
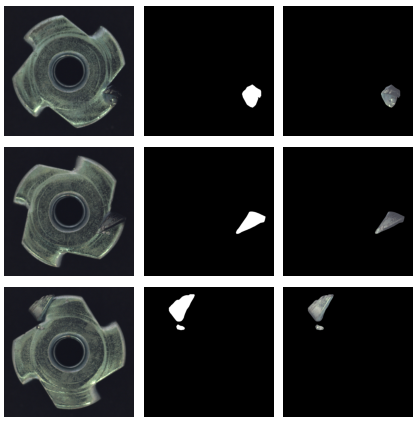
计算机视觉中的图像分割就是获取一幅图像,将每个像素标记为属于某一类,然后输出一个与输入图像大小相同的像素级标记数组。此输出称为“分段掩码”。上图中的是二进制掩码,因为每个像素只能有两个标签中的一个-1或0。
语义切分与实例切分
为了理解语义分割和实例分割之间的区别,让我们以上面的示例集为例,我们可以看到每个项目有两个明显分离的缺陷区域。在语义分割中,标记没有考虑到这一点,两个缺陷区域的像素都将标记为1,区域的睡觉标记为0(顶部RT图像)。
而在实例分割中,典型地,每个缺陷区域的像素将具有不同的标签。而法线区域仍将具有标签0(底部RT图像)。
在这篇文章中,我将解释自动编码器的主要思想,特别是UNET架构,这将是后续实现演练中使用的架构。
自动编码器
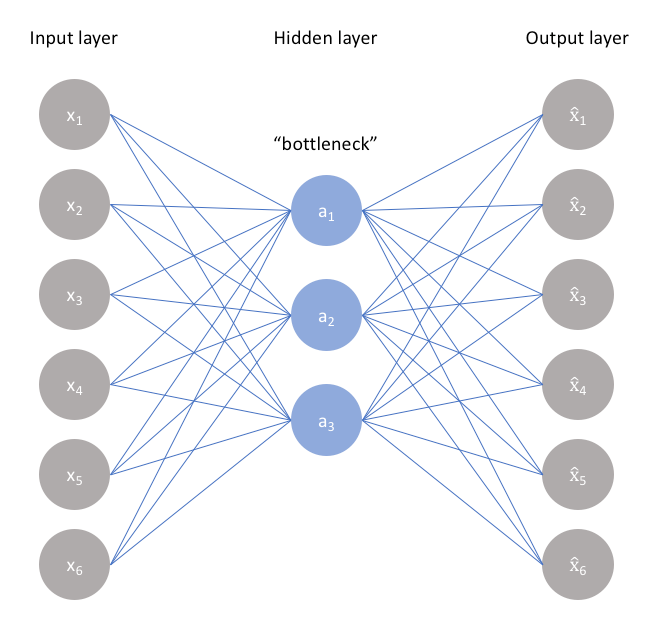
自动编码器的想法是利用神经网络以一种无监督的方式学习,即图像中结构的表示(如果存在)。
它的具体意思是-通过在网络中创建瓶颈,并使用有效地为网络的输入图像和输出之间的差的损失函数,我们迫使网络学习原始输入的压缩知识表示。如果输入特征彼此完全独立,则这种对输入的压缩使得输出仍然是原始的近距离重建将是困难的。
然而,如果输入中存在结构-即输入特征之间存在相关性-则可以使用瓶颈来学习相同的结构,并且瓶颈中神经元的激活将是更大的原始输入向量的压缩向量表示。
打个比方,想一想,如果我强迫你在10分钟内总结这部长达3小时的“复仇者联盟”电影,你会怎么做。你会选择电影中最重要的时刻,同时仍然保持基本的故事主线。所以3小时的电影是输入,10分钟的限制是瓶颈,你选择用来填充这10分钟的电影瞬间将形成电影的压缩表示。你想要确保的故事情节能在这10分钟内传达出你想要建立的基本结构。
自动编码器如何帮助进行分段?
