
作者|ARAVIND PAI
编译|VK
来源|Analytics Vidhya
概述
-
理解预训练词嵌入的重要性
-
了解两种流行的预训练词嵌入类型:Word2Vec和GloVe
-
预训练词嵌入与从头学习嵌入的性能比较
介绍
我们如何让机器理解文本数据?我们知道机器非常擅长处理和处理数字数据,但如果我们向它们提供原始文本数据,它们是不能理解的。
这个想法是创建一个词汇的表示,捕捉它们的含义、语义关系和它们所使用的不同类型的上下文。这就是词嵌入的想法,将文本用数字表示。
预训练词嵌入是当今自然语言处理(NLP)领域中的一个重要组成部分。
但是,问题仍然存在——预训练的单词嵌入是否为我们的NLP模型提供了额外的优势?这是一个重要的问题,你应该知道答案。
因此在本文中,我将阐明预训练词嵌入的重要性。对于一个情感分析问题,我们还将比较预训练词嵌入和从头学习嵌入的性能。
目录
-
什么是预训练词嵌入?
-
为什么我们需要预训练的词嵌入?
-
预训练词嵌入的不同模型?
-
谷歌的Word2vec
-
斯坦福的GloVe
-
-
案例研究:从头开始学习嵌入与预训练词嵌入
什么是预训练词嵌入?
让我们直接回答一个大问题——预训练词嵌入到底是什么?
预训练词嵌入是在一个任务中学习到的词嵌入,它可以用于解决另一个任务。
这些嵌入在大型数据集上进行训练,保存,然后用于解决其他任务。这就是为什么预训练词嵌入是迁移学习的一种形式。
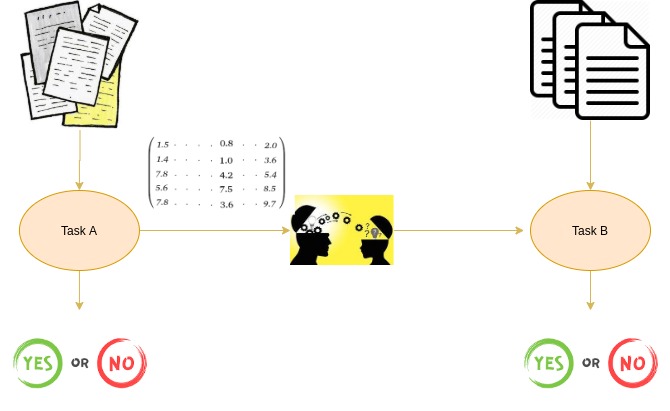
迁移学习,顾名思义,就是把一项任务的学习成果转移到另一项任务上。学习既可以是权重,也可以是嵌入。在我们这里,学习的是嵌入。因此,这个概念被称为预训练词嵌入。在权重的情况下,这个概念被称为预训练模型。
但是,为什么我们首先需要预训练词嵌入呢?为什么我们不能从零开始学习我们自己的嵌入呢?我将在下一节回答这些问题。
为什么我们需要预训练词嵌入?
预训练词嵌入在大数据集上训练时捕获单词的语义和句法意义。它们能够提高自然语言处理(NLP)模型的性能。这些单词嵌入在竞赛数据中很有用,当然,在现实世界的问题中也很有用。
但是为什么我们不学习我们自己的嵌入呢?好吧,从零开始学习单词嵌入是一个具有挑战性的问题,主要有两个原因:
-
训练数据稀疏
-
大量可训练参数
训练数据稀疏
不这样做的主要原因之一是训练数据稀少。大多数现实世界的问题都包含一个包含大量稀有单词的数据集。从这些数据集中学习到的嵌入无法得到单词的正确表示。
为了实现这一点,数据集必须包含丰富的词汇表。
大量可训练参数
其次,从零开始学习嵌入时,可训练参数的数量增加。这会导致训练过程变慢。从零开始学习嵌入也可能会使你对单词的表示方式处于不清楚的状态。
因此,解决上述问题的方法是预训练词嵌入。让我们在下一节讨论不同的预训练词嵌入。
预训练词嵌入的不同模型
我将把嵌入大致分为两类:单词级嵌入和字符级嵌入。ELMo和Flair嵌入是字符级嵌入的示例。在本文中,我们将介绍两种流行的单词级预训练词嵌入:
-
谷歌的Word2vec
-
斯坦福的GloVe
让我们了解一下Word2Vec和GloVe的工作原理。
谷歌的Word2vec
