
作者|Gonçalo Guimarães Gomes
编译|VK
来源|Towards Datas Science

作为每个数据科学家都非常熟悉和使用的最受欢迎和使用的工具之一,Pandas库在数据操作、分析和可视化方面非常出色
为了帮助你完成这项任务并对Python编码更加自信,我用Pandas上一些最常用的函数和方法创建了本教程。我真心希望这对你有用。
目录
- 导入库
- 导入/导出数据
- 显示数据
- 基本信息:快速查看数据
- 基本统计
- 调整数据
- 布尔索引:loc
- 布尔索引:iloc
- 基本处理数据
我们将研究“泰坦尼克号”的数据集,主要有两个原因:(1)很可能你已经对它很熟悉了;(2)它非常小,很简单
泰坦尼克号的数据集可以在这里下载:https://bit.ly/33tOJ2S
导入库
为了我们的目的,“Pandas”库是必须导入的
import pandas as pd导入/导出数据
“泰坦尼克号数据集”指定为“data”。
a) 使用read_csv将csv文件导入。你应该在文件中添加数据的分隔符。
data = pd.read_csv("file_name.csv", sep=';')b) 使用read_excel从excel文件读取数据。
data = pd.read_excel('file_name.xls')c) 将数据帧导出到csv文件,使用to_csv
data.to_csv("file_name.csv", sep=';', index=False)d) 使用“to_excel”将数据框导出到excel文件。
data.to_excel("file_name.xls´)显示数据
a) 正在打印前n行。如果没有给定,则默认显示5行。
data.head()
b) 打印最后“n”行。下面,显示最后7行。
data.tail(7)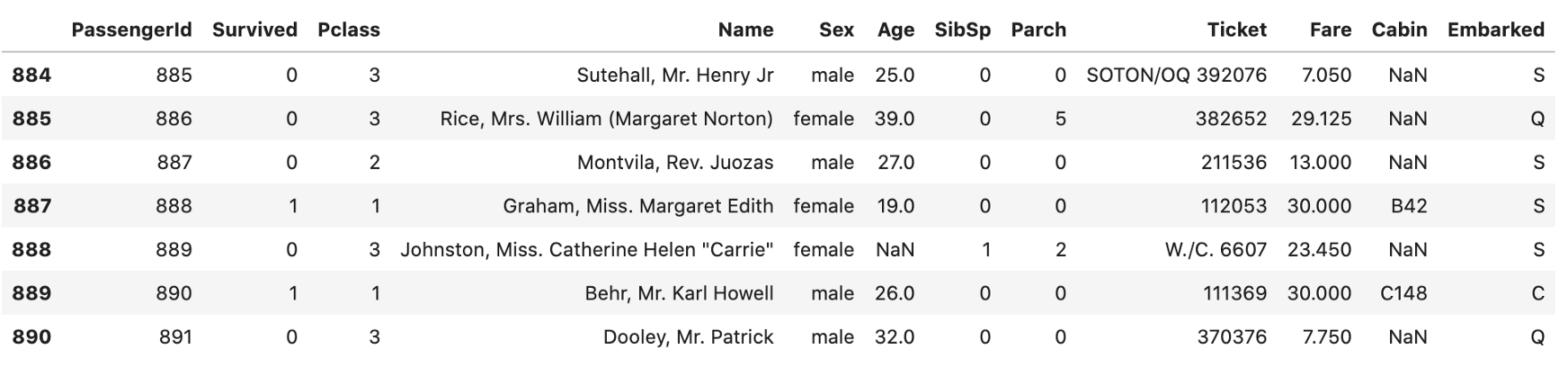
基本信息:快速查看数据
a) 显示数据集的维度:总行数、列数。
data.shape(891,12)
b) 显示变量类型。
data.dtypesPassengerId int64
Survived int64
Pclass int64
Name object
Sex object
Age float64
SibSp int64
Parch int64
Ticket object
Fare float64
Cabin object
Embarked object
dtype: objectc) 按升序值显示变量类型。
data.dtypes.sort_values(ascending=True)PassengerId int64
