
作者:崔剑峰,Aakaash Radhoe
介绍和激励
在这个项目中,我们为一个在零售店工作的名叫Tiago[1]的机器人设计了一种解决3D对象检测问题的策略。蒂亚戈的整个工作场景是识别、提货并交付给客户,所以这个项目作为它的感知模块。它将能够识别图像视图中出现的目标产品,计算其3D姿势,并将此信息传递给其他模块。在我们的例子中,零售店有5种产品需要识别:“饼干”、“可可拉”、“品客2”、“雪碧”,它们的编码ID从0到4。
蒂亚戈配备了一台RGB-D摄像机。因此,基本上我们的策略是在我们的定制数据集(使用COCO格式)上训练一个更快的R-CNN,并将其用于2D对象检测。每个目标的2D边界框可以生成一个3D观察锥体,通过它我们可以从所有可能的候选对象中过滤出对象点云。最后,通过使用PCL库将过滤后的“干净”点云馈送到圆柱体拟合检测器来计算3D姿态。这之所以行得通,是因为我们事先知道这五种产品都是圆柱形的。
现在让我们一步一步地来做这项工作吧!
设计:2D对象检测
该模型
我们首先开始用代码四处寻找物体检测算法。我们遇到了几个不错的选择,比如YOLOv4,SqueezeDet和Fetter R-CNN。起初,我们选择使用YOLOv4,但是当在模拟中实现该算法时,由于它的计算成本太高,并且在给定的时间范围内不能重现,所以我们选择使用YOLOv4。因此,我们选择了速度较快的R-CNN算法,该算法训练简单,速度快,在仿真中可以实现实时检测。
速度较快的R-CNN由特征提取网络组成,特征提取网络通常是预先训练好的CNN。然后是目标检测系统,该系统由两个模块组成,这两个模块都是可训练的。第一个模块是区域提案网络(RPN),它生成目标提案。第二个模块预测对象的实际类。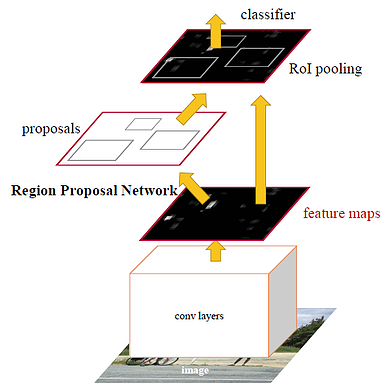
在速度更快的R-CNN中,主播是非常重要的,一个主播就是一个盒子。这些锚点用于以不同的大小和比例提供一组预定义的边界框。更快的R-CNN的默认设置是一张图像有9个锚框。锚点用于捕获我们要检测的特定对象类的比例和纵横比。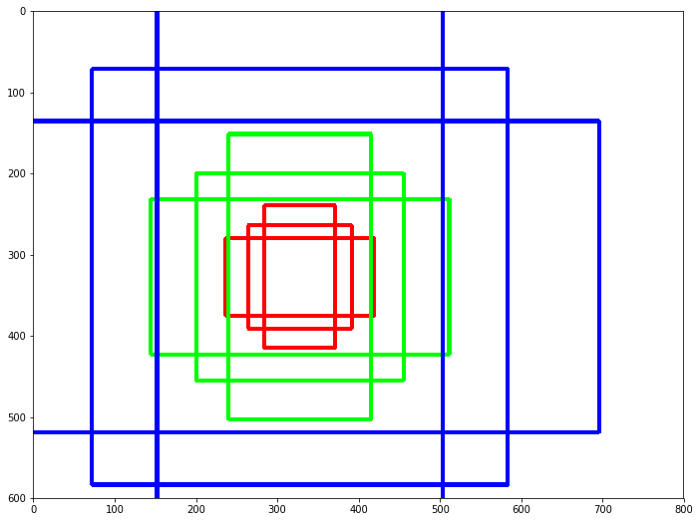
区域提案网络(RPN)将输出提案(锚),这将通过分类器和回归器来检查对象的出现。在RPN之后,提案的规模各不相同。对于不同大小的区域,我们将获得不同大小的CNN专题地图,这将使其工作效率低下。为了解决这个感兴趣的区域,使用了池化,这样就将特征地图缩小到相同的大小。
