
作者|Jaime Duránx
编译|Flin
来源|medium

目前我正在研究一个涉及面部分类的计算机视觉问题。这通常意味着应用深度学习,因此在将图像注入到我们的神经网络之前需要一个特殊的预处理阶段。
为了提高我们的模型精度,这是一项非常重要的任务,通过以下几个简单的步骤可以很容易地完成。对于本文,我们可以使用OpenCV:一个高度优化的计算机视觉开源库,在C++、java和Python中可用。
这是一篇简短的文章,包含了一些基本的指导原则、示例和代码,你可能需要将它们应用到每个面部分类或识别问题上。
注意:本文中使用的所有静态图像都来自 https://imgflip.com/memetemplates
图片载入
我们将使用imread()函数加载图像,指定文件的路径和mode。第二个参数对于动态运行基本通道和深度转换非常重要。
img = cv2.imread('path/image.jpg', cv2.IMREAD_COLOR)要查看图像,我们有imshow()函数:
cv2.imshow(img)
如果你写的是类型(img),你会看到尺寸是(height, weight, channels)。
我们的彩色图像有3个通道:蓝色,绿色和红色(在OpenCV中按这个顺序)。

我们可以轻松查看单个通道:
# Example for green channel
img[:, :, 0]; img[:, :, 2]; cv2.imshow(img)灰度版本
为了避免在面部图像分类中分心,使用黑白图片是个好主意(也可能不是!)你可以两者都试试)。为了得到灰度版本,我们只需要在图像加载函数中指定,将适当的值作为第二个参数传递:
img = cv2.imread('path/image.jpg', cv2.IMREAD_GRAYSCALE)
现在我们的图像有了一个单独的通道!
人脸和眼睛检测
当处理面部分类问题时,我们可能想要做面部检测,以验证(是否有脸?),裁剪和拉直我们的图像。我们将使用OpenCV中包含的基于Haar特性的级联分类器进行对象检测。(https://docs.opencv.org/2.4/modules/objdetect/doc/cascade_classification.html)
首先,我们选择预先训练的人脸和眼睛检测分类器。有一个可用的XML文件列表,我们可以使用此列表:
1)对于人脸检测,OpenCV提供以下(从最宽松的先验到最严格的先验):
-
haarcascade_frontalface_default.xml
-
haarcascade_frontalface_alt.xml
-
haarcascade_frontalface_alt2.xml
-
haarcascade_frontalface_alt_tree.xml
2) 对于眼睛检测,我们可以选择两种方法:
-
haarcascade_eye.xml
-
haarcascade_eye_tree_eyegasses.xml
我们以这种方式加载预先训练的分类器:
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + ‘haarcascade_frontalface_default.xml’)
eyes_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + ‘haarcascade_eye.xml’)你可以测试几种组合。记住,在所有情况下,它们中没有一个是最优的(如果第一个分类器失败,你可以尝试第二个分类器,或者甚至尝试所有分类器)。
对于人脸检测,我们使用以下代码:
faces_detected = face_cascade.detectMultiScale(img, scaleFactor=1.1, minNeighbors=5)结果是一个数组,包含所有检测到的人脸。我们可以很容易地画出矩形:
(x, y, w, h) = faces_detected[0]
cv2.rectangle(img, (x, y), (x+w, y+h), (0, 255, 0), 1);
cv2.imshow(img)
对于眼睛,我们以类似的方式进行搜索,但将搜索范围缩小到面部矩形:
eyes = eyes_cascade.detectMultiScale(img[y:y+h, x:x+w])
for (ex, ey, ew, eh) in eyes:
cv2.rectangle(img, (x+ex, y+ey), (x+ex+ew, y+ey+eh),
(255, 255, 255), 1)成啦!