Survived int64
Pclass int64
SibSp int64
Parch int64
Age float64
Fare float64
Name object
Sex object
Ticket object
Cabin object
Embarked object
dtype: objectd) 按类型对变量计数。
data.dtypes.value_counts()object 5
int64 5
float64 2
dtype: int64e) 按升序值对每种类型计数。
data.dtypes.value_counts(ascending=True)float64 2
int64 5
object 5
dtype: int64f) 以绝对值检查生存者与非生存者的数量。
data.Survived.value_counts()0 549
1 342
Name: Survived, dtype: int64g) 检查特征的比例,以百分比表示。
data.Survived.value_counts() / data.Survived.value_counts().sum()与以下相同:
data.Survived.value_counts(normalize=True)0 0.616162
1 0.383838
Name: Survived, dtype: float64h) 检查特征的比例,以百分比表示,四舍五入。
data.Survived.value_counts(normalize=True).round(decimals=4) * 1000 61.62
1 38.38
Name: Survived, dtype: float64i) 评估数据集中是否存在缺失值。
data.isnull().values.any()Truej) 使用isnull()得到缺失值的数目。
data.isnull().sum()PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64k) 使用notnull()得到现有值的数目。
data.notnull().sum()PassengerId 891
Survived 891
Pclass 891
Name 891
Sex 891
Age 714
SibSp 891
Parch 891
Ticket 891
Fare 891
Cabin 204
Embarked 889
dtype: int64l) 按变量列出的缺失值的百分比(%)。
data.isnull().sum() / data.isnull().shape[0] * 100等同于