将上述想法学习表示法进一步扩展-即,如果我们已经学习了一种图像类型的良好表示,该模型可以相当好地重建类似的图像,除非图像应该包含不一致。
所以,我们训练一个模型来学习尽可能好地重建特定类型的图像,然后我们给模型一个新的图像,如果重建的图像与图像不是很相似,这意味着要么你给了模型一个完全不相关的图像,要么图像与模型学到的不一致。
联合国教科文组织(UNET)的体系结构
UNET的名字来源于这样一个事实,即神经网络的表示形式看起来像字母“U”,如下所示。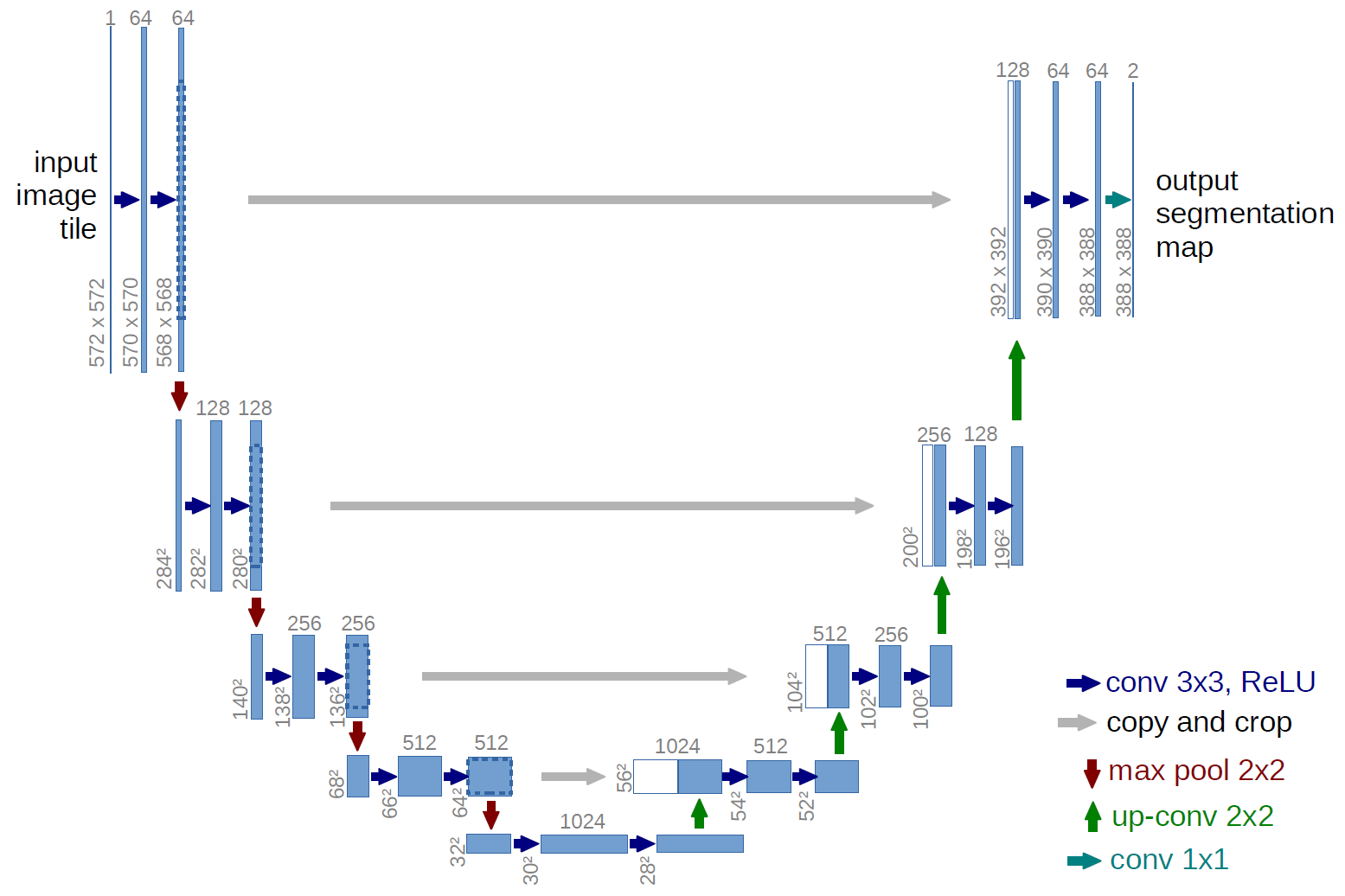
UNET是一种特定类型的自动编码器。
这个想法是系统地收缩输入图像,方法是在每一步将维度减半,通道加倍,直到表示层,然后以对称的方式进行放大-即,将维度加倍,通道减半。
收缩/下采样: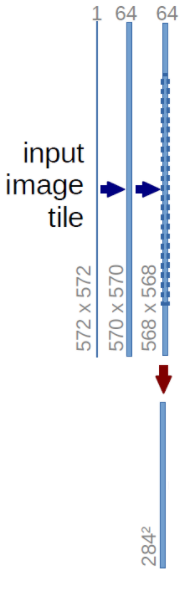
如上所述,每一级别的收缩都是使用卷积和合并操作的组合来实现的。
对572×572的单输入图像进行两次卷积以提取特征表示,然后使用汇聚层来实现收缩。
上采样和级联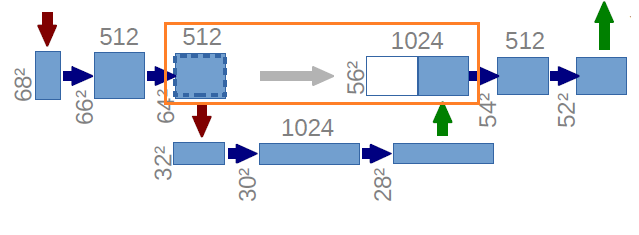