我们用于速度更快的R-CNN的代码来自open-mmlab。此工具箱基于PyTorch。我们使用的速度更快的R-CNN网络只对锚框进行了较小的编辑。此模型使用的锚框是8,而不是默认的9。
我们使用此工具箱根据我们选择和注释的产品图像对网络进行培训。但在此之前,我们需要转换生成的数据集格式。Labelme分别为每个图像样本生成JSON文件,现在为了将数据集提供给训练管道,我们使用此包[3]来生成单个COCO数据格式的JSON文件。与包含所有图像的文件夹配对,它集成了有关我们的数据集的所有信息。
准备数据
对于图像的采集,我们可以在ROS中运行Tiago,以较低的频率订阅相机发布的图像,然后通过过滤找出代表这五个物体的想要的图像。我们挑选了121张图片,并开始制作定制数据集。我们使用的是labelme[2],这是一个图形图像标注工具。通过在图像上手动绘制多边形,并用不同的类别名称对其进行标注,为每个图像生成一个JSON文件,其中存储了这些多边形的坐标和标签信息。在图4中,显示了我们如何使用labelme工具标记数据。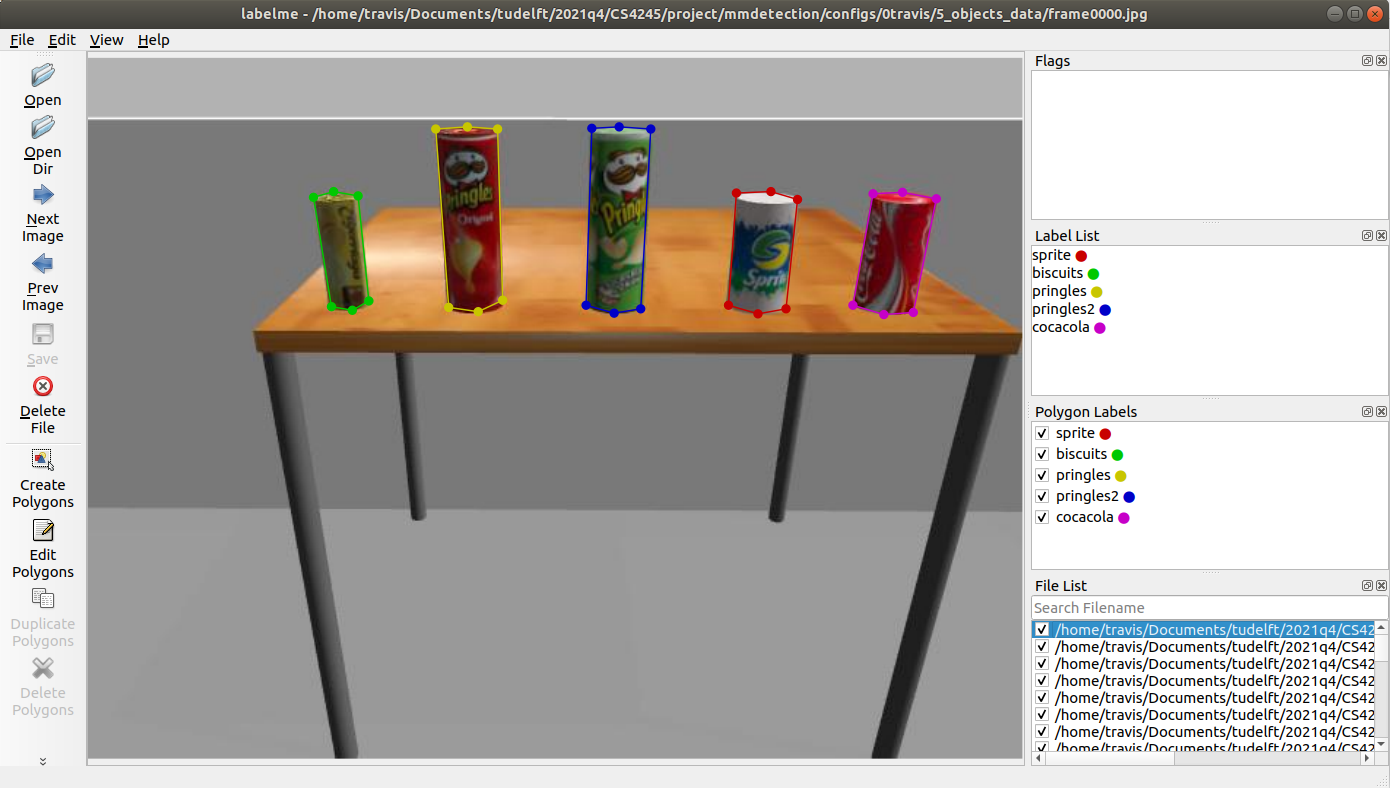
训练模型
随着数据的准备就绪,我们开始训练速度更快的R-CNN。我们使用NVIDIA GTX1650对网络进行了大约15分钟的培训。然后将该模型保存并稍后加载到ROS检测模块中。训练过的网络另存为.pth文件,可以在Github上找到。
结果
模型经过训练后,我们继续在测试集上验证模型。其中我们得到了以下结果: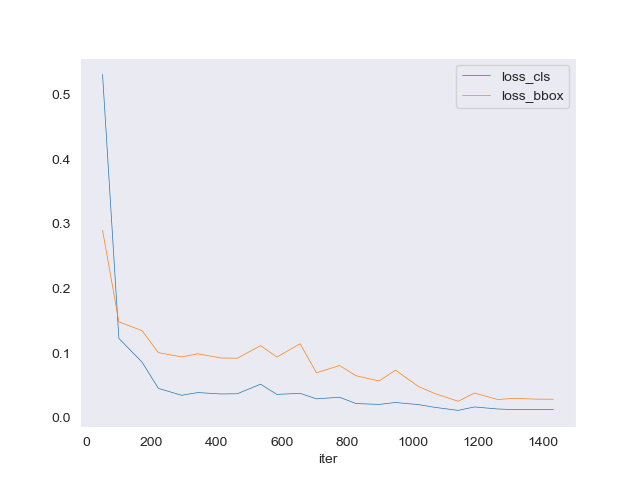
在图5中,绘制了CLS和BBOX损失的损失函数。在这里,我们可以看到CLS损失在900次迭代左右收敛,BBox损失在1250次迭代后收敛。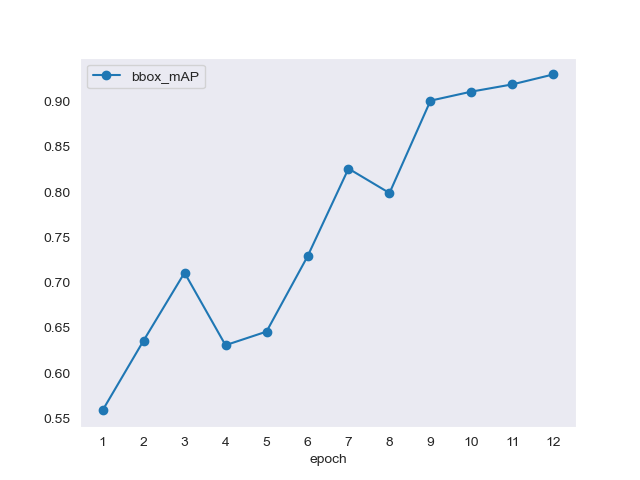
在图6中,为每个时期绘制了BBox映射。在12个历元时,BBox映射为1。这些结果足以在仿真中继续和实现模型。
在ROS中部署网络
现在是时候把魔力带给Ros了。通过训练更快的R-CNN模型并能够检测到所有产品,我们在一个通用的ROS包中实现了这一点,所以我们可以在实时的Gazebo模拟中运行这一点。ROS包设计用于在ROS中使用mmDetection运行2D对象检测器的推理,该包可以在[4]中找到。在那里对其安装和使用进行了说明。