data.isnull().mean() * 100PassengerId 0.000000
Survived 0.000000
Pclass 0.000000
Name 0.000000
Sex 0.000000
Age 19.865320
SibSp 0.000000
Parch 0.000000
Ticket 0.000000
Fare 0.000000
Cabin 77.104377
Embarked 0.224467
dtype: float64m) 四舍五入(在示例中为2)。
(data.isnull().sum() / data.isnull().shape[0] * 100).round(decimals=2)等同于
(data.isnull().mean() * 100).round(decimals=2)PassengerId 0.00
Survived 0.00
Pclass 0.00
Name 0.00
Sex 0.00
Age 19.87
SibSp 0.00
Parch 0.00
Ticket 0.00
Fare 0.00
Cabin 77.10
Embarked 0.22
dtype: float64n) 另外:用组合文本打印结果。
print("The percentage of 'Age' is missing values:",(data.Age.isnull().sum() / data.Age.isnull().shape[0] * 100).round(decimals=2), "%")The percentage of 'Age' is missing values: 19.87 %print(f"The feature 'Age' has {data.Age.isnull().sum()} missing values")The feature 'Age' has 177 missing valuesprint("'Age' has {} and 'Cabin' has {} missing values".format(data.Age.isnull().sum(), data.Cabin.isnull().sum()))'Age' has 177 and 'Cabin' has 687 missing valueso) 形状、变量类型和缺失值的信息。
data.info()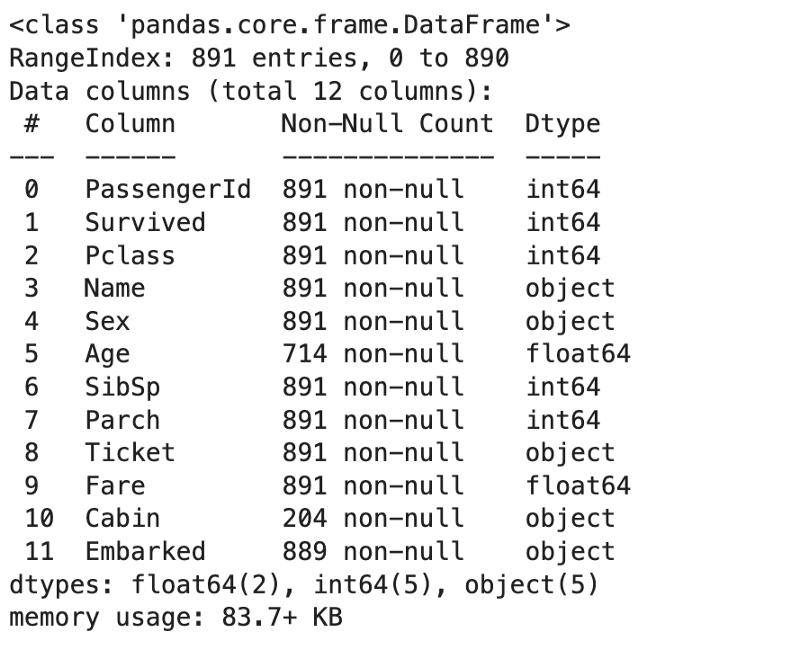
p) 具体特征概述(下例中为“性别”和“年龄”)。
