

在这篇博客中,我们提出了一种神经网络体系结构,它能够区分人们是否在实时设置中戴着口罩。这可能被用来监测人群中没有戴口罩的个人,这可能对许多不同的应用有用,比如研究病毒的传染性和用于监督目的。以计算机视觉中的图像识别为主题,介绍了如何使用非标准的自增强数据集对神经网络模型进行实际训练和测试的方法。给出了考虑网络结构的选择、数据的处理和排序以及训练过程的实施和结果所采取的步骤。
自从冠状病毒到来以来,视频监控和安全摄像机镜头等领域对口罩识别的需求迅速增加,因为预防戴口罩可能有助于减少病毒在人与人之间的传播[1]。深度学习技术已经在大数据集[2][3][4]中对人和人脸的面具进行分类和检测方面取得了令人满意的结果。为了在计算机视觉和深度学习领域获得进一步的实践理解,我们选择在尚未大规模使用的大学环境中使用和检查实时视频数据集[5]。[5]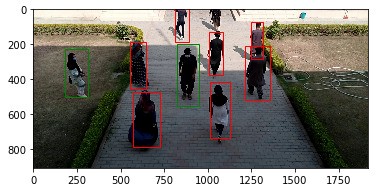
这个数据集的镜头包括一段视频,一系列图像,从安全摄像机的角度来看,来自路过的多个对象。这段视频的时长只有几分钟,包含4357个图像帧。每个帧都用边界框的坐标以及戴面具(MW)或不戴面具(NM)的状态进行注释。除此之外,不能看到脸部的人也被归类为不戴面具,例如当有人离开相机透视时。
因此,该数据集包含了我们检查对象检测部分和分类部分所需的所有信息,这两个部分都很有趣。本文的结构如下:
- 网络体系结构的选择和说明
- 数据集和数据处理
- 培训网络和结果
- 讨论和结论
我们研究的初步目标是用选定的数据集训练一个自组合神经网络管道。对数据进行转换和扩充,使其符合馈入网络的要求。对于神经网络本身,我们将检测任务和分类任务分解到两个独立的神经网络中,以便能够分别对每个神经网络进行微调。
为了专门化这个博客的范围,我们决定将重点放在分类任务上,在上图中可以看到它是“面罩分类器”。实现了不同的神经网络主干进行分类,并对它们的性能进行了相应的排序。通过这种方式,目标是向读者展示使用非标准数据集时要遵循的实际步骤,并在不同的神经网络中实现它。我们希望在我们遵循的过程中提供更多有价值的见解,并传递我们所学到的经验教训。
网络架构
考虑到我们选择的带或不带面罩的行人的数据集,我们选择将神经网络必须执行的检测和分类任务分成两部分。通过这种划分,目的是设计一条由两个神经网络组成的流水线,每个神经网络都经过优化,分别进行检测和分类。首先需要对图像中的每个人进行定位,这是通过用边界框注释图像中检测到的每个人来完成的。其次,必须对每个检测到的人进行分类任务,以确定一个人是戴着面具(MW)还是没有戴面具(NM)。我们最初的计划是将检测和分类部分结合起来,并同时实现这两个部分,以深入了解这两个部分。然而,我们的主要目标是建立一个能够对所选数据集的自我处理数据进行训练的网络。我们从以前的项目中了解到,最好从简单开始。因此,为了确保我们有足够的时间处理数据本身并产生结果,我们决定将重点放在这个两阶段方法的分类部分。
对于分类任务,使用并最终比较了以下网络:
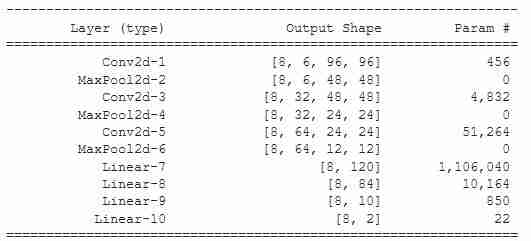
- 带最大合用的简单卷积网络(简单卷积):