来自所部署的网络的推断结果将是包含分别表示每个对象的检测到的边界框的数组的列表。每个有效数组包含5个元素:左上角和右下角的x和y像素坐标,以及预测置信度。然后使用结果生成标准的ROS消息`Detection2D`:
def generate_obj(self, result, id, msg):
obj = Detection2D()
obj.header = msg.header
obj.source_img = msg
result = result[0]将所有检测到的Object附加到一个`Detection2DArray`中后,打包后的消息就可以发布到ROS上,供其他模块使用。
另一个问题是,用于将图像格式转换为ROS的CvBridge库在Python3中不可用。这可以通过使用NumPy的技巧巧妙地解决:
im = np.frombuffer(msg.data, dtype = np.uint8).reshape(msg.height, msg.width, -1)当模拟运行并在Tiago机器人上使用时,这些是我们得到的结果。在图7中,我们可以看到网络如何检测呈现给机器人的项目并显示预测置信度。
现在,我们已经成功地在ROS中部署了一个2D目标检测网络!现在,让我们进一步使用它来检测3D对象。
设计:3D对象检测
我们将当前的能力扩展到3D对象检测的策略非常简单。Tiago可以使用RGB-D相机生成原始点云,我们知道图像像素可以被视为实际3D环境点在图像平面上的2D投影。因此,从最后一个部分获得的2D边界框可以生成3D截体,它将整个原始点云限制到我们感兴趣的某个区域。我们简单地假设位于该区域中的点形成目标3D对象。这样,我们就可以用过滤从所有原始点中提取出一小簇对象点云。
事实上,我们发现该策略与本文提出的用于3D目标检测的F-PointNet非常相似[9]。如下图所示,基本思想也是将2D区域挤出到3D视图锥体。但是,我们不使用PointNet或其他3D对象检测网络来生成3D边界框,而是在本任务中使用拟合柱面的点云算法来计算目标对象的3D姿态。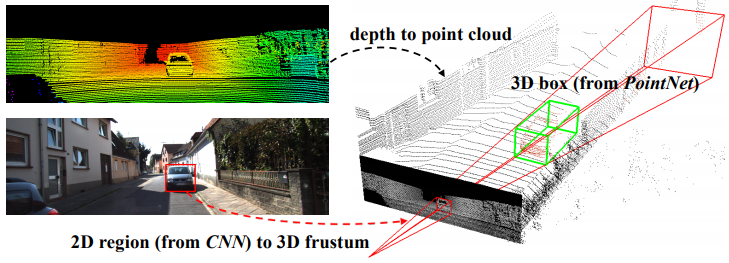
过滤将对象点云移出
要实现这一点,我们可以通过从存储在ROS pointcloud2消息中的数据索引所需的点,并将它们打包到我们新定义的对象点云消息中,来破解ROS pointcloud2消息。下面显示了代码中的一小段代码:
sensor_msgs::PointCloud2 pcs_filtered;
