
在这篇文章中,我们将了解一种使用单个深度神经网络(SSD)检测图像中的对象的方法及其体系结构,其中包括一些关于MultiBox算法和其他技术等的其他信息。在这篇文章之后,我希望您能更好地掌握SSD和对象检测
目标检测
目标检测是一种计算机视觉技术,它允许我们识别和定位图像或视频中的目标。有了这种识别和定位,目标检测可以用来对场景中的目标进行计数,确定和跟踪它们的精确位置,同时对它们进行准确的标记。现在我们已经熟悉了目标定位和检测的问题,让我们来看看最近一些性能最好的深度学习模型。
R-CNN模范家庭
一些流行的目标检测模型属于R-CNN家族,R-CNN家族指的是R-CNN,即“具有CNN特征的区域”或“基于区域的卷积神经网络”。区域卷积神经网络是区域卷积神经网络的缩写,这些结构都是基于区域提议结构的。多年来,它们变得更准确,计算效率也更高。MASK R-CNN是Facebook研究人员开发的最新版本,它为服务器端目标检测模型提供了一个很好的起点。
YOLO
R-CNN模型通常可能更准确,但是YOLO模型家族比R-CNN模型更快,比R-CNN快得多,实现了实时的对象检测
固态硬盘
单镜头多盒检测器(SSD)是一种目标检测算法,它是对VGG16体系结构的改进。它于2016年11月底发布,在对象检测任务的性能和精度方面创下了新的纪录,在PascalVOC和COCO等标准数据集上以59帧/秒的速度获得了超过74%的MAP(平均精度)。像YOLO这样的SSD使用多盒只需一次镜头就可以检测到图像中存在的多个对象。
架构
SSD方法基于前馈卷积网络,该网络产生固定大小的包围盒集合和这些包围盒中存在的对象类实例的分数,然后进行非最大值抑制步骤以产生最终检测。SSD通常从RESNET预先训练的模型上的VGG开始,该模型被转换为完全卷积神经网络。需要注意的重要一点是,在VGG网络上传递图像后,会添加一些转换层,生成大小为19×19、10×10、5×5、3×3、1×1的特征地图。这些与VGG的Conv4_3生成的38×38特征地图是将用于预测包围盒的特征地图。其中,cv43_3负责探测最小的目标,而cv11_2负责探测最大的目标。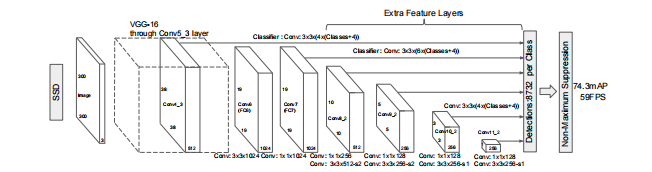
单次拍摄:SSD只需一次拍摄即可使用多框检测图像中存在的多个对象。多框:边界框回归技术检测器:对检测到的对象进行分类
固态硬盘如何工作?
SSD由两部分组成:主干和头部,主干模型通常是一个预先训练好的图像分类网络,如上面讨论的VGG作为特征提取器。SSD头部是添加到主干上的一个或多个卷积层,输出被解释为最后一层激活的空间位置上的对象的边界框和类别,而不是使用滑动窗口(稍后我们将解释滑动窗口),SSD使用网格来划分图像,并让每个网格单元负责检测图像区域中的对象,而不是使用滑动窗口(我们将在后面解释滑动窗口),SSD使用网格对图像进行划分,并让每个网格单元负责检测图像中该区域中的对象,而不是使用滑动窗口(稍后我们将解释滑动窗口),SSD头部只是添加到该主干上的一个或多个卷积层,输出被解释为最后一层激活的空间位置上的对象的边界框和类别。如果不存在任何对象,则将其视为背景类,并忽略位置。每个网格单元都可以输出它所包含的对象的位置和形状。如果在单个图像中有许多相同实例的对象怎么办。这就是锚箱发挥作用的地方。锚定框是指定了多个锚点/先前的框的简单框,这些框是预定义的,并且在栅格单元格中具有固定的大小和形状。在此基础上,我们能够在一幅图像中检测出多个目标,并不是所有的目标都是正方形的。有些更长,有些更宽,程度不一。SSD架构允许预定义锚盒的纵横比来说明这一点。Ratios参数可用于指定在每个缩放/缩放级别与每个栅格单元关联的锚定框的不同纵横比。
锚定框没有必要与栅格单元具有相同的大小。我们可能会对在网格单元中查找更小或更大的对象感兴趣。ZOOMS参数用于指定锚定框需要相对于每个栅格单元格放大或缩小多少。
滑动窗
滑动窗口是一个固定宽度和高度的矩形区域,它在每个窗口的图像上滑动,我们通常会选择窗口区域并应用图像分类器来确定窗口是否有我们感兴趣的对象。
匹配策略
在训练过程中,我们需要确定哪些缺省框对应于地面真相检测,并相应地训练网络。我们首先将每个基本事实框与具有最佳Jaccard重叠的默认框进行匹配(就像在MultiBox中一样)。与MultiBox不同,我们然后将默认框与Jaccard重叠大于阈值(0.5)的任何基本事实进行匹配。这简化了学习问题,允许网络预测多个重叠的默认框的高分,而不是要求它只选择重叠程度最大的一个。
硬性负挖掘
匹配后,我们可以看到训练示例中的正默认框和负默认框之间存在明显的不平衡。我们不使用所有的负面示例,而是使用每个默认框的最高置信度损失对它们进行排序,并选择最上面的示例,以便负面和正面之间的比率最多为3:1
非最大抑制(NMS)
考虑到推理时在固态硬盘的正向传递过程中生成的大量方框,有必要通过应用一种称为非最大抑制的技术来修剪大部分边界框:通过使用0.01置信阈值,我们可以过滤删除大多数方框。然后,我们应用每类Jaccard重叠为0.45的NMS,并保留每个图像的前200个检测。这确保网络只保留最可能的预测,而删除噪音较大的预测
我希望你喜欢这篇文章:)
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/06/16/%e5%8d%95%e7%82%ae%e5%a4%9a%e7%9b%92%e6%8e%a2%e6%b5%8b%e5%99%a8ssd%e5%ae%9e%e6%97%b6%e7%9b%ae%e6%a0%87%e6%a3%80%e6%b5%8b%e6%8a%80%e6%9c%af%e6%98%af%e5%a6%82%e4%bd%95%e5%b7%a5%e4%bd%9c%e7%9a%84/