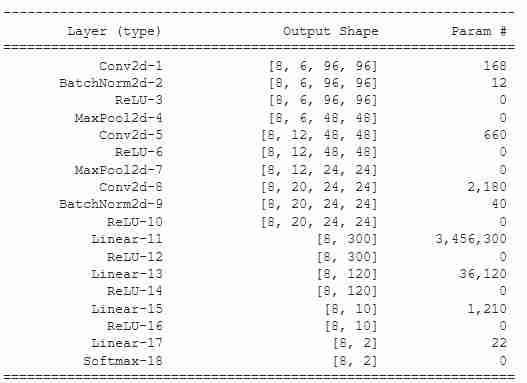
- 具有批归一化和重排的简单卷积网络(Conv+BN):
- [6]中定义的LENET-5:

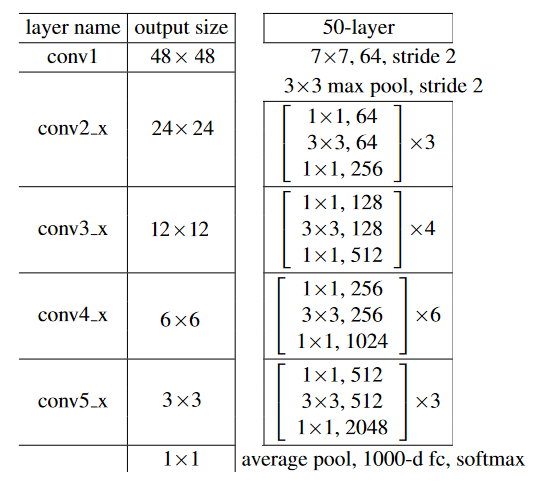
- RESNET-50,如[7]中所定义:
我们用交叉熵损失作为损失函数,用动量=0.9的随机梯度下降法定义学习率作为优化器。
数据处理
如前所述,我们倾向于设计一种流水线,其中第一步包括预测人的边界框的对象检测,而第二步包括实现预测边界框中的人是否戴着面罩的分类器。
因此,对于分类器,我们需要创建一个数据集,其中包含boudingbox注释内部的裁剪图像。对于每一帧,注释(作为XML元素树传送)具有如下所示的形式,并且具有可变的长度,取决于相关帧中检测到的人的数量。
为了处理这些数据,我们首先创建了一个列表,其中包含我们想要包含在集合中的帧。以及包含所有注释的Python字典。然后我们做了一个循环,循环遍历文件并检索每个检测到的人的边界框位置的坐标,并根据其分类NM或MW将其分配给其指定的数据集。
如下面两个不同的行中所示,裁剪的_in_no_ask和裁剪的_im_ask集合现在分别包含有蒙版和不带蒙版的人的图像。可以想象,作为看不到蒙版的人,裁剪的im_ask数据集要大得多。这将通过从该数据集中删除一定数量的图像来均衡。这些集合被分成训练集和测试集,按照时间帧顺序具有80%和20%的比率。此顺序对于防止高度相似的连续帧同时出现在训练集和测试集中是必要的。
由于使用简单的卷积网络的第一个训练周期的结果(粉色:训练精度,蓝色:测试精度)如下所示,我们得出结论,该网络是过拟合的。这种过拟合的一个原因可以发现,数据集由来自视频的许多连续帧组成,这就是为什么连续帧产生相似的裁剪图像的原因。正因为如此,网络很容易超负荷运行。另一个原因可以从这幅画的性质中找到。我们想要对一个人是否戴着口罩进行分类,但我们不是在面部区域周围裁剪图像-你会看到面膜-我们提供了整个人的图像,这使得网络有可能专注于面膜本身以外的其他图案。这就是为什么我们实现了一些数据增强。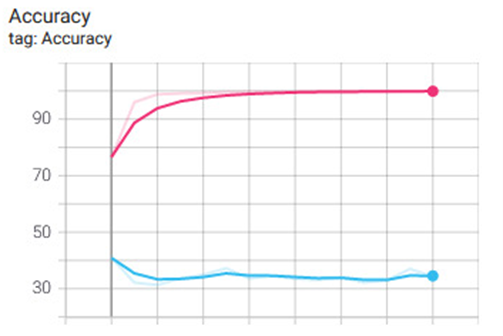
对于数据增强,我们首先通过提取i在[20,40,60]范围内的第i帧而不是数据集的每一帧来处理许多相似连续帧的出现。结果如图11和图12所示。这使得I=20,40时的过拟合较少,并使网络达到70-80%的精度。然而,对于每隔60帧提取帧的数据集,网络仍然是不可训练的。我们选择项目的其余部分来处理每隔40帧提取的数据集,从现在开始,我们将该数据集命名为40th_DataSet。
由于第40个数据集总共只包含大约400个实例,因此我们以在垂直轴上翻转每个实例的形式实现了数据扩充。由于现在存在两倍数量的实例和更多种类的数据集,我们应该会看到较少的过度拟合。不幸的是,数据增强并没有带来如图13和图14所示的精确度提升。在项目的其余部分中,我们继续使用普通数据集。