int POINT_STEP = latestPointClouds.point_step; // NOTE: 32, actually
size_t tc_u_min = int(tc_u — tc_size_u / 2) * POINT_STEP;
size_t tc_v_min = int(tc_v — tc_size_v / 2);
size_t tc_u_max = tc_u_min + tc_size_u * POINT_STEP;
size_t tc_v_max = tc_v_min + tc_size_v;请注意,这里已经找到并选择了目标对象的边界框。变量`tc_u`、`tc_v`、`tc_size_u`、`tc_size_v`是质心的x、y坐标以及x、y方向的大小。这四个计算变量表示原始点云数据字段的下界和上界指数限制。然后我们构建过滤后的点云:
pcs_filtered.header.frame_id = latestPointClouds.header.frame_id;
pcs_filtered.header.stamp = ros::Time::now();
pcs_filtered.height = tc_size_v;
pcs_filtered.width = tc_size_u;
pcs_filtered.fields = latestPointClouds.fields;
pcs_filtered.is_bigendian = latestPointClouds.is_bigendian;
pcs_filtered.point_step = POINT_STEP; //32
pcs_filtered.row_step = POINT_STEP * tc_size_u;
pcs_filtered.is_dense = latestPointClouds.is_dense;现在`pcs_filtered`包含了我们想要的过滤干净的点云!我们现在可以计算它的姿势了。
计算3D姿势
由于这五个对象都是圆柱形的,我们可以在这里简单地使用PCL库中的圆柱体分割方法[5]。此外,PAL Robotics已经使用PCL[6]提供了气缸检测器节点。有了这个好处,我们只需要用我们的代码定义它的通信。分段代码为:
pcl::SACSegmentationFromNormals seg;
pcl::PointIndices::Ptr inliers(new pcl::PointIndices); 圆柱体检测器可以将输入对象的点云拟合为圆柱体,也可以返回其质心的姿态。这就是我们想要的!现在管道已经完工了!