Word2Vec是Google开发的最流行的预训练词嵌入工具之一。Word2Vec是在Google新闻数据集(约1000亿字)上训练的。它有几个用例,如推荐引擎、单词相似度和不同的文本分类问题。
Word2Vec的架构非常简单。它是一个只有一个隐藏层的前馈神经网络。因此,它有时被称为浅层神经网络结构。
根据嵌入的学习方式,Word2Vec分为两种方法:
-
连续词袋模型(CBOW)
-
Skip-gram 模型
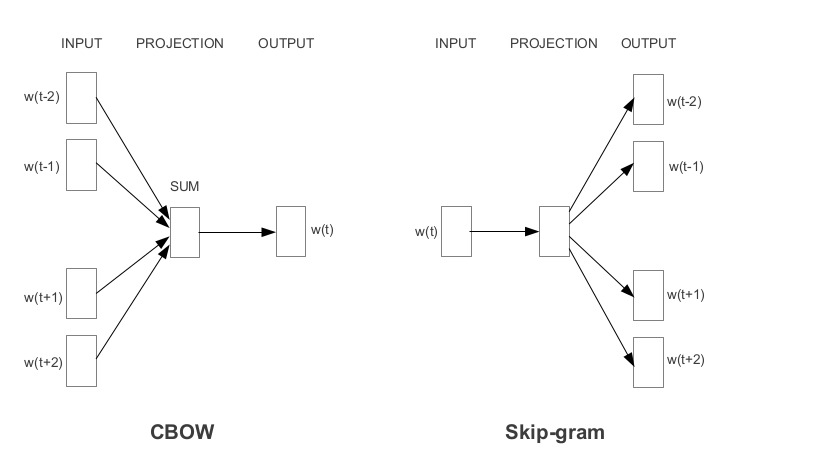
连续词袋(CBOW)模型在给定相邻词的情况下学习焦点词,而Skip-gram模型在给定词的情况下学习相邻词。
连续词袋模型模型和Skip-gram 模型是相互颠倒的。
例如,想想这句话:““I have failed at times but I never stopped trying”。假设我们想学习“failed”这个词的嵌入。所以,这里的焦点词是“failed”。
第一步是定义上下文窗口。上下文窗口是指出现在焦点词左右的单词数。出现在上下文窗口中的单词称为相邻单词(或上下文)。让我们将上下文窗口固定为2
-
连续词袋模型:Input=[I,have,at,times],Output=failed
-
Skip-gram 模型跳:Input = failed, Output = [I, have, at, times ]
如你所见,CBOW接受多个单词作为输入,并生成一个单词作为输出,而Skip gram接受一个单词作为输入,并生成多个单词作为输出。
因此,让我们根据输入和输出定义体系结构。但请记住,每个单词作为一个one-hot向量输入到模型中:
斯坦福的GloVe
GloVe嵌入的基本思想是从全局统计中导出单词之间的关系。
但是,统计数字怎么能代表意义呢?让我解释一下。
最简单的方法之一是看共现矩阵。共现矩阵告诉我们一对特定的词在一起出现的频率。共现矩阵中的每个值都是一对词同时出现的计数。
例如,考虑一个语料库:“play cricket, I love cricket and I love football”。语料库的共现矩阵如下所示:
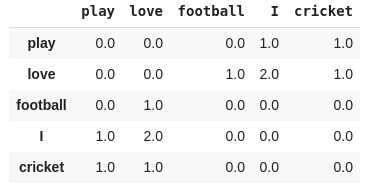
现在,我们可以很容易地计算出一对词的概率。为了简单起见,让我们把重点放在“cricket”这个词上:
p(cricket/play)=1
p(cricket/love)=0.5
接下来,我们计算概率比:
p(cricket/play) / p(cricket/love) = 2
当比率大于1时,我们可以推断板球最相关的词是“play”,而不是“love”。同样,如果比率接近1,那么这两个词都与板球有关。
我们可以用简单的统计方法得出这些词之间的关系。这就是GLoVE预训练词嵌入的想法。
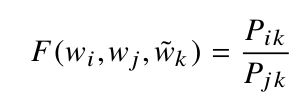
案例研究:从头开始学习嵌入与预训练词嵌入
让我们通过一个案例来比较从头开始学习我们自己的嵌入和预训练词嵌入的性能。我们还将了解使用预训练词嵌入是否会提高NLP模型的性能?