接下来,我们将比较BATCH_SIZE的不同值:[4,8,32,64]。下面是图15和图15所示的结果,由此我们得出结论,Batch_Size 8、32或64对于我们的网络就足够了。在项目的其余部分中,我们继续使用BATCH_SIZE 8。
接下来,我们将为我们的网络找到合适的学习率(简称LR)。我们比较了LR[0.01,0.005,0.001],结果如图17和18所示。从这些结果可以得出结论,在我们的情况下,学习速率对学习曲线影响不大。由于LR=0.001会导致更平滑的学习曲线,因此在项目的剩余部分中,我们将坚持使用此值。
现在,我们将该网络与发现的BATCH_SIZE=8、学习率=0.001的超参数、在每40帧提取的平面数据集与“简单卷积”网络LENET-5和RENET-50进行比较。结果如图19和20所示。我们得出结论,没有一个网络收敛到一个显值。此外,更复杂的网络ResNet-50和“Conv+bn”将导致比更简单的网络“Simple Conv”和LeNet-5更高的准确率。这可能是由于数据集的复杂性,因为与剩余图像相比,感兴趣的区域(即面罩)相当小,因此图像的大部分包含无用信息。
由此,我们得出结论,ResNet-50最终是更好的选择,尽管所有的网络都没有收敛到一个值。
讨论
当查看我们测试的不同网络的结果时,我们肯定地感到惊讶的是,在训练期间,准确率提高了,损失减少了,因为这是我们第一次在非标准数据集上成功实现分类器网络。这意味着我们使用的模型在某种程度上适合优化测试和培训结果,这是一个很好的收获。然而,仍然有一些结果是我们没有预料到的,这为建立这种网络的设置留下了改进的空间,当它们连接到某个数据集时。
这里要说明的第一件好事是,我们的主要目标之一是产生一个有效的分类网络,该网络展示了它成功训练的能力,并在测试集上展示了它。在追求这一目标的过程中,我们从一个网络“Conv+bn”开始,并对该网络的超级参数进行了优化,使其性能达到最佳。当我们后来将这个网络与其他网络进行比较时,这意味着随后出现的差异不是同等加权的,因为“Conv+bn”网络是优化的。这些超级参数后来被用于其他网络,根据定义,这给我们使用的第一个网络带来了不公平的优势。
其次,在观察训练过程的图表时,训练曲线和测试曲线之间存在很大的差距,这通常意味着模型在数据集上过拟合。我们试图通过从数据集中的视频中采样帧来缩小这一差距,以减少训练对非常相似的图像的影响。这一数据处理步骤在一定程度上起到了作用,但训练曲线和测试曲线之间仍然有相当大的差距,因此模型似乎仍然过拟合。一种可能的解释是,模型没有在正确的功能上进行培训。在现在的设置中,模型很容易误解像面罩检测这样的重要特征,因为边界框是放在人周围的,而不是放在脸周围的。此外,该模型仍在对许多非常相似的图像进行训练,因为视频只包含几分钟的镜头。这可能意味着数据集不够大,不足以有效地训练分类器模型。最后,由于由于遮挡而无法检测到口罩的行人被归类为未佩戴口罩,因此很可能将这些特征作为非口罩分类的决定性特征来学习。应该防止出现这种情况,因为这并不能说明真实的口罩佩戴状态。