通信概述
为了将所有部分集成到ROS系统中并使它们在模拟中工作,在这一部分中,我们展示了这些ROS节点之间的总体通信,以给出该策略如何工作的清晰数据流程图。请参见下图。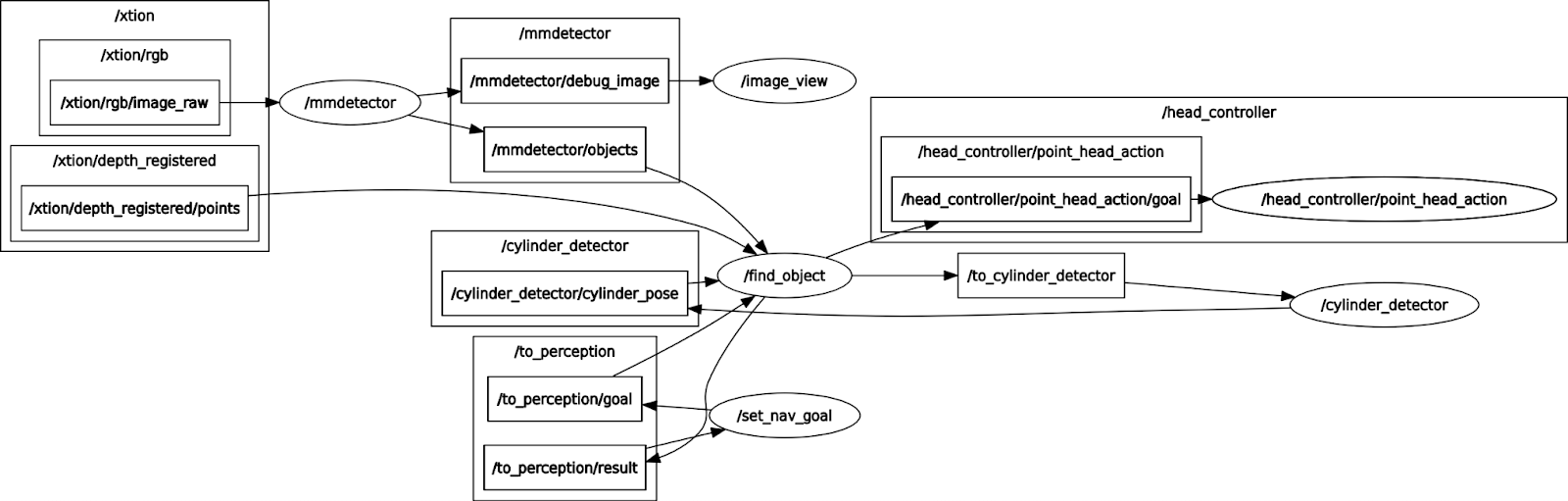
我们有find_object和mmector节点。FIND_OBJECT是为了提亚哥人的感知。它从set_nav_target接收对象ID,并返回此目标对象的3D姿势。
节点mm检测器在来自相机的RGB图像上利用较快的R-CNN来计算对象2D边界框,并将它们发布在mmDetector/Objects上以供find_object使用,并且还将调试图像发布在mmDetector/debug_image上以用于image_view以可视化它。在find_object接收到来自set_nav_target的调用后(感知模块启动),它订阅2D边界框以及整个原始点云,对其进行处理(过滤输出位于2D边界框生成的圆锥体中的点云),并将这个“干净”的过滤后的点云发布到_Cylinder_Detector主题上。圆柱体检测器处理该点云,计算该对象的3D姿势并将其发布。请注意,find_object已经在持续监视3D姿势是否可用,因此现在它获得了3D姿势,并将该结果返回给set_nav_target(感知模块完成了任务)。
结果
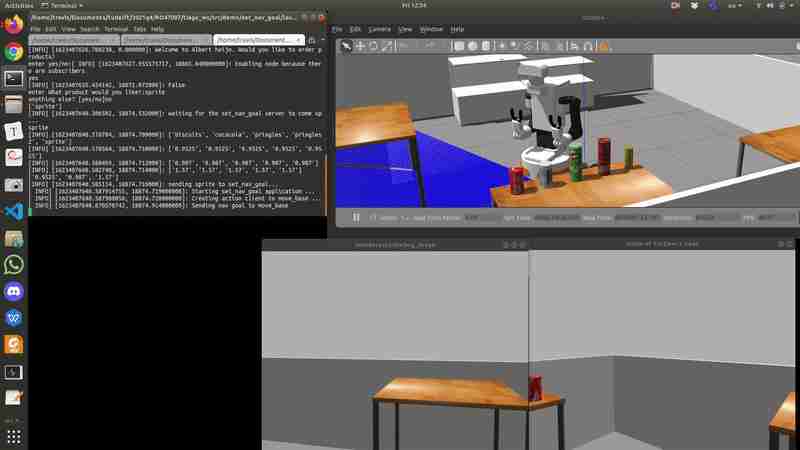
整个视频可以在:https://drive.google.com/file/d/1VqTg8dFCKsVXLAXaDL9LmUPcT7icDjg0/view?usp=sharing,找到,其中3D对象检测任务是识别精灵并计算其3D姿势。在视频中,您可以看到两个窗口在运行:在Tiago++的头部内部显示当前的摄像机视图,以及显示由速度更快的R-CNN计算出的调试图像的mmDetector/debug_image。调试映像窗口运行较慢(1 Hz),因为此过程会给您的GPU带来压力,因此我们调整了此频率。在Tiago移动到桌子上的5个对象前面之后,它向下看,这是一个预定义的行为,因为我们假设这些对象将大致位于桌子上,低于原始图像视图。然后,Tiago查看目标对象(在本例中为精灵)并计算3D姿势。在1:48,您可以看到RGBD相机获得的整个点云(上面绘制了颜色)。