
spaCy教程学习
作者|PRATEEK JOSHI
编译|VK
来源|Analytics Vidhya
介绍
spaCy是我的自然语言处理(NLP)任务的必备库。我冒昧地说,大多数专家都是这样!
如今,在众多的NLP库中,spaCy确实独树一帜。如果你在NLP上用过spaCy,你就会知道我在说什么。如果你对spaCy的强大功能还不熟悉,你会被这个库的多功能性和灵活性所吸引。
spaCy的优点是它提供一系列优良的特性,库也是易用的,以及库总是保持最新。

spaCy入门
如果你对spaCy还不熟悉,你应该注意以下几点:
-
spaCy的统计模型
-
spaCy的处理管道
让我们详细讨论一下每一个问题。
spaCy的统计模型
这些模型是spaCy的核心。这些模型使spaCy能够执行一些与NLP相关的任务,例如词性标记、命名实体识别和依存关系解析。
下面我列出了spaCy中的不同统计模型及其规范:
-
en_core_web_sm:英语多任务CNN,在OntoNotes上训练,大小为11 MB
-
en_core_web_md:英语多任务CNN,在OntoNotes上训练,并且使用Common Crawl上训练的GLoVe词嵌入,大小为91 MB
-
en_core_web_lg:英语多任务CNN,在OntoNotes上训练,并且使用Common Crawl上训练的GLoVe词嵌入,大小为789 MB
导入这些模型非常容易。我们可以通过执行spacy.load(‘model_name’) 导入模型,如下所示:
import spacy
nlp = spacy.load('en_core_web_sm')spaCy的处理管道
使用spaCy时,文本字符串的第一步是将其传递给NLP对象。这个对象本质上是由几个文本预处理操作组成的管道,输入文本字符串必须通过这些操作。
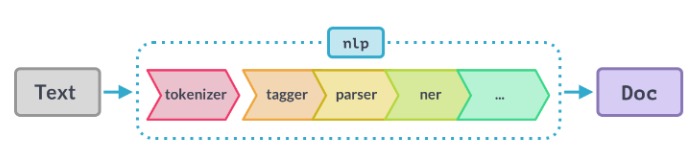
如上图所示,NLP管道有多个组件,如标记生成器、标签器、解析器、ner等。因此,在处理输入文本字符串之前,必须先通过所有这些组件。
让我演示如何创建nlp对象:
import spacy
nlp = spacy.load('en_core_web_sm')
# 创建nlp对象
doc = nlp("He went to play basketball")你可以使用以下代码找出活动的管道组件:
nlp.pipe_names输出:[‘tagger’,’parser’,’ner’]
如果您希望禁用管道组件并仅保持ner的运行,则可以使用下面的代码禁用管道组件:
nlp.disable_pipes('tagger', 'parser')让我们再次检查活动管道组件:
nlp.pipe_names输出:[‘ner’]
当您只需要标记文本时,就可以禁用整个管道。标记化过程变得非常快。例如,可以使用以下代码行禁用管道的多个组件:
nlp.disable_pipes('tagger', 'parser')spaCy实战
现在,让我们练手。在本节中,你将学习使用spaCy执行各种NLP任务。我们将从流行的NLP任务开始,包括词性标记、依存分析和命名实体识别。
1.词性标注
在英语语法中,词类告诉我们一个词的功能是什么,以及如何在句子中使用。英语中常用的词类有名词、代词、形容词、动词、副词等。
词性标注是自动将词性标注分配给句子中所有单词的任务。它有助于NLP中的各种下游任务,如特征工程、语言理解和信息提取。
在spaCy中执行POS标记是一个简单的过程:
import spacy
nlp = spacy.load('en_core_web_sm')
# 创建nlp对象
doc = nlp("He went to play basketball")
# 遍历token
for token in doc:
# Print the token and its part-of-speech tag
print(token.text, "-->", token.pos_)输出:
He –> PRON
went –> VERB
to –> PART
play –> VERB
basketball –> NOUN
因此,该模型正确识别了句子中所有单词的POS标记。如果你对这些标记中的任何一个都不确定,那么您可以简单地使用spacy.explain()来确定:
spacy.explain("PART")输出: ‘particle’
2.使用spaCy进行依存分析
每个句子都有一个语法结构,通过依存句法分析,我们可以提取出这个结构。它也可以看作是一个有向图,其中节点对应于句子中的单词,节点之间的边是单词之间的对应依赖关系。
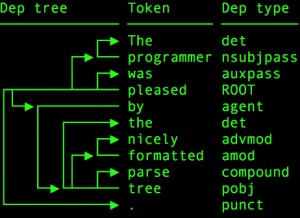
在spaCy中,执行依存分析同样非常容易。我们将使用与词性标注相同的句子:
# 依存分析
for token in doc:
print(token.text, "-->", token.dep_)输出:
He –> nsubj
went –> ROOT
to –> aux
play –> advcl
basketball –> dobj
依存标记ROOT表示句子中的主要动词或动作。其他词与句子的词根有直接或间接的联系。通过执行下面的代码,你可以了解其他标记的含义:
spacy.explain("nsubj"), spacy.explain("ROOT"), spacy.explain("aux"), spacy.explain("advcl"), spacy.explain("dobj")输出:
(‘nominal subject’,
None,
‘auxiliary’,
‘adverbial clause modifier’,
‘direct object’)
3.基于spaCy的命名实体识别
首先让我们了解什么是实体。实体是表示诸如个人、地点、组织等常见事物的信息的词或词组。这些实体具有专有名称。
例如,请考虑以下句子:

在这句话中,实体是“Donald Trump”、“Google”和“New York City”。
现在让我们看看spaCy如何识别句子中的命名实体。