因此,我们对未来可能的工作有以下建议。首先,对于下一步的人脸检测和识别研究,我们认为最好是将重点放在人脸检测上,而不是人的检测上。这在说一个人是否戴着面罩时可能工作得更好,因为它更有可能在正确的特征上训练网络,比如由于面罩而导致的面部部分的遮挡,而不是在看人时只是一小部分,例如,因为它只是相对少量的像素是不同的。在当前的配置中,网络更有可能在专注于整个人时训练其他功能,如色调和亮度级别,这些都是您不想训练的因素,而这些因素与结果无关。其次,当前实现的另一个有趣的特点是查看使用与分离无关图像相反的图像序列,例如,使用静电图像中戴或不戴口罩的人的图像,是否与您选择的架构相关。我们预计它会有实质性的效果,因为在对图像序列进行训练时,很多图像非常相似,所以不确定分布是否均匀,网络是否在正确的特征上进行训练。此外,我们建议将第三类(即“不可检测”)分配给每个数据实例,如果由于遮挡而佩戴了口罩,则不应从这些数据实例中检测到该数据实例。最后,我们将鼓励在未来的工作中利用验证集进行优化,而不是针对测试集进行优化,因为这可能会导致在不可见数据上发现不可泛化的超参数。
结论
当回顾这个项目时,我们得出的结论是,我们已经成功地实现了一个分类器网络模型,该模型在提议的管道中连接到一个自增强的非流行数据集⁵。从我们比较的网络来看,RESNET-50是所选型号中性能最好的,但仍有改进的空间。
我们学到了很多关于数据处理、分类器的实现、检测技术以及训练过程和优化过程的实用性。我们希望在自己做深度学习的计算机视觉项目时为读者提供一些指导和清晰的内容,并希望我们的努力能让您在做类似的项目时生活更轻松。
参考文献
- [1]Hussain,G.J.,Priya,R.,Rajarajeswari,S.,Prasanth,P.和Niyazuddeen,N.(2021年5月)。冠状病毒监控系统中用于图像分析的口罩检测技术。摘自“物理学杂志:会议系列”(1916年第1卷,№1,012084页)。IOP发布
- [2]Militante,S.V.和Dionisio,N.V.(2020年,8月)。基于深度学习的实时面膜识别与报警系统。2020年,第11届IEEE控制与系统研究生研究座谈会(ICSGRC)(第106-110页)。IEEE
- [3]姜晓.,项锋,吕明,王伟,张振中,余勇(2021年,2月).YOLOv3_SLIM用于人脸面具识别。摘自“物理学杂志:会议系列”(1771卷,№1,012002页)。IOP发布
- [4]Loey,M.,Manogaran,G.,Taha,M.H.N.,&Khalifa,N.E.M.(2021年)。针对冠状病毒大流行时代的人脸面具检测,提出了一种基于机器学习方法的混合深度迁移学习模型。测量,167万,108288
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/06/20/%e7%9b%91%e6%8e%a7%e6%95%b0%e6%8d%ae%e9%9b%86%e4%b8%ad%e4%ba%ba%e8%84%b8%e9%9d%a2%e5%85%b7%e6%a3%80%e6%b5%8b%e4%b8%8e%e5%88%86%e7%b1%bb%e7%9a%84%e6%b7%b1%e5%ba%a6%e5%ad%a6%e4%b9%a0%e6%96%b9%e6%b3%95-2/