data[['Sex','Age']].info()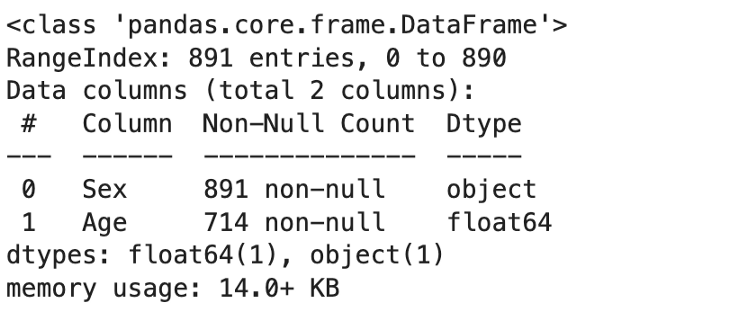
基本统计
a) describe方法只给出数据的基本统计信息。默认情况下,它只计算数值数据的主统计信息。结果用pandas数据帧表示。
data.describe()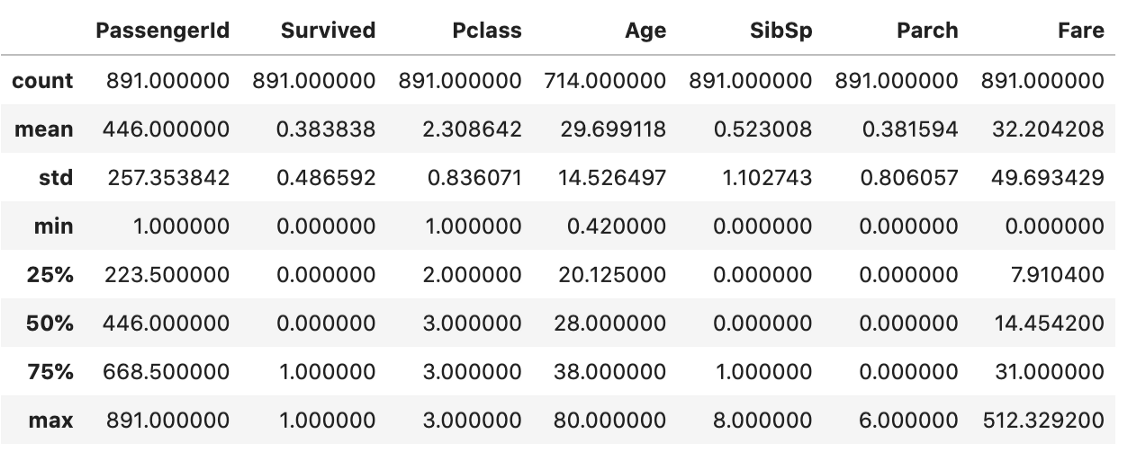
b) 添加其他非标准值,例如“方差”。
describe = data.describe()
describe.append(pd.Series(data.var(), name='variance'))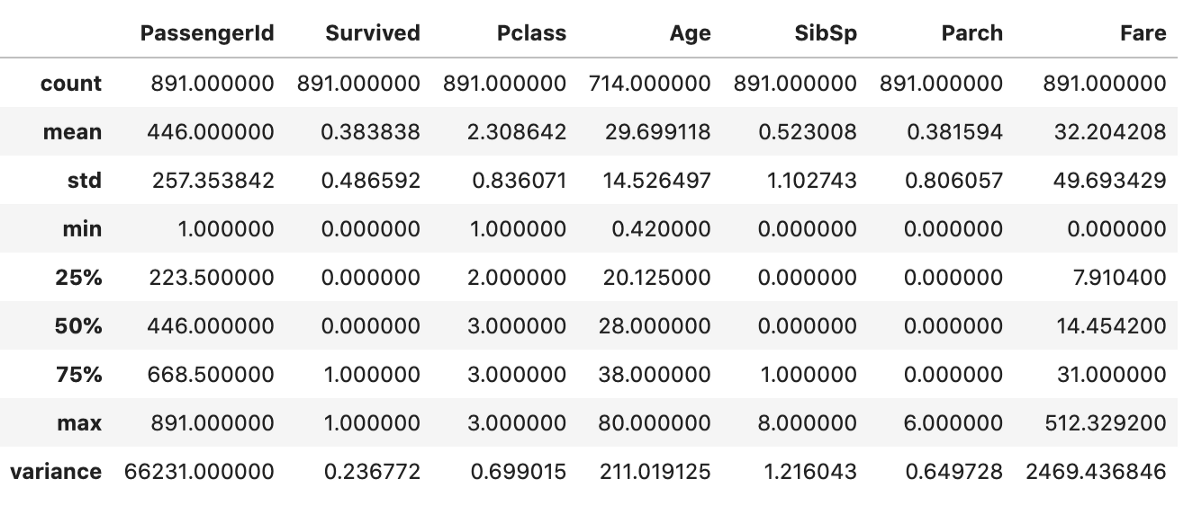
c) 显示分类数据。
data.describe(include=["O"])等同于
data.describe(exclude=['float64','int64'])等同于
data.describe(include=[np.object])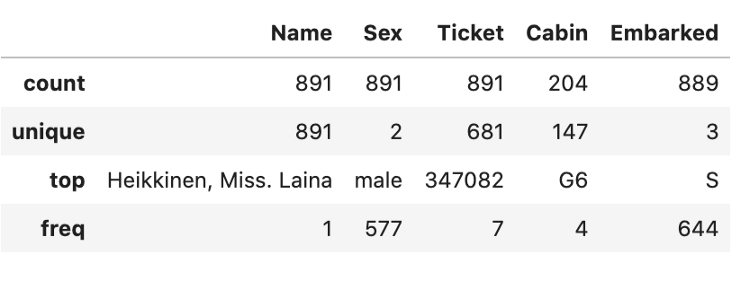
d) 通过传递参数include=’all’,将同时显示数字和非数字数据。
data.describe(include='all')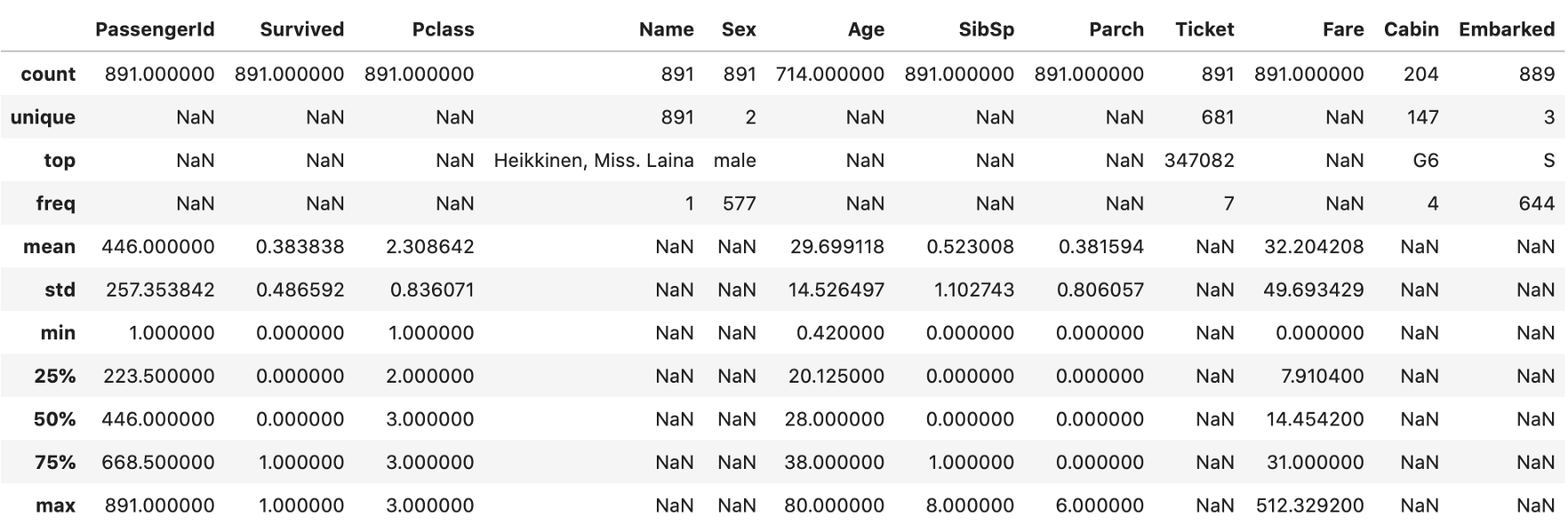
e) 别忘了通过在末尾添加.T来转置数据帧。这也是一个非常有用的技巧
data.describe(include='all').T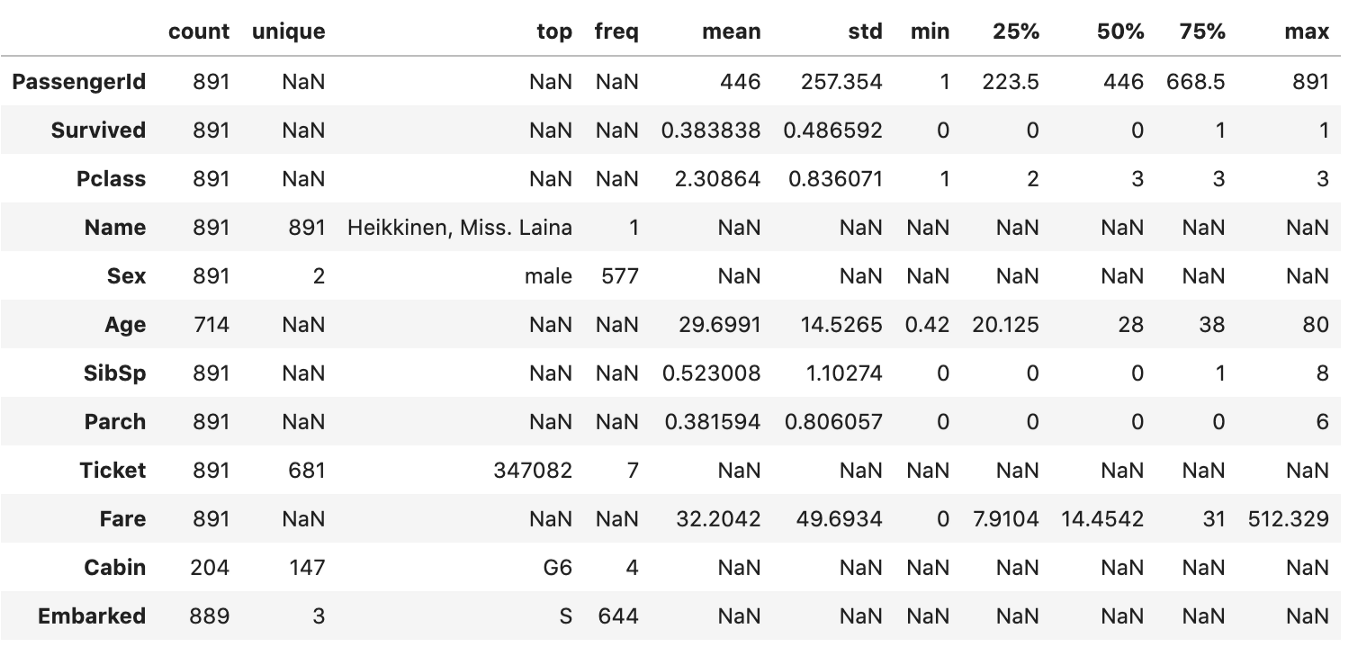
f) 百分位数1%、5%、95%、99%。正如预期的那样,它将只计算数字特征的统计信息。
data.quantile(q=[.01, .05, .95, .99])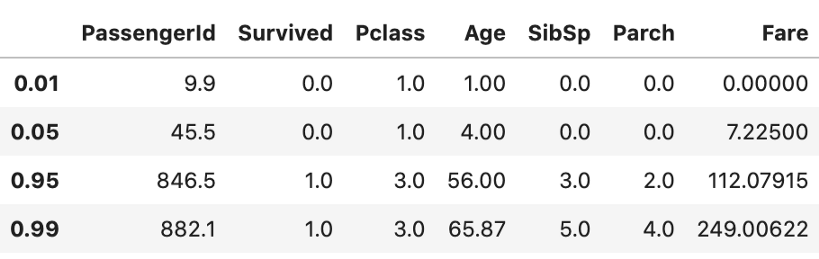
g) 摘要统计
- 显示某些特征的唯一值。
data.Embarked.unique()array(['S', 'C', 'Q', nan], dtype=object)- 计算某个特征的唯一值的总和。
data.Sex.nunique()2- 计算总值
data.count()PassengerId 891
Survived 891
Pclass 891
Name 891
Sex 891
Age 714
SibSp 891
Parch 891
Ticket 891
Fare 891
Cabin 204
Embarked 889
dtype: int64- 某些特征的最大值
data.Age.max()80.0- 某些特征的最小值