位于“U”形网络中心的层形成表示层。其输出为28x28x1024。上采样步骤将维度加倍至56×56,并将通道从1024减半至512。
请注意使用灰色箭头表示的操作。在维度从28×28增加一倍至56×56之后,这些维度将与在下采样阶段学习的相同级别的特征连接在一起,以保留“上下文”。
神经网络的层次越深,它捕获的特征就越抽象。请看下图中最左边的一列。因此,连接来自“U”网同一层的要素是很重要的。
下图中的第二列和第三列是使用和不使用串联操作训练的模型的上采样层的激活。你注意到什么了吗?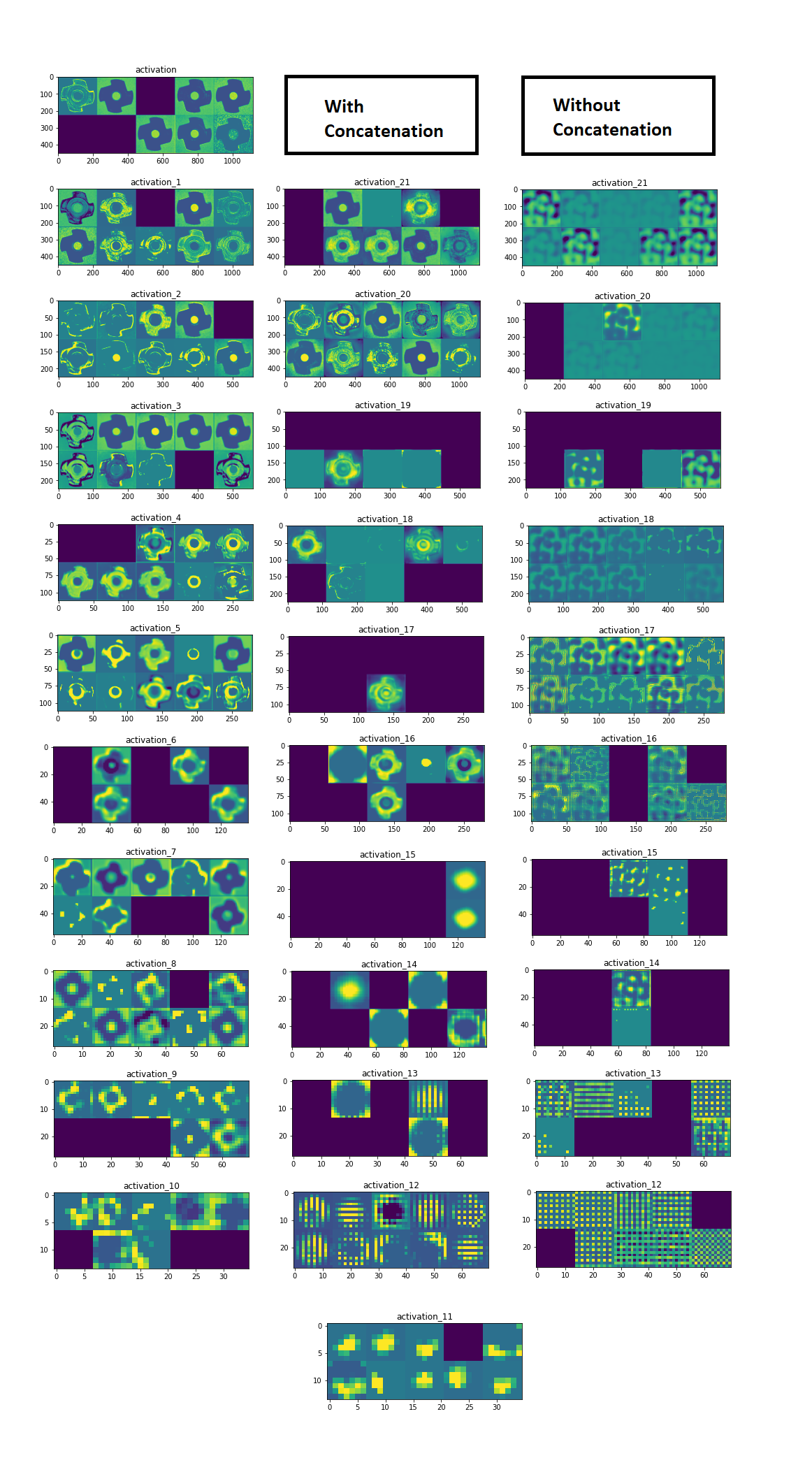
右侧的解码器无法将特征放置在图像的全局上下文中。而中间的解码器能够。
感谢您的阅读!下一篇文章见。
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/06/19/%e7%94%a8%e4%ba%8e%e6%a3%80%e6%b5%8b%e9%a1%b9%e7%9b%ae%e7%bc%ba%e9%99%b7%e7%9a%84%e8%af%ad%e4%b9%89%e5%88%86%e5%89%b2%e3%80%82%e7%ac%ac%e4%b8%80%e9%83%a8%e5%88%86%ef%bc%9a/
