
作者|Jacob Solawetz, Joseph Nelson
编译|Flin
来源|blog

YOLO系列的目标检测模型随着YOLOv5的引入变得越来越强大。在这篇文章中,我们将介绍如何训练YOLOv5为你的定制用例识别定制对象。
非常感谢Ultralytics将此存储库组合在一起。我们相信,与干净的数据管理工具相结合,任何希望在其项目中部署计算机视觉项目的开发人员都可以轻松地使用此技术。
我们使用公共血细胞检测数据集,你可以自己导出。你也可以在自己的自定义数据上使用本教程。
为了训练探测器,我们采取以下步骤:
-
安装YOLOv5依赖项
-
下载自定义YOLOv5对象检测数据
-
定义YOLOv5模型配置和架构
-
训练一个定制的YOLOv5探测器
-
评估YOLOv5性能
-
可视化YOLOv5训练数据
-
对测试图像运行YOLOv5推断
-
导出保存的YOLOv5权重以供将来推断
YOLOv5:有什么新鲜的吗?
就在两个月前,我们对googlebrain引入EfficientDet感到非常兴奋,并写了一些关于EfficientDet的博客文章。我们认为这个模型可能会超越YOLO家族在实时目标探测领域的突出地位——事实证明我们错了。
三周内,YOLOv4在Darknet框架下发布,我们还写了更多关于分解YOLOv4研究的文章。
在写这篇文章之前几个小时,YOLOv5已经发布,我们发现它非常清晰明了。
YOLOv5是在Ultralytics-Pythorch框架中编写的,使用起来非常直观,推理速度非常快。事实上,我们和许多人经常将YOLOv3和YOLOv4 Darknet权重转换为Ultralytics PyTorch权重,以便使用更轻的库更快地进行推理。