data.Age.min()0.42- 某些特征的平均值
data.Age.mean()29.69911764705882- 某些特征的中值
data.Age.median()28.0- 某些特征的第99分位数
data.Age.quantile(q=[.99])0.99 65.87
Name: Age, dtype: float64- 某些特征的标准差
data.Age.std()14.526497332334044- 某些特征的方差
data.Age.var()211.0191247463081h)额外
问题1-显示分类特征“Embarked”最常见的两个值。
data[‘Embarked’].value_counts().head(2)S 644
C 168
Name: Embarked, dtype: int64问题2-“Embarked”的百分比最高是多少?
top_unique = data['Embarked'].value_counts(normalize=True)[0]
print(f'{top_unique:.2%}')72.44%i) 变量之间的相关性。正如预期的那样,它将只显示数值数据的统计信息。
data.corr()默认情况下的皮尔逊相关性
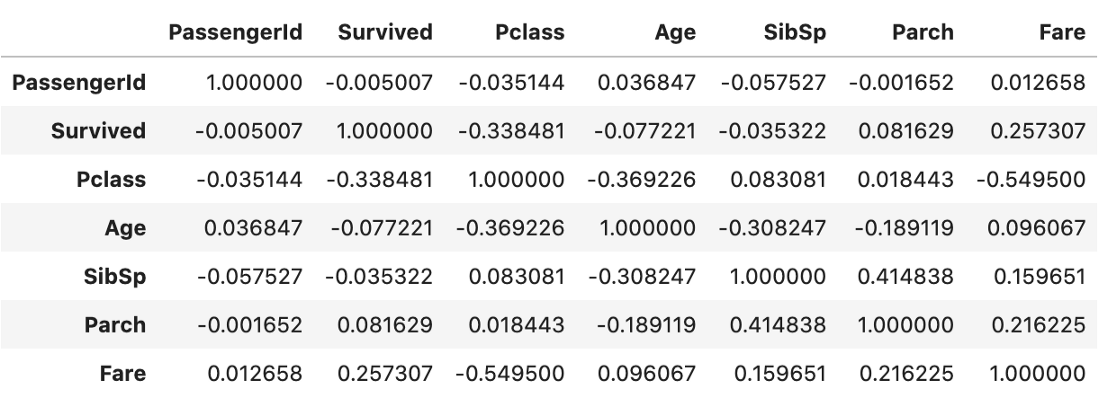
J) 所选变量(示例中为“Survived”)与其他变量之间的相关性。
correlation = data.corr()
correlation.Survived.sort_values().sort_values(ascending=False) # 有序值Survived 1.000000
Fare 0.257307
Parch 0.081629
PassengerId -0.005007
SibSp -0.035322
Age -0.077221
Pclass -0.338481
Name: Survived, dtype: float64调整数据
a) 列出列的名称。
data.columnsIndex(['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp', 'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked'], dtype='object')b) 重命名某些列(在下面的示例中,将“PassengerId”改为“id”)。
data.rename(columns = {data.columns[0]:'id'}, inplace=True)等同于
