
作者|Victor Sim
编译|VK
来源|Towards Data Science
现在假新闻太多了,很难找到准确无误的消息来源。本文旨在利用朴素贝叶斯分类器对真假新闻进行分类。

什么是NaiveBayes分类器
朴素贝叶斯分类器是一种利用贝叶斯定理对数据进行分类的确定性算法。让我们看一个例子:
假设你想预测今天下雨的概率:在过去的几天里,你通过观察天空中的云收集了数据。以下是你的数据表:

在下雨或不下雨的情况下,这个表格表示了某一特征出现的次数。假设出现了灰色云或白色云,我们所拥有的实际上是一个包含下雨概率的表格。
现在有了数据,让我们做一个预测。今天我们看到了灰色的云,没有白云,是雨天还是晴天?要回答这个问题,我们必须使用Bayes定理:
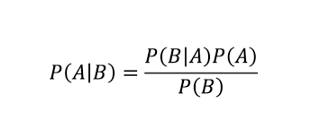
这个定理利用过去的数据做出更好的决定。
如果出现了灰色云,下雨的概率等于以前有灰色云下雨的概率。
根据我们的数据:
P(B | A)(降雨概率|灰色云)=10/11
P(A)(降雨概率)= 11/(50+11) = 11/66 = 1/6
P(B)(灰色云的概率)=1(因为已确认出现了灰色云)
P(A | B)=P(B | A)*P(A)/P(B)
P(A | B)=[(10/11)*(1/6)]/1
P(A | B)=10/66
如果出现了灰色的云,下雨的概率是10/66
项目
通过对naivebayes分类器的简要介绍,让我们用naivebayes分类器来讨论假新闻检测。
考虑到新闻是假的,我们将统计一个词出现在标题中的次数。将其转换为概率,然后计算标题为假的概率,与标题为真的概率相比。
我使用的数据集有21000多个真实新闻实例,23000个假新闻实例。对于一个正常的数据集来说,这可能看起来是不平衡的,但这种不平衡对于计算初始概率是必要的:即标题是假的概率。
代码:
import pandas as pd
import string这是程序的三个依赖项:pandas是读取csv文件,string是字符串操作。
true_text = {}
fake_text = {}
true = pd.read_csv('/Users/XXXXXXXX/Desktop/True.csv')
fake = pd.read_csv('/Users/XXXXXXXX/Desktop/Fake.csv')此脚本用于读取两个数据集,其中包含假新闻和真新闻的实例。
def extract_words(category,dictionary):
for entry in category['title']:
words = entry.split()
for word in words:
lower_word = word.lower()
if word in dictionary:
dictionary[lower_word] += 1
else:
dictionary[lower_word] = 1
return dictionary考虑到标题是假新闻,这个脚本计算一个单词出现的次数,并在其进入词典的条目中添加一个计数,计算每个单词出现的次数。
def count_to_prob(dictionary,length):
for term in dictionary:
dictionary[term] = dictionary[term]/length
return dictionary此函数通过计算假新闻标题或真实新闻标题的总字数将数字转换为概率。
def calculate_probability(dictionary,X,initial):
X.translate(str.maketrans('', '', string.punctuation))
X = X.lower()
split = X.split()
probability = initial
for term in split:
if term in dictionary:
probability *= dictionary[term]
print(term,dictionary[term])
return probability此函数将相关概率相乘,以计算标题的“分数”。为了做出预测,在使用假新闻和真新闻词典时比较得分。如果假新闻字典返回更高的分数,则模型预测标题为假新闻。
true_text = extract_words(true,true_text)
fake_text = extract_words(fake,fake_text)
true_count = count_total(true_text)
fake_count = count_total(fake_text)
true_text = count_to_prob(true_text,true_count)
fake_text = count_to_prob(fake_text,fake_count)
total_count = true_count + fake_count
fake_initial = fake_count/total_count
true_initial = true_count/total_count这个脚本使用上述所有函数为每个单词创建一个概率字典,以便稍后计算标题的“分数”。
X = 'Hillary Clinton eats Donald Trump'
calculate_probability(fake_text,X,1)>calculate_probability(true_text,X,1)最后一个脚本评估了标题:“Hillary Clinton eats Donald Trump”,以测试模型。
True模型输出的结果是真实的,因为标题显然是假新闻。
你可以改进我的程序
我创建了这个程序作为一个框架,以便其他人可以改进它。你可以考虑以下几点:
- 考虑短语和单词
一个词本身没有意义,但是一个短语可以让我们更深入地了解新闻是否是假的
- 通过网络抓取获得更大的数据集
网上有很多真假新闻的来源,你只要找到它就可以了。
原文链接:https://towardsdatascience.com/using-bayesian-classifiers-to-detect-fake-news-3022c8255fba
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
原创文章,作者:磐石,如若转载,请注明出处:https://panchuang.net/2020/10/19/%e5%88%a9%e7%94%a8%e8%b4%9d%e5%8f%b6%e6%96%af%e5%88%86%e7%b1%bb%e5%99%a8%e6%a3%80%e6%b5%8b%e8%99%9a%e5%81%87%e6%96%b0%e9%97%bb/