YOLOv5比YOLOv4表现更好吗?我们很快会向你介绍,你可能对YOLOv5和YOLOv4有了初步的猜测。
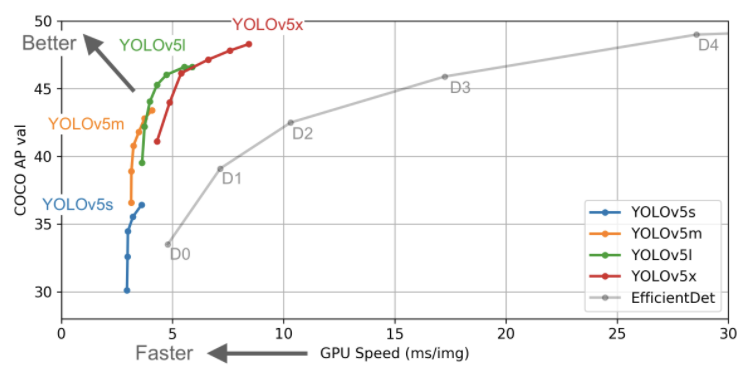
YOLOv5与EfficientDet的性能对比
YOLOv4显然没有在YOLOv5存储库中进行评估。也就是说,YOLOv5更易于使用,而且它在我们最初运行的定制数据上表现非常出色。
我们建议你在 YOLOv5 Colab Notebook 中同时进行接下来的操作。
安装YOLOv5环境
从YOLOv5开始,我们首先克隆YOLOv5存储库并安装依赖项。这将设置我们的编程环境,准备好运行对象检测训练和推理命令。
!git clone https://github.com/ultralytics/yolov5 # clone repo
!pip install -U -r yolov5/requirements.txt # install dependencies
%cd /content/yolov5
然后,我们可以看看我们的训练环境免费提供给我们的谷歌Colab。
import torch
from IPython.display import Image # for displaying images
from utils.google_utils import gdrive_download # for downloading models/datasets
print('torch %s %s' % (torch.__version__, torch.cuda.get_device_properties(0) if torch.cuda.is_available() else 'CPU'))很可能你会从谷歌Colab收到一个 Tesla P100 GPU。以下是我收到的:
torch 1.5.0+cu101 _CudaDeviceProperties(name='Tesla P100-PCIE-16GB', major=6, minor=0, total_memory=16280MB, multi_processor_count=56)GPU可以让我们加快训练时间。Colab也很好,因为它预装了torch和cuda。如果你尝试在本地上使用本教程,可能需要执行其他步骤来设置YOLOv5。
下载自定义YOLOv5对象检测数据
在本教程中,我们将从Roboflow下载YOLOv5格式的自定义对象检测数据。在本教程中,我们使用公共血细胞检测数据集训练YOLOv5检测血流中的细胞。你可以使用公共血细胞数据集或上传你自己的数据集。
- Roboflow:https://roboflow.ai/
- 公共血细胞数据集:https://public.roboflow.ai/object-detection/bccd
关于标记工具的快速说明
如果你有未标记的图像,则首先需要标记它们。对于免费的开源标签工具,我们推荐 LabelImg入门 或 CVAT注释工具入门 的指南。尝试标记约50幅图像再继续本教程。要在以后提高模型的性能,你将需要添加更多标签。
- https://blog.roboflow.ai/getting-started-with-labelimg-for-labeling-object-detection-data/
- https://blog.roboflow.ai/getting-started-with-cvat/
一旦你标记了数据,要将数据移动到Roboflow中,请创建一个免费帐户,然后你可以以任何格式拖动数据集:(VOC XML、COCO JSON、TensorFlow对象检测CSV等)。