data.rename(columns = {'PassengerId':'id'}, inplace=True)Index(['id', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp', 'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked'], dtype='object')c) 重命名多个列(“PassengerId”、“Pclass”和“SibSp”)。
data.rename(columns = {'PassengerId':'Passenger_Id', 'Pclass':'P_Class', 'SibSp':'Sib_Sp'}, inplace=True)Index(['Passenger_Id', 'Survived', 'P_Class', 'Name', 'Sex', 'Age', 'Sib_Sp', 'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked'], dtype='object')d) 通过列表生成式将下划线替换为点(仅适用于“Passenger.Id”、“P.Class”和“Sib.Sp”)。
data.columns = [x.lower().replace('.', '') for x in data.columns]Index(['passengerid', 'survived', 'pclass', 'name', 'sex', 'age', 'sibsp', 'parch', 'ticket', 'fare', 'cabin', 'embarked'], dtype='object')e) 小写化字符并删除点(应用于’Passenger.Id’,’P.Class’和’Sib.Sp’)。
data.columns = [x.lower().replace('.', '') for x in data.columns]Index(['passengerid', 'survived', 'pclass', 'name', 'sex', 'age', 'sibsp', 'parch', 'ticket', 'fare', 'cabin', 'embarked'], dtype='object')f) 将列名称大写。
data.columns = [x.capitalize() for x in data.columns]Index(['Passengerid', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'Sibsp', 'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked'], dtype='object')布尔索引:loc
