
数据往往介于最先进的计算机视觉机器学习项目和另一个实验之间。不幸的是,没有广泛采用的行业标准来选择最好和最相关的基准。
想象一下,如果您正在研究一种新的计算机视觉算法,您将如何为您的算法选择正确的基准?你会自己去取吗?找到被引用最多的基准吗?您如何处理许可或许可问题?您在哪里托管这些大型数据集?
由于经常选择一个好的基准所涉及的所有复杂性,您无法获得您的模型应该能够实现的结果。这个问题只会随着计算机视觉产生的数据量和复杂性的增加而增加,因为计算机视觉数据集不再是简单的猫和狗。目前,数据集变得越来越复杂,其中包括汽车在城市中行驶等复杂任务的图像。
反思如何为您的下一个机器学习任务找到完美的计算机视觉数据集,可以让您极大地改进计算机模型的结果。情况就是这样,因为拥有正确的数据集基准使您能够评估和比较机器学习方法,以找到最适合您的项目的方法。
在机器学习中,基准是比较工具和平台以确定行业中表现最好的技术的实践。基准测试用于使用特定的指示器来测量性能,从而产生一个度量,然后将该度量与其他机器学习方法进行比较。
拥有正确的数据集基准意味着什么?
现在您可能会问自己,有没有好的或不好的数据集基准,您如何区分它们呢?这两个问题在机器学习社区中都是重要且被低估的问题。
在这篇博客中,我们将回答这些问题,以确保在您为创建完美的机器学习模型所投入的所有研究和工作之后,它达到了它所能达到的潜力!
良好的基准
最近,许多公开可用的真实世界和模拟基准数据集从一系列不同的来源涌现出来。然而,源之间的组织和作为标准的采用一直是不一致的,因此,许多现有的基准缺乏多样性来有效地基准计算机视觉算法。
好的基准数据集允许您在直接和公平的比较中评估几种机器学习方法。然而,这些基准有一个共同的问题,那就是它们不能准确地描述现实世界。
因此,在流行的计算机视觉基准中排名靠前的方法,当在创建它们的数据或实验室之外进行测试时,性能低于平均水平。简而言之,许多数据集基准并不是对现实的准确描述。
好的计算机视觉基准数据集将反映您正在开发的模型的真实应用程序的设置。ObjectNet是一个有目的地创建的图像库的示例,以避免在流行的图像数据集中发现的偏差。ObjectNet创建背后的目的是反映人工智能算法在现实世界中面临的现实。ObjectNet
不出所料,当几个最好的对象检测器在ObjectNet上进行测试时,它们的性能显著降低,这表明需要更好的数据集基准来评估计算机视觉系统。
错误的基准
如果好的计算机视觉基准数据集提供了真实世界的公平表示,您能猜出一个差的计算机视觉基准数据集的特征是什么吗?
主要包含在理想条件下拍摄的图像的基准会偏向完美和不切实际的条件。因此,他们不足以处理现实世界中的混乱。
例如,使用ImageNet制定的数据集基准测试偏向于您会在博客中在线找到的对象的图片,而不是现实世界中的对象。
因此,虽然ImageNet是一个流行的计算机视觉数据集,但其数据库中的图像并不能充分反映现实,因此,ImageNet不是最好的计算机视觉基准数据集。
存在哪些类型的数据集基准?

对于不同的任务,有许多类型的数据集基准。例如,分割、场景理解和图像分类都需要不同类型的基准。
虽然您现在已经知道如何自己区分好的基准测试和不好的基准测试,但我们还是想为您提供一些用于细分、分类和场景理解的最佳基准测试的列表。
希望有了这些列表,您可以立即用您的计算机视觉模型启发世界,并有一个可以比较基准的参考,以便更好地将基准分类为好的或坏的。
用于细分的最佳数据集基准
- 伯克利分部数据集和基准(链接)
- KITTI语义分割基准(链接)
分类的最佳数据集基准
- ObjectNet基准图像分类(链接)
场景理解的最佳数据集基准
- ADE20K Val(链接)的场景理解
- 语义场景理解中的场景理解挑战被动驱动&地面真实定位(LINK)
为什么数据集基准如此重要?