上传后,你可以选择预处理和增强步骤:
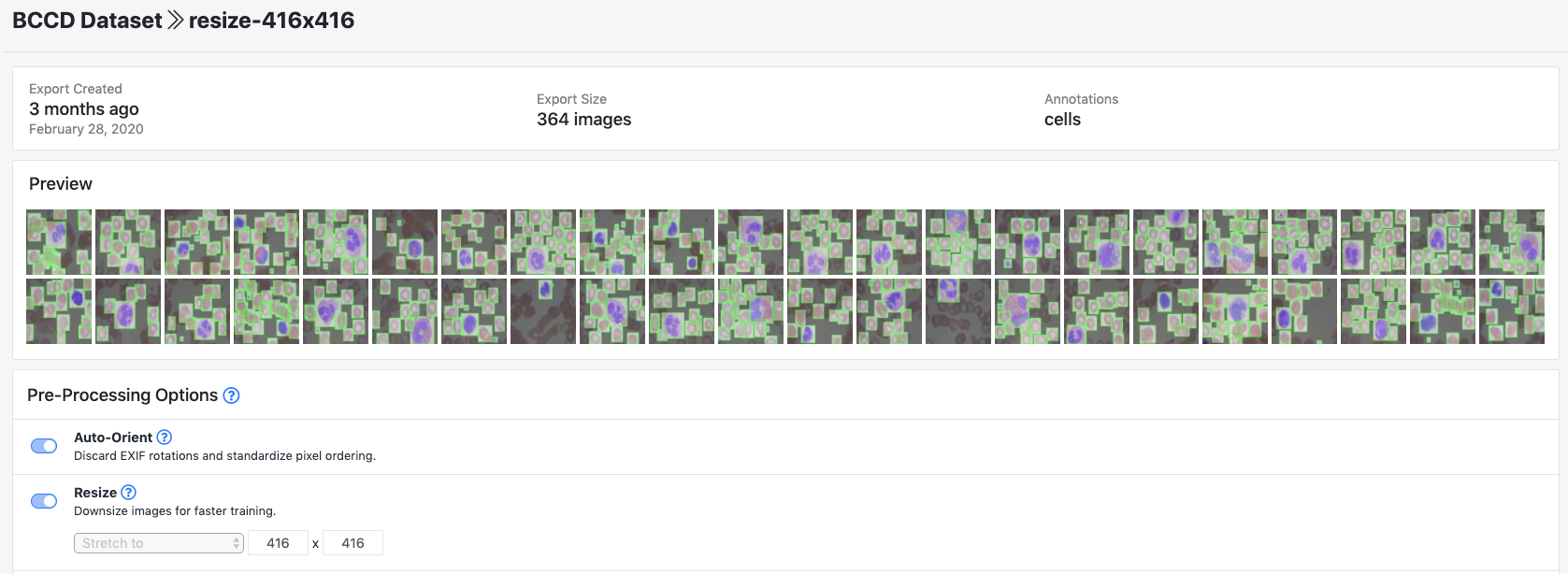
为BCCD示例数据集选择的设置
然后,单击 Generate 和 Download,你将能够选择YOLOv5 Pythorch格式。
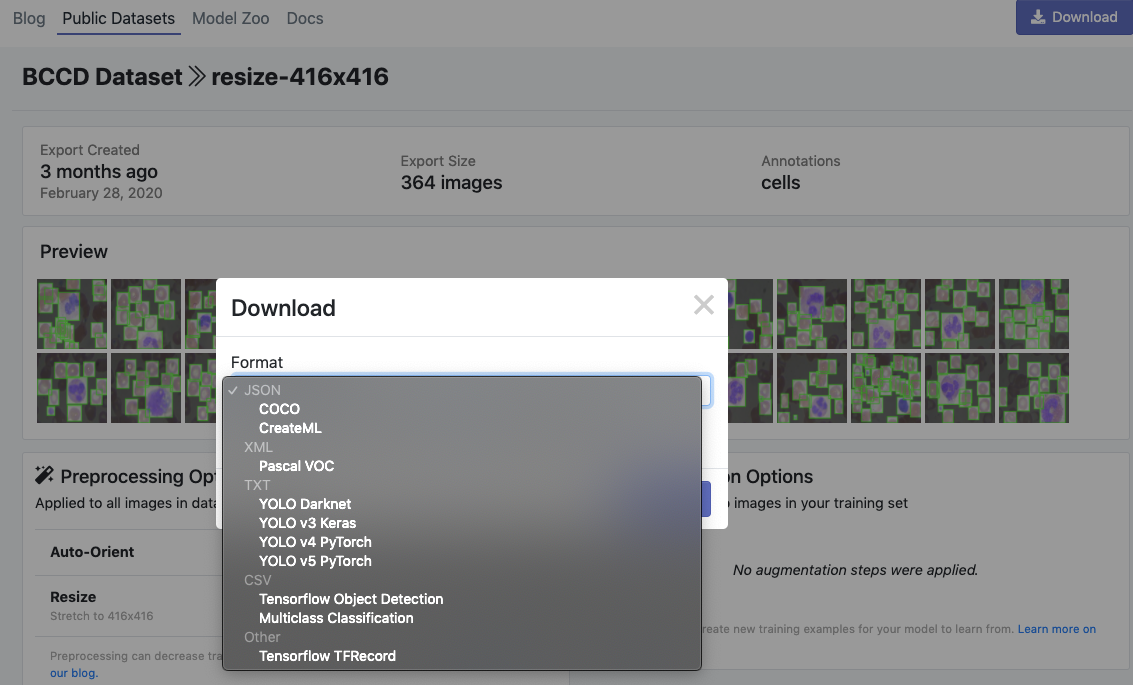
选择“YOLO v5 Pythorch”
当出现提示时,一定要选择“Show Code Snippet”。这将输出一个下载curl脚本,这样你就可以轻松地将数据以正确的格式移植到Colab中。
curl -L "https://public.roboflow.ai/ds/YOUR-LINK-HERE" > roboflow.zip; unzip roboflow.zip; rm roboflow.zip正在Colab中下载…
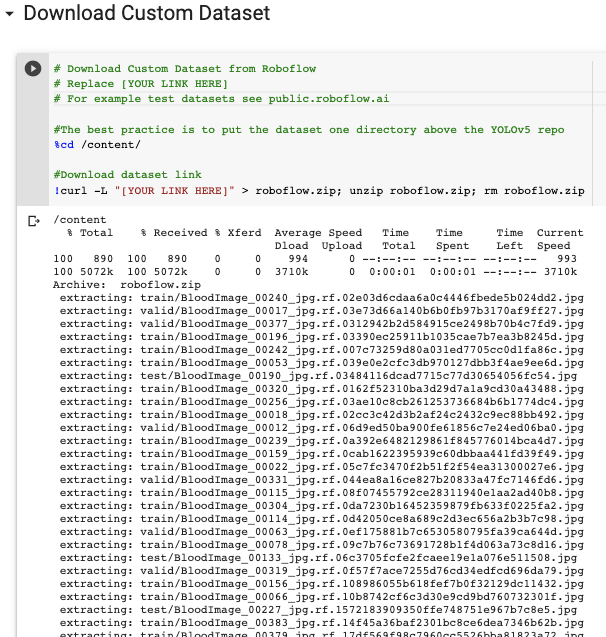
下载YOLOv5格式的自定义对象数据集
导出将创建一个名为data.yaml的YOLOv5.yaml文件,指定YOLOv5 images文件夹、YOLOv5 labels文件夹的位置以及自定义类的信息。
定义YOLOv5模型配置和架构
接下来,我们为我们的定制对象检测器编写一个模型配置文件。在本教程中,我们选择了最小、最快的YOLOv5基本模型。你可以从其他YOLOv5模型中选择,包括:
- YOLOv5s
- YOLOv5m
- YOLOv5l
- YOLOv5x
你也可以在此步骤中编辑网络结构,但一般不需要这样做。以下是YOLOv5模型配置文件,我们将其命名为custom_yolov5s.yaml:
nc: 3
depth_multiple: 0.33