data.loc[<lines>, <columns>],按列名称选择
a) 选择行。
data.loc[[3]]
b) 选择行数组。
data.loc[6:8]
c) 选择几行。
data.loc[[7,28,39]]
d) 从“Name”、“Age”、“Sex”和“Survived”几个列中选择一行。
data.loc[[7], ['Name', 'Age', 'Sex', 'Survived']]
e) 从多个列中选择多行。
data.loc[[7,28,39], ['Name', 'Age', 'Sex','Survived']]
f) 在某些条件下使用loc选择特定值。在这种情况下,从第4行到第10行选择年龄大于或等于10岁的乘客。
data.loc[4:10, ['Age']] >= 10
g) 在某些条件下使用loc选择特定值。在这种情况下,从前5行选择乘坐C123客舱的乘客。
data.loc[:4, ['Cabin']] == 'C123'
布尔索引:iloc
data.iloc[<lines>, <columns>]按数字选择行和列
a) 选择数据集的第4行。
data.iloc[3]
b) 从所有列中选择一个行数组。
data.iloc[6:12]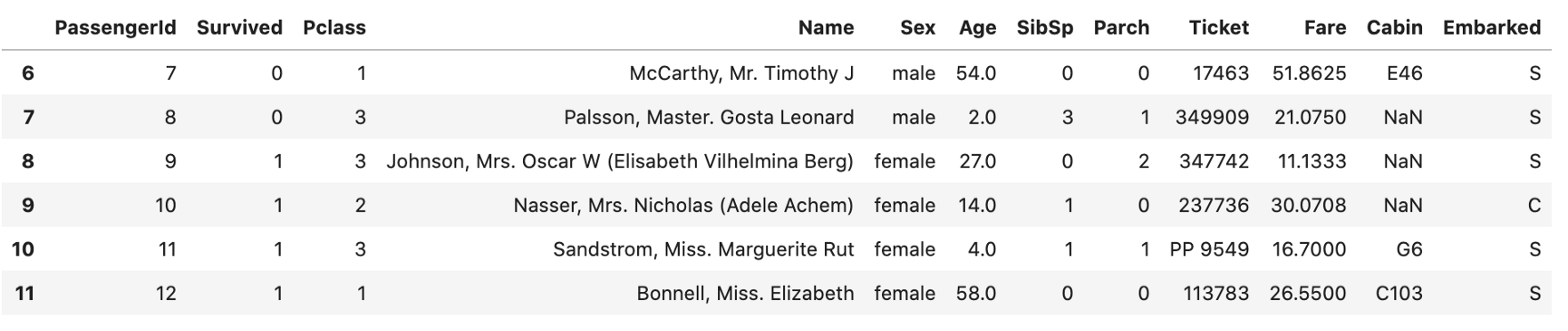
c) 从所有列中选择几行。
data.iloc[[7,28,39],:]
d) 从“Name”、“Age”、“Sex”和“Survived”列中选择一行。
data.iloc[[7], [3,5,4,1]]
e) 从多个列中选择多行。
data.iloc[[7,28,39], [3,5,4,1]]
f) 选择多行形成列序列。
data.iloc[[7,28,39], 3:10]
g) 选择其他值。
- 从第6行到第12行,最后一列。
data.iloc[6:13, -1]- 第3列和第6列的所有行。
data.iloc[:, [3,6]]- 7、28、39行,从第3列到第6列。
data.iloc[[7,28,39], 3:7]- 最后一列的最后20行。
data.iloc[-20:, -1:]基本处理数据
- Axis = 0,表示行,如果未指定,默认为Axis=0。
- Axis = 1,表示列。

a) (删除nan值)。
data.isnull().values.any()是否有丢失的数据?