在2:14可以看到过滤后的“精灵”点云,在2:49可以看到精灵的计算3D姿势。感知部分可以很好地识别它想要找出的对象。下面是视频中显示精灵点云的动画。https://drive.google.com/file/d/1VqTg8dFCKsVXLAXaDL9LmUPcT7icDjg0/view?usp=sharing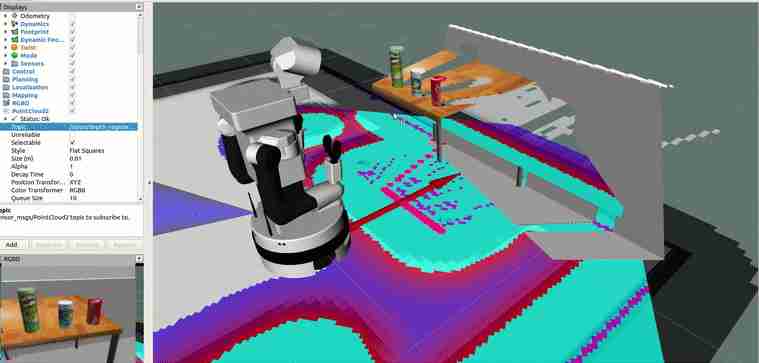
结论
回顾这个项目,我们对结果非常满意。使用较快的R-CNN进行目标检测是成功的,并且表现得非常好。在ROS中的实现也进行得很顺利。随着更快的R-CNN网络的使用,实时检测购物物品和计算3D姿势成为可能。因此,我们能够实现我们想要实现的一切。然而,还有一些我们想要做的改进,比如增加更多的项目,或者建立一个计算成本更低的网络。如果从头开始复制速度更快的R-CNN并在ROS中再次实现它,那也会很有趣。并将结果相互比较,看看我们在哪里可以进一步改进该模型。但由于时间限制,我们使用了速度更快的R-CNN网络,并在ROS中实现了这一点。最后,我们对Tiago目标检测的结果和实现相当满意。
来源:
使用以下链接可以找到此项目的所有代码:使用的较快的r-cnn代码可在:https://github.com/open-mmlab/mmdetection找到我们实现较快r-cnn的ROS包可在:https://github.com/jianfengc11/mmdetection_ros找到https://github.com/open-mmlab/mmdetection https://github.com/jianfengc11/mmdetection_ros
[1]https://pal-robotics.com/robots/tiago/https://pal-robotics.com/robots/tiago/
[2]https://github.com/wkentaro/labelmehttps://github.com/wkentaro/labelme
[3]https://github.com/Tony607/labelme2cocohttps://github.com/Tony607/labelme2coco
[4]https://github.com/jianfengc11/mmdetection_roshttps://github.com/jianfengc11/mmdetection_ros