width_multiple: 0.50
anchors:
- [10,13, 16,30, 33,23]
- [30,61, 62,45, 59,119]
- [116,90, 156,198, 373,326]
backbone:
[[-1, 1, Focus, [64, 3]],
[-1, 1, Conv, [128, 3, 2]],
[-1, 3, Bottleneck, [128]],
[-1, 1, Conv, [256, 3, 2]],
[-1, 9, BottleneckCSP, [256]],
[-1, 1, Conv, [512, 3, 2]],
[-1, 9, BottleneckCSP, [512]],
[-1, 1, Conv, [1024, 3, 2]],
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 6, BottleneckCSP, [1024]],
]
head:
[[-1, 3, BottleneckCSP, [1024, False]],
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1, 0]],
[-2, 1, nn.Upsample, [None, 2, "nearest"]],
[[-1, 6], 1, Concat, [1]],
[-1, 1, Conv, [512, 1, 1]],
[-1, 3, BottleneckCSP, [512, False]],
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1, 0]],
[-2, 1, nn.Upsample, [None, 2, "nearest"]],
[[-1, 4], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]],
[-1, 3, BottleneckCSP, [256, False]],
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1, 0]],
[[], 1, Detect, [nc, anchors]],
]训练定制YOLOv5探测器
我们的data.yaml和custom_yolov5s.yaml文件准备好了,我们准备好训练了!
为了开始训练,我们使用以下选项运行训练命令:
-
img:定义输入图像大小
-
batch:确定批次大小
-
epochs:定义训练时间段的数量。(注:通常,3000+很常见!)
-
data:设置yaml文件的路径
-
cfg:指定我们的模型配置
-
weights:指定权重的自定义路径。(注意:你可以从Ultralytics Google Drive文件夹下载权重)
-
name:结果名称
-
nosave:只保存最后的检查点
-
cache:缓存图像以加快训练速度
运行训练命令:
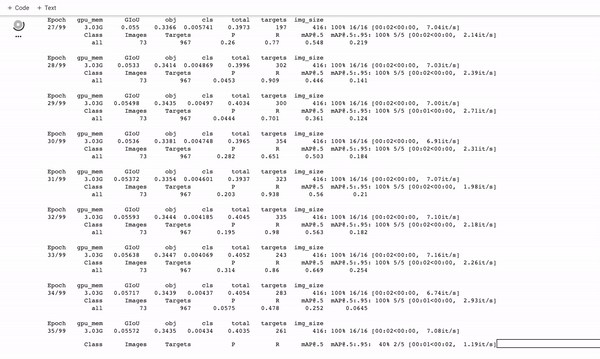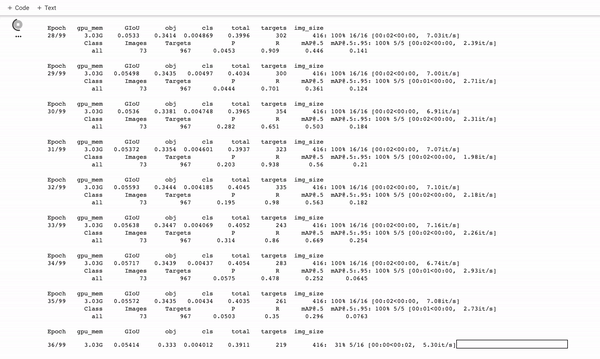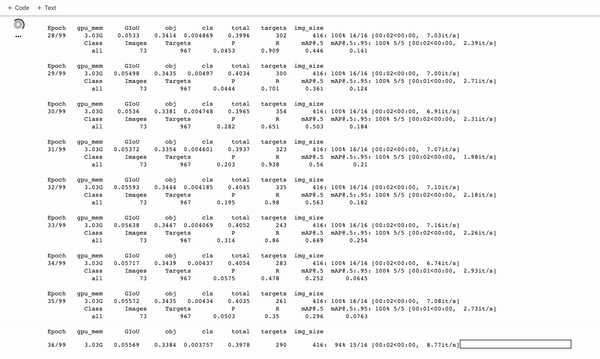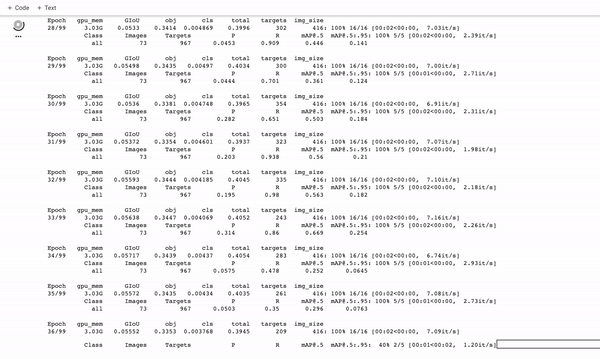
训练定制的YOLOv5探测器。它训练得很快!
在训练期间,你想看 mAP@0.5 来了解你的探测器是如何运行的,请参阅这篇文章。
评估定制YOLOv5探测器性能