doc = nlp("Indians spent over $71 billion on clothes in 2018")
for ent in doc.ents:
print(ent.text, ent.label_)输出:
Indians NORP
over $71 billion MONEY
2018 DATE
spacy.explain("NORP")输出:‘Nationalities or religious or political groups’
4.基于规则的spaCy匹配
基于规则的匹配是spaCy的新功能。使用这个spaCy匹配器,您可以使用用户定义的规则在文本中查找单词和短语。
就像正则表达式。
正则表达式使用文本模式来查找单词和短语,而spaCy匹配器不仅使用文本模式,还使用单词的词汇属性,如POS标记、依赖标记、词根等。
让我们看看它是如何工作的:
import spacy
nlp = spacy.load('en_core_web_sm')
# 导入 spaCy Matcher
from spacy.matcher import Matcher
#用spaCy词汇表初始化Matcher
matcher = Matcher(nlp.vocab)
doc = nlp("Some people start their day with lemon water")
# 定义规则
pattern = [{'TEXT': 'lemon'}, {'TEXT': 'water'}]
# 添加规则
matcher.add('rule_1', None, pattern)所以,在上面的代码中:
-
首先,我们导入spaCy matcher
-
之后,我们用默认的spaCy词汇表初始化matcher对象
-
然后,我们像往常一样在NLP对象中传递输入
-
在下一步中,我们将为要从文本中提取的内容定义规则。
假设我们想从文本中提取“lemon water”这个短语。所以,我们的目标是water跟在lemon后面。最后,我们将定义的规则添加到matcher对象。
现在让我们看看matcher发现了什么:
matches = matcher(doc)
matches输出: [(7604275899133490726, 6, 8)]
输出有三个元素。第一个元素“7604275899133490726”是匹配ID。第二个和第三个元素是匹配标记的位置。
# 提取匹配文本
for match_id, start, end in matches:
# 获得匹配的宽度
matched_span = doc[start:end]
print(matched_span.text)输出:lemon water
因此,模式是一个标记属性列表。例如,“TEXT”是一个标记属性,表示标记的确切文本。实际上,spaCy中还有许多其他有用的标记属性,可以用来定义各种规则和模式。
我列出了以下标记属性:
| 属性 | 类型 | 描述 |
|---|---|---|
ORTH |
unicode | 精确匹配的文本 |
TEXT |
unicode | 精确匹配的文本 |
LOWER |
unicode | 文本小写形式 |
LENGTH |
int | 文本的长度 |
IS_ALPHA, IS_ASCII, IS_DIGIT |
bool | 文本由字母字符、ASCII字符、数字组成。 |
IS_LOWER, IS_UPPER, IS_TITLE |
bool | 文本是小写、大写、首字母大写格式的。 |
IS_PUNCT, IS_SPACE, IS_STOP |
bool | 文本是标点符号、空格、停用词。 |
LIKE_NUM, LIKE_URL, LIKE_EMAIL |
bool | 文本表示数字、URL和电子邮件。 |
POS, TAG, DEP, LEMMA, SHAPE |
unicode | 文本是词性标记、依存标签、词根、形状。 |
ENT_TYPE |
unicode | 实体标签 |
让我们看看spaCy matcher的另一个用例。考虑下面的两句话:
- You can read this book
- I will book my ticket
现在我们感兴趣的是找出一个句子中是否含有“book”这个词。看起来挺直截了当的对吧?但这里有一个问题——只有当“book”这个词在句子中用作名词时,我们才能找到它。
在上面的第一句中,“book”被用作名词,在第二句中,它被用作动词。因此,spaCy匹配器应该只能从第一句话中提取。我们试试看:
doc1 = nlp("You read this book")
doc2 = nlp("I will book my ticket")
pattern = [{'TEXT': 'book', 'POS': 'NOUN'}]
# 用共享的vocab初始化matcher
matcher = Matcher(nlp.vocab)
matcher.add('rule_2', None, pattern)matches = matcher(doc1)
matches输出: [(7604275899133490726, 3, 4)]
matcher在第一句话中找到了模式。
matches = matcher(doc2)
matches输出:[]
很好!尽管“book”出现在第二句话中,matcher却忽略了它,因为它不是一个名词。
结尾
这是一个很短的介绍,让你尝尝spaCy能做什么。相信我,你会发现自己在NLP任务中经常使用spaCy。我鼓励你使用这些代码,从DataHack中获取一个数据集,并使用spaCy尝试使用它。
原文链接:https://www.analyticsvidhya.com/blog/2020/03/spacy-tutorial-learn-natural-language-processing/
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
原创文章,作者:磐石,如若转载,请注明出处:https://panchuang.net/2020/10/19/spacy%e6%95%99%e7%a8%8b%e5%ad%a6%e4%b9%a0/
