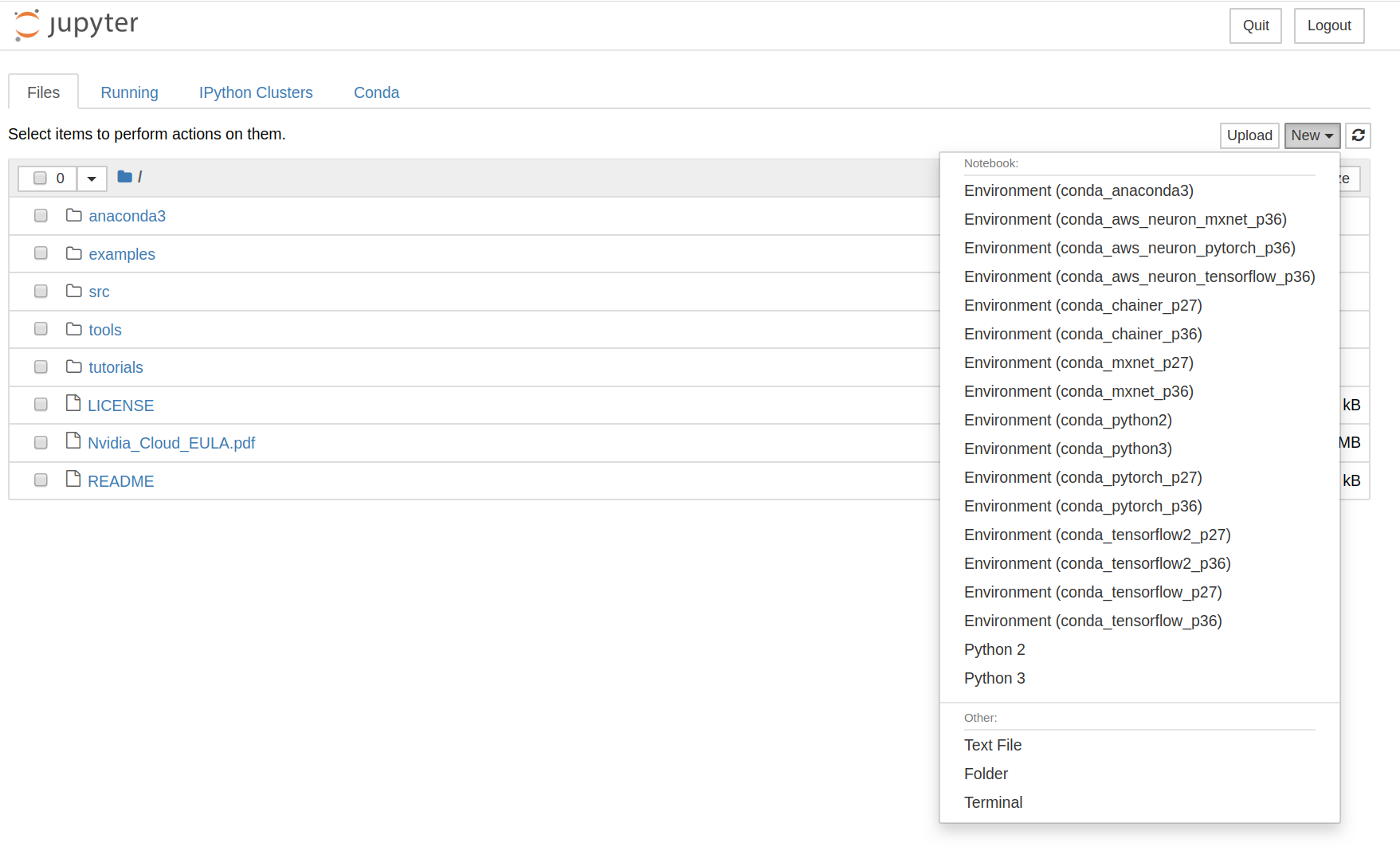
现在,你可以通过选择所需的任何不同环境来选择新项目。你可以来自Tensorflow或Pythorch,也可以两者兼得。notebook不会让你失望的。
故障排除
重新启动计算机后,你可能会遇到NVIDIA图形卡的一些问题。具体来说,就我而言,该nvidia-smi命令停止工作。如果遇到此问题,解决方案是从NVIDIA 网站下载图形驱动程序。
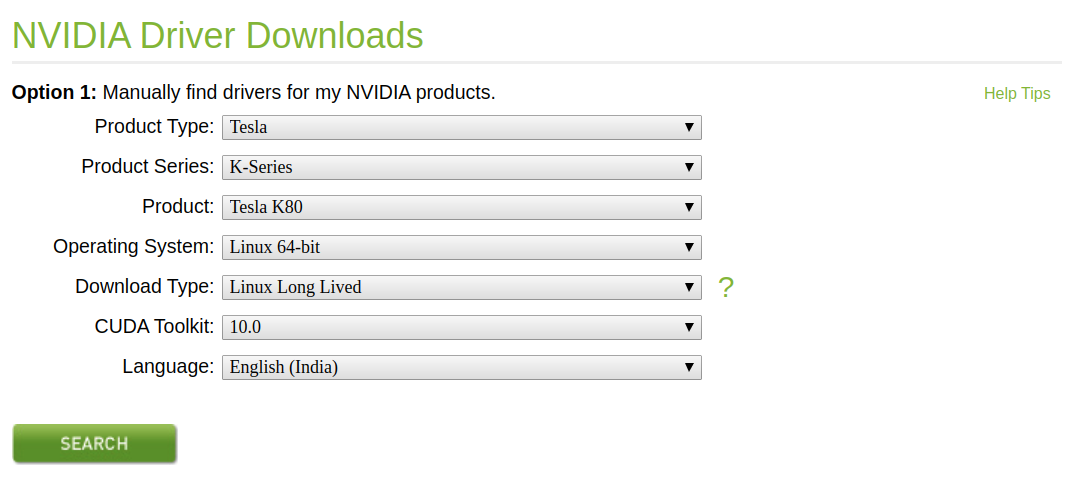
以上是我选择的特定AMI的设置。单击搜索后,你将可以看到下一页:

只需通过右键单击并复制链接地址来复制下载链接。并在计算机上运行以下命令。你可能需要在其中更改链接地址和文件名。
# When nvidia-smi doesnt work:
wget https://www.nvidia.in/content/DriverDownload-March2009/confirmation.php?url=/tesla/410.129/NVIDIA-Linux-x86_64-410.129-diagnostic.run&lang=in&type=Tesla
sudo sh NVIDIA-Linux-x86_64-410.129-diagnostic.run --no-drm --disable-nouveau --dkms --silent --install-libglvnd