虽然这是预期的结果,但我们会遇到很多其他方面的问题。很多时候,我们没有正面和清晰的人的脸,甚至……
没有眼睛:

眼睛是被白色包围的黑色污点:
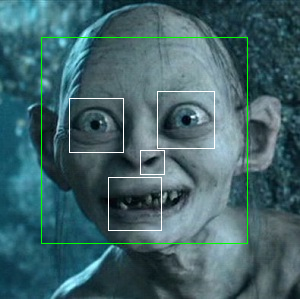
此处有4只眼,仅检测到3只眼:

拉直脸部
通过计算两只眼睛之间的角度,我们可以拉直脸部图像(这很容易)。计算后,我们仅需两个步骤即可旋转图像:
rows, cols = img.shape[:2]
M = cv2.getRotationMatrix2D((cols/2, rows/2), <angle>, 1)
img_rotated = cv2.warpAffine(face_orig, M, (cols,rows))
裁剪脸部
为了帮助我们的神经网络完成面部分类任务,最好去掉背景、衣服或配饰等外部干扰信息。在这种情况下,裁剪脸部是一个很好的选择。
我们需要做的第一件事是从拉直的图像中再次得到人脸矩形。然后我们需要做一个决定:我们可以按原样裁剪矩形区域,或者添加一个额外的填充,这样我们可以获得更多的空间。
这取决于要解决的具体问题(按年龄、性别、种族等分类);也许你想要更多的头发;也许不需要。

最后,裁剪(p表示填充):
cv2.imwrite('crop.jpg', img_rotated[y-p+1:y+h+p, x-p+1:x+w+p])看!这张脸是孤立的,几乎可以进行深度学习了

图像缩放
神经网络需要所有的输入图像具有相同的形状和大小,因为GPU在同一时间对一批图像应用相同的指令,以达到超级快的速度。我们可以动态地调整它们的大小,但这可能不是一个好主意,因为在训练期间将对每个文件执行多个转换。
因此,如果我们的数据集有很多图像,我们应该考虑在训练阶段之前实现批量调整大小的过程。
在OpenCV中,我们可以使用resize()函数执行向下缩放和向上缩放,有几种可用的插值方法。指定最终尺寸的例子:
cv2.resize(img, (<width>, <height>), interpolation=cv2.INTER_LINEAR)为了缩小图像,OpenCV建议使用INTER_AREA插值,而要放大图像,可以使用INTER_CUBIC(慢)或INTER_LINEAR(快,效果仍然不错)。
最后是质量和时间之间的权衡。
我做了一个快速的升级比较:

前两幅图像的质量似乎更高(但你可以观察到一些压缩伪像)。
线性方法的结果明显更平滑并且噪点更少。
最后一个是像素化的。
归一化
我们可以使用normalize()函数应用视觉归一化,以修复非常暗/亮的图片(甚至可以修复低对比度)。
该归一化类型(https://docs.opencv.org/3.4/d2/de8/group__core__array.html#gad12cefbcb5291cf958a85b4b67b6149f) 在函数参数中指定:
norm_img = np.zeros((300, 300))
norm_img = cv2.normalize(img, norm_img, 0, 255, cv2.NORM_MINMAX)例子:


当使用图像作为深度卷积神经网络的输入时,不需要应用这种归一化。
在实践中,我们将对每个通道进行适当的归一化,比如减去平均值,然后除以像素级的标准差(因此我们得到平均值0和偏差1)。如果我们使用迁移学习,最好的方法总是使用预先训练的模型统计数据。
结论
在处理人脸分类/识别问题时,如果输入的图像不是护照图片,则检测和分离出人脸是一项常见的任务。
OpenCV是一个很好的图像预处理库,但不仅仅如此。它也是一个强大的工具,为许多计算机视觉应用…



来看文档吧!
希望你喜欢这篇文章!

欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
原创文章,作者:磐石,如若转载,请注明出处:https://panchuang.net/2020/10/19/%e5%9f%ba%e4%ba%8eopencv%e5%af%b9%e7%a5%9e%e7%bb%8f%e7%bd%91%e7%bb%9c%e9%a2%84%e5%a4%84%e7%90%86%e4%ba%ba%e8%84%b8%e5%9b%be%e5%83%8f%e7%9a%84%e5%bf%ab%e9%80%9f%e6%8c%87%e5%8d%97/