[5]https://pcl.readthedocs.io/projects/tutorials/en/latest/cylinder_Segmentation.html?高亮显示=柱面https://pcl.readthedocs.io/projects/tutorials/en/latest/cylinder _segmentation.html?highlight=cylinder
[6]https://github.com/pal-robotics/tiago_tutorials/blob/kinetic-devel/tiago_pcl_tutorial/src/nodes/cylinder_detector.cpphttps://github.com/pal-robotics/tiago_tutorials/blob/kinetic-devel/tiago_pcl_tutorial/src/nodes/cylinder_detector.cpp
[7]任山,何凯,格希克,R.,孙军(2016)。更快的R-CNN:基于区域建议网络的实时目标检测。https://arxiv.org/abs/1506.01497https://arxiv.org/abs/1506.01497
[8]https://medium.com/@smallfishbigsea/faster-r-cnn-explained-864d4fb7e3f8https://medium.com/@smallfishbigsea/faster-r-cnn-explained-864d4fb7e3f8
[9]Charles,RQ.,魏,L.,陈霞,W.,Hao,S.,Leonidas,J.G.(2018年)RGB-D Data https://arxiv.org/abs/1711.08488中三维目标检测的Frustum PointNethttps://arxiv.org/abs/1711.08488
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/06/16/tiago%e6%9c%ba%e5%99%a8%e4%ba%ba%e7%9a%843d%e7%9b%ae%e6%a0%87%e6%a3%80%e6%b5%8b%ef%bc%9a%e4%bd%bf%e7%94%a8%e6%9b%b4%e5%bf%ab%e7%9a%84r-cnn%e7%bd%91%e7%bb%9c/