modinfo nvidia | head -7
sudo modprobe nvidia停止实例
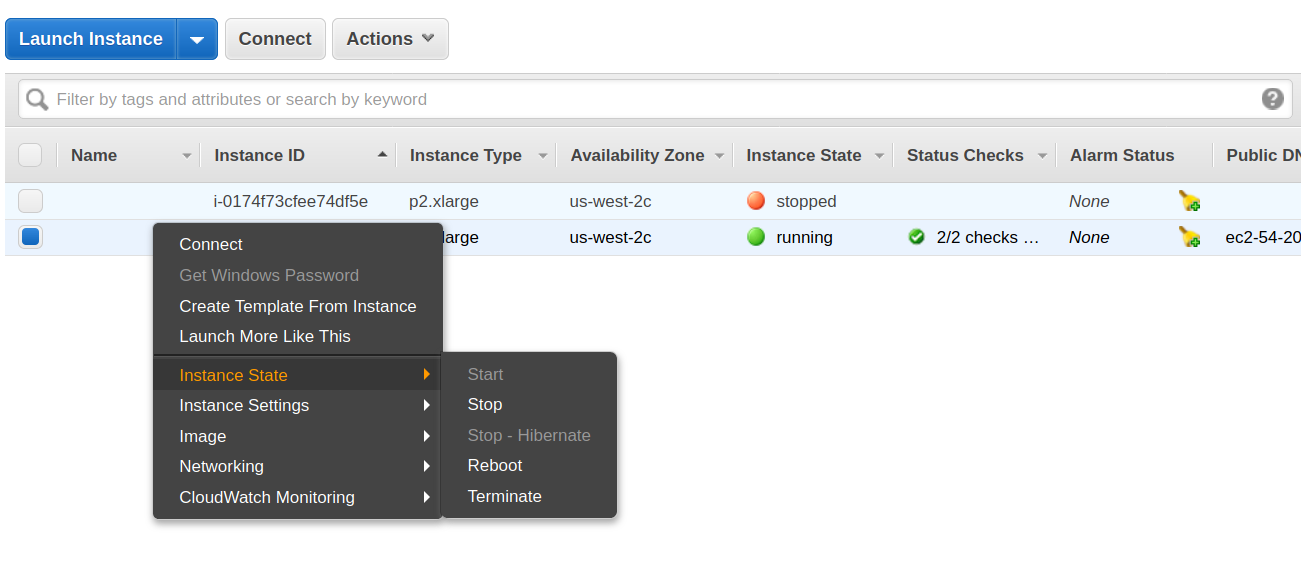
就是这样。你已经掌握并启动了深度学习机器,并且可以随意使用它。请记住,无论何时停止工作,都应停止实例,因此,当你不在实例上工作时,无需向Amazon付费。你可以在实例页面上通过右键单击你的实例来执行此操作。请注意,当你需要再次登录到该计算机时,你可能需要从实例页面重新获得公共DNS(IPv4)地址,因为它可能已更改。
结论
我一直觉得建立深度学习环境非常麻烦。
在此博客中,我们通过使用深度学习社区AMI,TMUX和Jupyter Notebook的隧道技术,在最短的时间内在EC2上设置了新的深度学习服务器。该服务器已预先安装了你在工作中可能需要的所有深度学习库,并且开箱即用。
那你还在等什么?只需在你自己的服务器上开始使用深度学习即可。
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
原创文章,作者:磐石,如若转载,请注明出处:https://panchuang.net/2020/09/01/%e5%9c%a830%e5%88%86%e9%92%9f%e5%86%85%e5%88%9b%e5%bb%ba%e4%bd%a0%e7%9a%84%e6%b7%b1%e5%ba%a6%e5%ad%a6%e4%b9%a0%e6%9c%8d%e5%8a%a1%e5%99%a8/