现在我们已经完成了训练,我们可以通过查看验证指标来评估训练过程的执行情况。训练脚本将删除tensorboard日志。我们将其可视化:
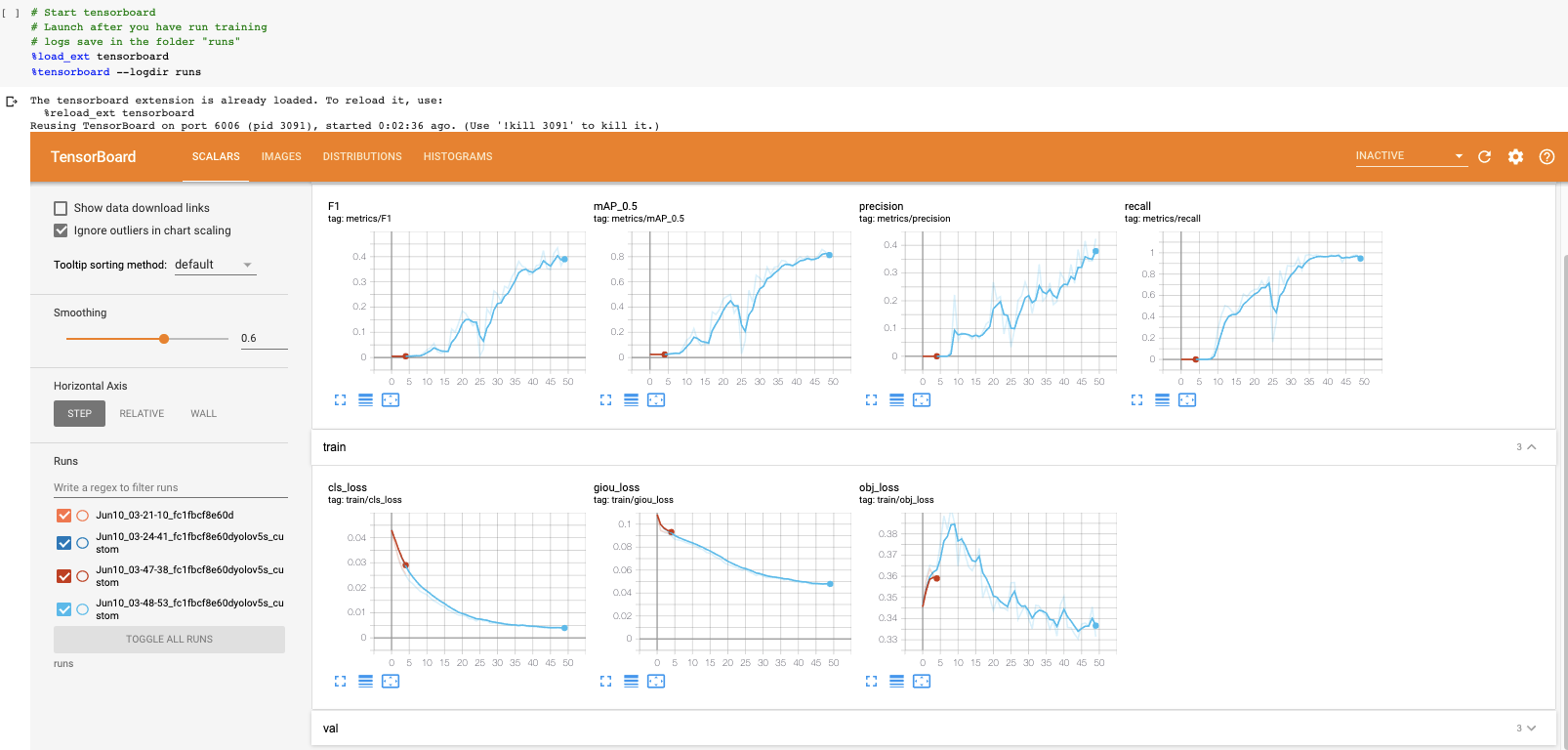
在我们的自定义数据集上可视化tensorboard结果
如果你因为一些原因不能把张量板可视化,结果也可以用utils.plot_result来绘制并保存为result.png。
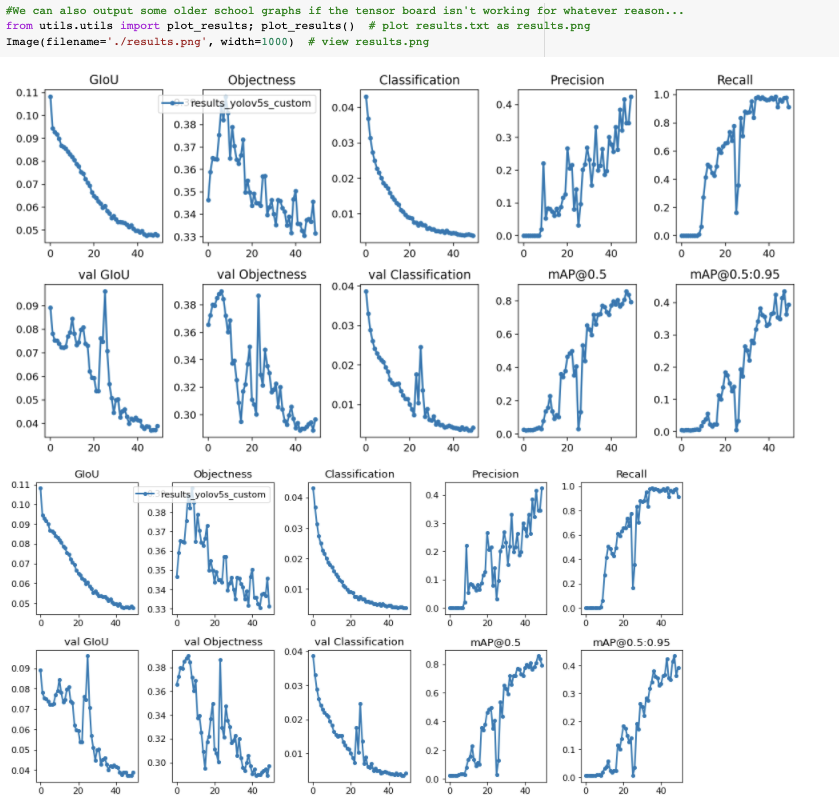
我早早就停止了训练。你需要在验证映射达到其最高点处获取经过训练的模型权重。
可视化YOLOv5训练数据
在训练过程中,YOLOv5训练管道通过增强创建成批的训练数据。我们可以可视化训练数据真实性和增强训练数据。
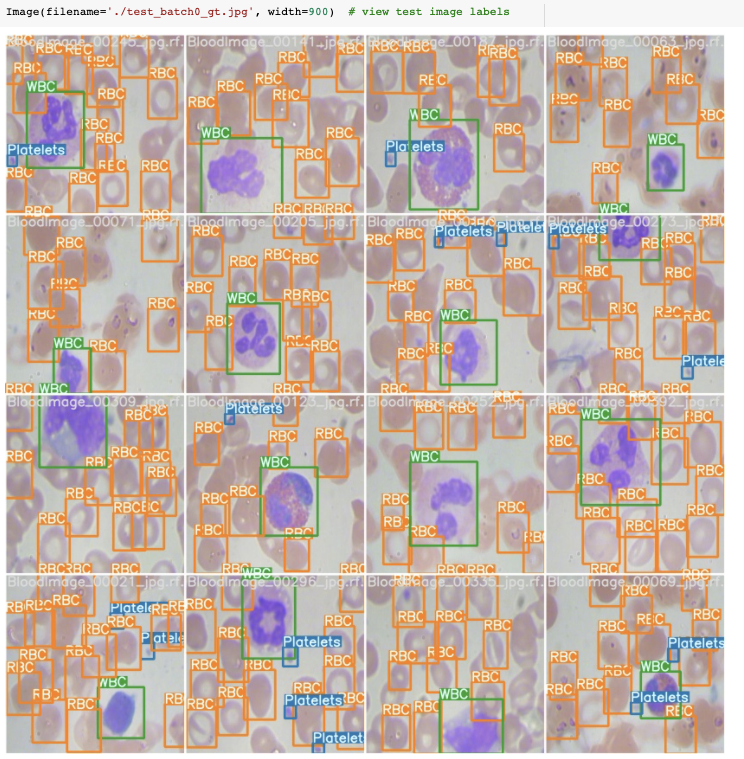
我们的真实训练数据
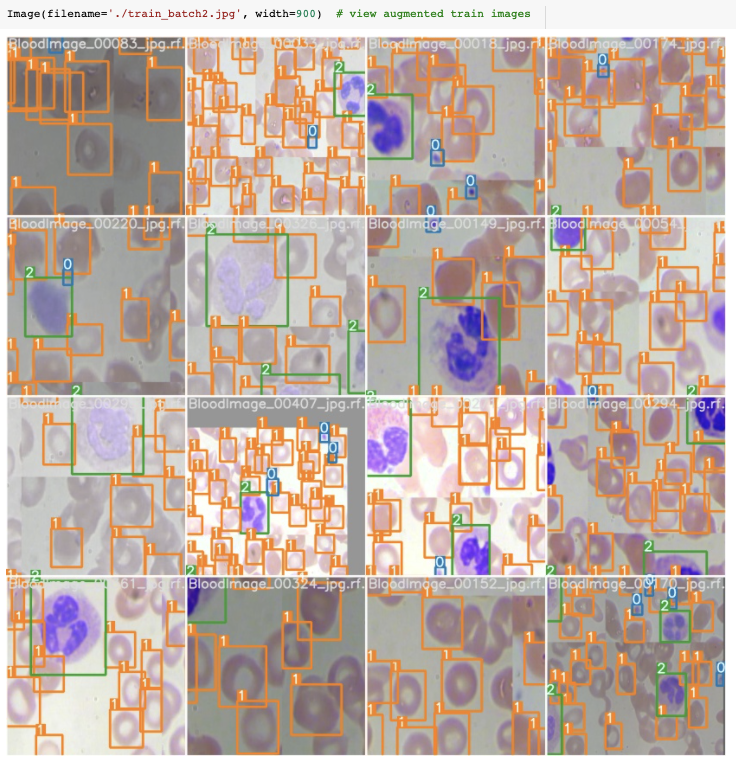
我们的训练数据采用自动YOLOv5增强
对测试图像运行YOLOv5推断
现在我们利用我们训练过的模型,对测试图像进行推理。训练完成后,模型权重将保存 weights/。
对于推理,我们调用这些权重和一个指定模型置信度的conf(要求的置信度越高,预测越少)和一个推理源。源可以接受一个包含图像、单个图像、视频文件以及设备的网络摄像头端口的目录。对于源代码,我将test/*jpg移到test-infer/。
!python detect.py --weights weights/last_yolov5s_custom.pt --img 416 --conf 0.4 --source ../test_infer推理时间非常快。在我们的 Tesla P100 上,YOLOv5s 达到了每秒142帧!!