所以,让我们选择一个文本分类问题-电影评论的情感分析。从这里下载电影评论数据集(https://www.kaggle.com/columbine/imdb-dataset-sentiment-analysis-in-csv-format)。
将数据集加载到Jupyter:
#导入库
import pandas as pd
import numpy as np
#读取csv文件
train = pd.read_csv('Train.csv')
valid = pd.read_csv('Valid.csv')
#训练测试集分离
x_tr, y_tr = train['text'].values, train['label'].values
x_val, y_val = valid['text'].values, valid['label'].values准备数据:
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
tokenizer = Tokenizer()
#准备词汇表
tokenizer.fit_on_texts(list(x_tr))
#将文本转换为整数序列
x_tr_seq = tokenizer.texts_to_sequences(x_tr)
x_val_seq = tokenizer.texts_to_sequences(x_val)
#填充以准备相同长度的序列
x_tr_seq = pad_sequences(x_tr_seq, maxlen=100)
x_val_seq = pad_sequences(x_val_seq, maxlen=100)让我们看一下训练数据中的单词个数:
size_of_vocabulary=len(tokenizer.word_index) + 1 #+1用于填充
print(size_of_vocabulary)Output: 112204
我们将构建两个相同架构的不同NLP模型。第一个模型从零开始学习嵌入,第二个模型使用预训练词嵌入。
定义架构从零开始学习嵌入:
#深度学习库
from keras.models import *
from keras.layers import *
from keras.callbacks import *
model=Sequential()
#嵌入层
model.add(Embedding(size_of_vocabulary,300,input_length=100,trainable=True))
#lstm层
model.add(LSTM(128,return_sequences=True,dropout=0.2))
#Global Max池化
model.add(GlobalMaxPooling1D())
#Dense层
model.add(Dense(64,activation='relu'))
model.add(Dense(1,activation='sigmoid'))
#添加损失函数、度量、优化器
model.compile(optimizer='adam', loss='binary_crossentropy',metrics=["acc"])
#添加回调
es = EarlyStopping(monitor='val_loss', mode='min', verbose=1,patience=3)
mc=ModelCheckpoint('best_model.h5', monitor='val_acc', mode='max', save_best_only=True,verbose=1)
#输出模型
print(model.summary())输出:

模型中可训练参数总数为33889169。其中,嵌入层贡献了33661200个参数。参数太多了!
训练模型:
history = model.fit(np.array(x_tr_seq),np.array(y_tr),batch_size=128,epochs=10,validation_data=(np.array(x_val_seq),np.array(y_val)),verbose=1,callbacks=[es,mc])评估模型的性能:
#加载最佳模型
from keras.models import load_model
model = load_model('best_model.h5')
#评估
_,val_acc = model.evaluate(x_val_seq,y_val, batch_size=128)
print(val_acc)输出:0.865
现在,是时候用GLoVE预训练的词嵌入来构建第二版了。让我们把GLoVE嵌入到我们的环境中:
# 将整个嵌入加载到内存中
embeddings_index = dict()
f = open('../input/glove6b/glove.6B.300d.txt')
for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embeddings_index[word] = coefs
f.close()
print('Loaded %s word vectors.' % len(embeddings_index))输出:Loaded 400,000 word vectors.
通过为词汇表分配预训练的词嵌入,创建嵌入矩阵:
# 为文档中的单词创建权重矩阵
embedding_matrix = np.zeros((size_of_vocabulary, 300))
for word, i in tokenizer.word_index.items():
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector定义架构-预训练嵌入:
model=Sequential()
#嵌入层
model.add(Embedding(size_of_vocabulary,300,weights=[embedding_matrix],input_length=100,trainable=False))
#lstm层
model.add(LSTM(128,return_sequences=True,dropout=0.2))
#Global Max池化
model.add(GlobalMaxPooling1D())
#Dense层
model.add(Dense(64,activation='relu'))
model.add(Dense(1,activation='sigmoid'))
#添加损失函数、度量、优化器
model.compile(optimizer='adam', loss='binary_crossentropy',metrics=["acc"])
#添加回调
es = EarlyStopping(monitor='val_loss', mode='min', verbose=1,patience=3)
mc=ModelCheckpoint('best_model.h5', monitor='val_acc', mode='max', save_best_only=True,verbose=1)
#输出模型
print(model.summary())输出:

如你所见,可训练参数的数量仅为227969。与嵌入层相比,这是一个巨大的下降。
训练模型:
history = model.fit(np.array(x_tr_seq),np.array(y_tr),batch_size=128,epochs=10,validation_data=(np.array(x_val_seq),np.array(y_val)),verbose=1,callbacks=[es,mc])评估模型的性能:
#加载最佳模型
from keras.models import load_model
model = load_model('best_model.h5')
#评估
_,val_acc = model.evaluate(x_val_seq,y_val, batch_size=128)
print(val_acc)输出:88.49
与从头学习嵌入相比,使用预训练词嵌入的性能有所提高。
结尾
预训练词嵌入是有力的文本表示方式,因为它们往往捕捉单词的语义和句法意义。
在本文中,我们了解了预训练词嵌入的重要,并讨论了两种流行的预训练词嵌入:Word2Vec和gloVe。
原文链接:https://www.analyticsvidhya.com/blog/2020/03/pretrained-word-embeddings-nlp/
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
原创文章,作者:磐石,如若转载,请注明出处:https://panchuang.net/2020/10/19/%e9%a2%84%e8%ae%ad%e7%bb%83%e8%af%8d%e5%b5%8c%e5%85%a5/