True如果没有将其分配到(新)变量中,则应该指定inplace=True,以便更改能生效。
data.dropna(axis=0, inplace=True) #从行中删除nan
data.isnull().values.any() #是否有丢失的数据?Falseb) 删除列
data.drop(columns=['PassengerId', 'Name'], axis=1).head()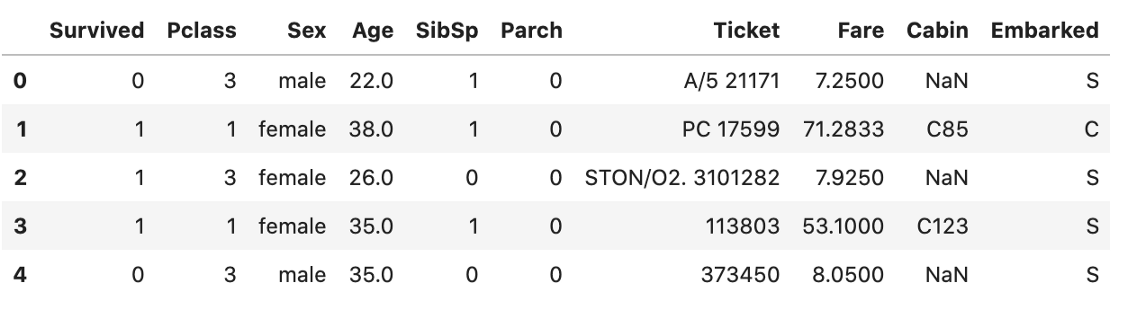
c) value_counts也可以显示NaN值。
data.Age.value_counts(dropna=False)NaN 177
24.00 30
22.00 27
18.00 26
28.00 25
...
36.50 1
55.50 1
66.00 1
23.50 1
0.42 1
Name: Age, Length: 89, dtype: int64d) 替换丢失值
- 创建新的数据帧,复制数据,以保持原始数据的完整性。
new_df = data.copy()计算年龄平均值:
new_df.Age.mean()29.69911764705882- 用数据的平均值填充NAN,并将结果分配给一个新列。
new_df['Age_mean'] = new_df.Age.fillna(new_df.Age.mean())年龄的中值
new_df.Age.median()28.0用数据的中值填充任意NAN,并将结果分配给一个新列。
new_df['Age_median'] = new_df.Age.fillna(new_df.Age.median())- 验证结果
new_df[['Age', 'Age_mean', 'Age_median']].isnull().sum()Age 177
Age_mean 0
Age_median 0
dtype: int64显示第106至110行,以验证两个NAN示例的插补(第107和109行)。
new_df[['Age', 'Age_mean', 'Age_median']][106:110]
结束了

结论
我真诚地希望你觉得这个教程有用,因为它可以帮助你编写代码的开发。我将在将来更新它并将其链接到其他Python教程。
原文链接:https://towardsdatascience.com/pandas-made-easy-the-guide-i-81834f075893
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
原创文章,作者:磐石,如若转载,请注明出处:https://panchuang.net/2020/10/19/pandas%e6%95%99%e7%a8%8b/