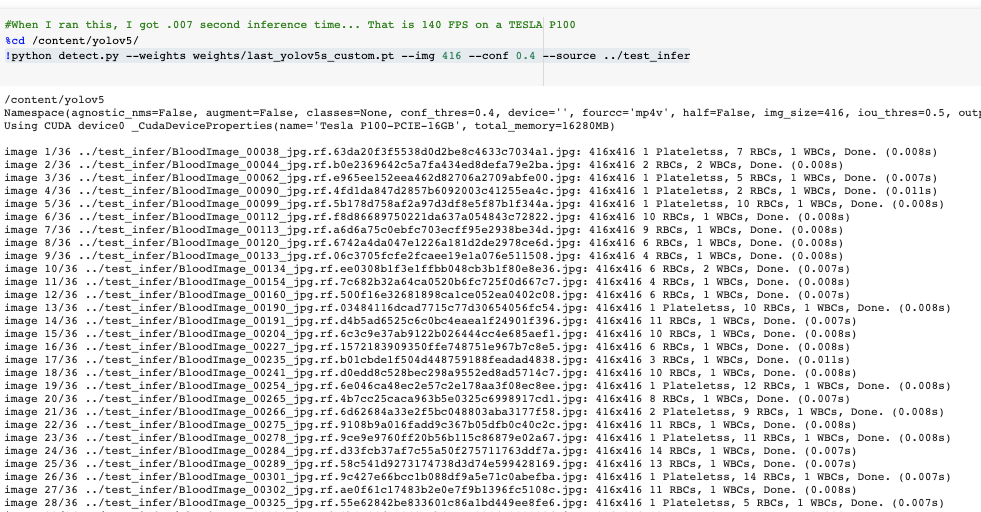
以142 FPS(0.007s/图像)的速度推断YOLOv5s
最后,我们在测试图像上可视化我们的探测器推断。
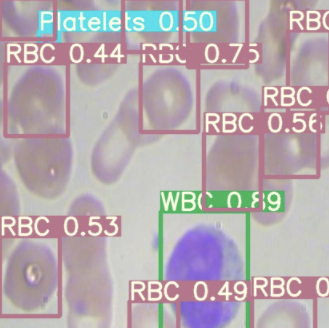
测试图像的YOLOv5推理
导出保存的YOLOv5权重以供将来推断
既然我们定制的YOLOv5物体探测器已经过验证,我们可能需要从Colab中取出权重,用于实时计算机视觉任务。为此,我们导入一个Google驱动器模块并将其发送出去。
from google.colab import drive
drive.mount('/content/gdrive')
%cp /content/yolov5/weights/last_yolov5s_custom.pt /content/gdrive/My\ Drive结论
我们希望你喜欢训练你的定制YOLOv5探测器!
使用 YOLOv5 非常方便。YOLOv5训练迅速,推理迅速,表现出色。
让我们把它弄出来!
原文链接:https://blog.roboflow.ai/how-to-train-yolov5-on-a-custom-dataset/
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
原创文章,作者:磐石,如若转载,请注明出处:https://panchuang.net/2020/10/19/%e5%a6%82%e4%bd%95%e5%9c%a8%e8%87%aa%e5%ae%9a%e4%b9%89%e6%95%b0%e6%8d%ae%e9%9b%86%e4%b8%8a%e8%ae%ad%e7%bb%83yolov5/