由于有如此多类型的数据集基准,为每个数据集创建足够的高标准基准是可以理解的挑战。
但是,这样做是至关重要的,因为这些基准测试允许您查看您的机器学习方法如何学习基准数据集中已被接受为标准的模式。
拥有一个准确描述现实的计算机视觉数据集是具有挑战性的,这已经不是什么秘密了,因为数据集缺乏多样性,而且经常在理想的条件下描绘图像或视频。
也许为了建立更好的计算机视觉机器学习模型,在制定数据集基准时,我们需要在组织之间进行更多的协作。否则,最流行的数据集将有许多基准,而鲜为人知的数据集几乎没有基准可用。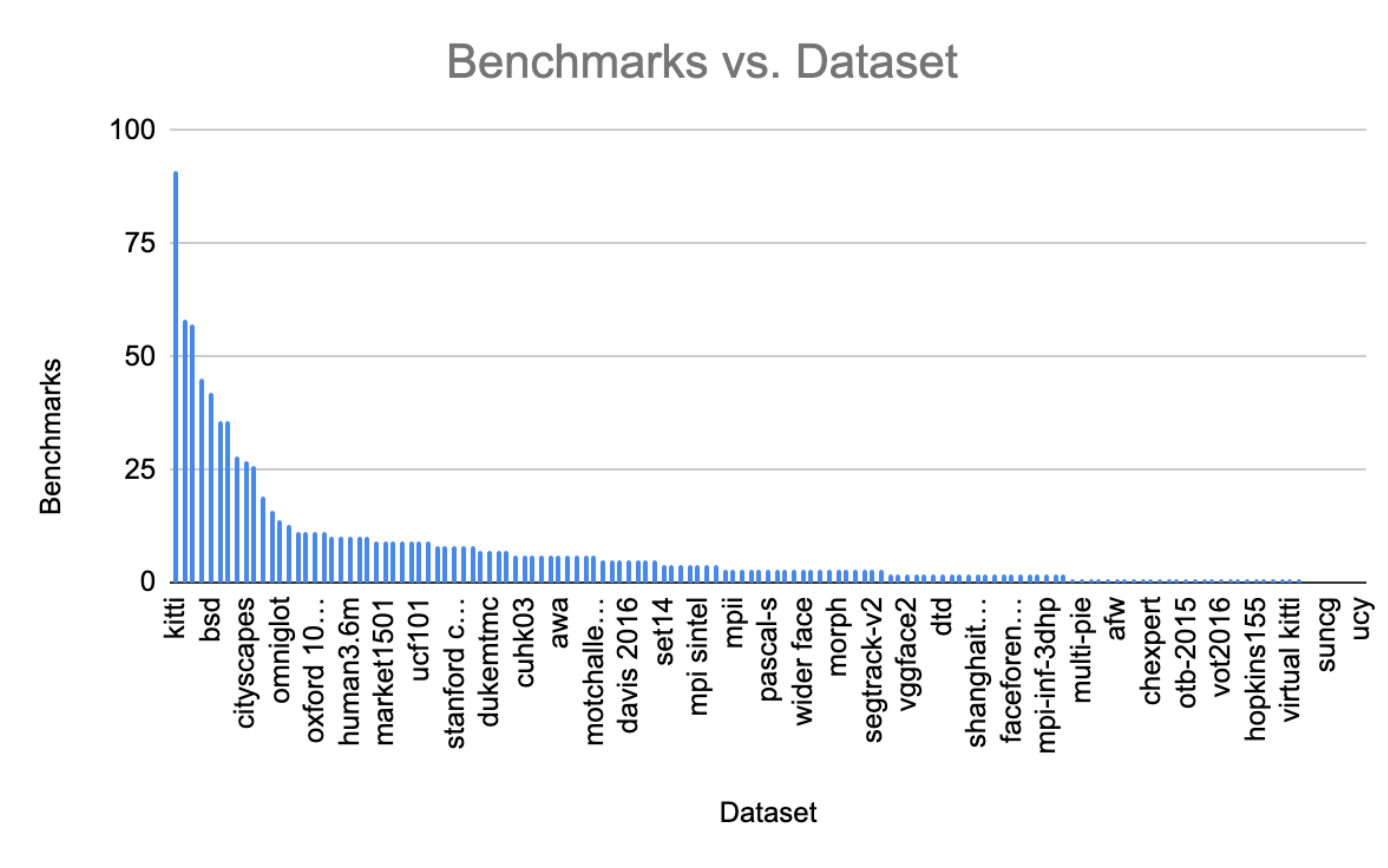
上面的直方图中显示的趋势说明了流行的数据集是如何为它们制定了更多基准的。由于缺乏基准而局限于最受欢迎的数据集,这使得获取模型上使用的数据集的多样性和对现实的准确描述变得更加困难。
然而,数据集优化公司Activeloop是一个用于创建一组集中且多样化的基准数据集的解决方案。Activeloop
像Activeloop这样的工具可以通过集中存储数据集和版本控制来实现数据集协作,让工程师能够创建最佳的计算机视觉数据集基准来开发他们的下一个最先进的模型!
此外,由于没有存储非结构化数据集的行业标准,因此很难从非结构化数据中提供有价值的见解。Activeloop的简单性允许许多人使用它,因此它正在成为存储非结构化数据集的行业标准。它的受欢迎程度使其成为协作创建数据集基准的明显工具。
此外,Activeloop不需要花费数小时甚至数天的时间来预处理数据集,只需集中执行一次预处理步骤,然后将其上传到Activeloop以供其他人用于制定基准。
显然,从非结构化数据生成的业务洞察力正变得越来越有价值。然而,随着计算机视觉数据生成的增加,计算机视觉基准不能以相同的速度生成。
为了继续开发最先进的计算机视觉机器学习项目,机器学习开发人员之间必须进行有效的合作,以制定更好的计算机视觉基准。Activeloop可以促进这种高效的协作。
最初发表于https://www.activeloop.ai.https://www.activeloop.ai
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/06/16/%e7%bc%ba%e4%b9%8f%e8%89%af%e5%a5%bd%e7%9a%84%e8%ae%a1%e7%ae%97%e6%9c%ba%e8%a7%86%e8%a7%89%e5%9f%ba%e5%87%86%e6%95%b0%e6%8d%ae%e9%9b%86%e6%98%af%e4%b8%80%e4%b8%aa%e9%97%ae%e9%a2%98-%e8%ae%a9%e6%88%91/
