
闭路电视摄像机技术及其基础设施的快速进步导致全球正在实施大量的监控摄像机,预计到2021年底将超过10亿台。考虑到实时生成的海量视频,人工操作的视频分析变得效率低下、成本高昂,甚至几乎不可能,这反过来又对高效的视频监控系统的自动化和智能化方法提出了巨大的需求。
视频监控中的一项重要任务是异常检测,即识别不符合预期行为的事件。
一般意义上的异常事件具有突发性的特点,为了能够第一时间了解异常事件,通常长时间盯着监控屏幕观察需要耗费大量人力,这样不仅会让人感到疲惫,还容易忽略一些不起眼的事件。因此,复杂场景下监控视频异常事件的自动检测与识别作为智能视频监控系统的核心课题,受到越来越多研究者的关注。然而,由于光照变化、相互遮挡、重叠、不规则运动以及异常事件定义不清等特点,使得复杂场景中异常事件的检测成为一个极具挑战性的问题。
通常为了检测离群点,我们从学习正常事件的分布和特征开始,这个特征是通过无监督的方法(如自动编码器)提取的,为了能够推广到学习集中的不可见的事件,如果使用有监督的方法,我们会提取与我们的训练数据密切相关的特征,而不是很好的泛化,在从正常事件提取特征之后,我们将同样的特征提取方法应用到我们想要分类的事件上,为了确定它是否是正常的,我们定义了一个距离它的度量距离,如果我们从正常事件中提取特征,那么我们就定义一个距离它的度量距离,以确定它是否是正常的,为了确定它是否是正常的,我们定义了一个度量距离,它与我们的训练数据有很强的相关性,而不是很好的泛化如果这个距离超过一定的阈值,我们会认为这是一个异常事件。
例如,假设我们在狗与猫的数据集上预先训练了CNN,如果您从分类前的最后一层提取特征向量,然后使用Tsne将这些特征可视化,如果您的模型经过良好训练,您将看到代表这两个类别的两个聚类,如果我们给您一张狗的图像,要对其进行分类,您可以简单地查看她与这两个类别的特征向量创建的空间的距离,并将Argmin作为预测,对于异常检测,也会发生同样的想法,唯一不同的是,如果要对其进行分类,您可以简单地查看她与这两个类别的特征向量创建的空间的距离,并将Argmin作为预测,对于异常检测,也会发生同样的想法,唯一不同的是
异常检测任务的难点有:
- 异常事件发生的频率很低,给数据的收集和标注带来了困难;
- 异常事件的稀缺性导致训练中的阳性样本比阴性样本少得多;
- 在监控场景中,无论是正常事件还是异常事件,都是多样复杂的,即类别内差异性高,方差非常严重。
为了自动检测和识别视频中的异常事件,针对不同的视频场景和异常事件定义,已经提出了大量的检测算法并应用到实际场景中。
[2]提出了一种基于迁移学习和任意镜头学习的监控视频在线异常检测方法,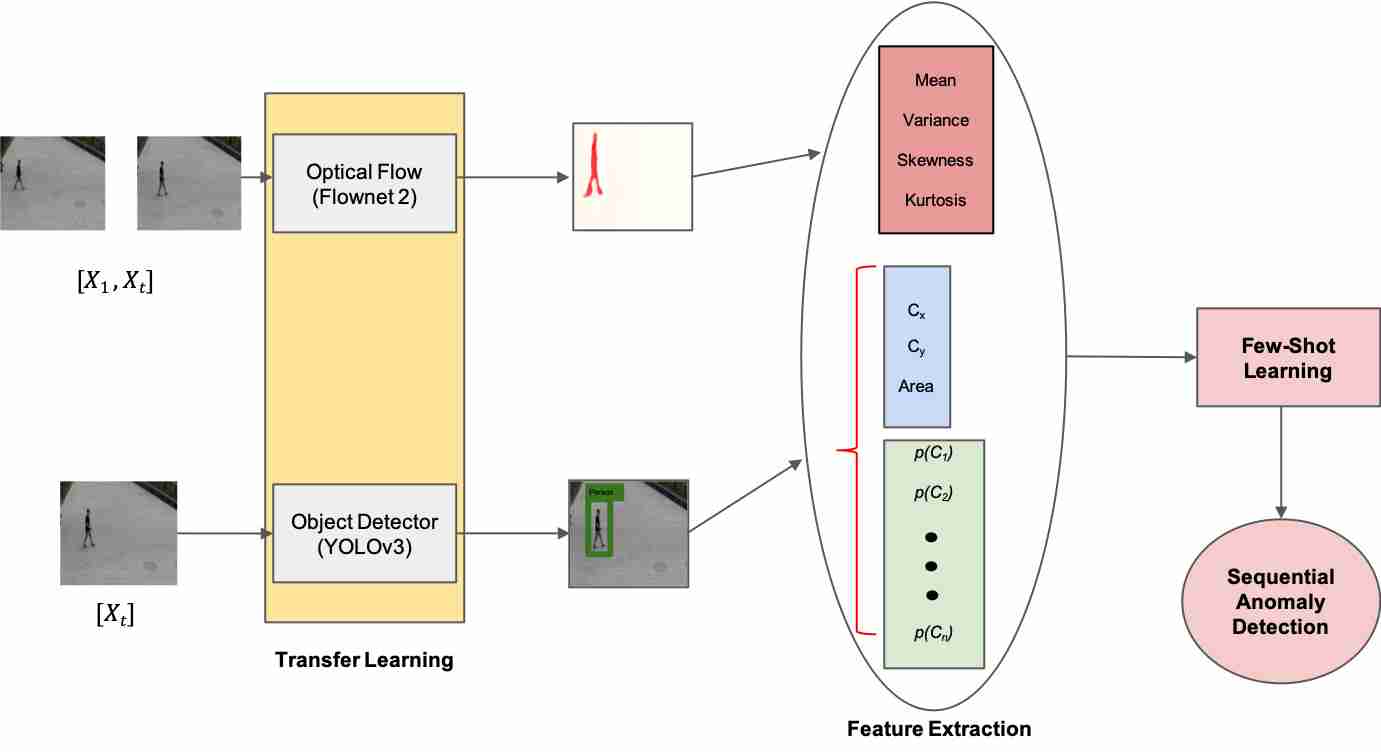
对于视频中的每一帧,它使用预先训练的YOLO提取场景中存在的所有对象,YOLO是提供更高每秒帧数(Fps)处理的实时对象检测系统。
对于图像X_t中的每个检测到的对象,我们得到一个边界框(位置)以及类概率(外观)。它们不是简单地使用整个边界框,而是监控框的中心及其区域来获取位置特征。
然后,他们使用预先训练的光流模型Flownet2监视帧中不同对象的上下文运动。它们提取均值、方差和高阶统计量的偏度和峰度,它们代表了概率分布的不对称性和尖锐性。
对于在帧中检测到的每个对象,它们构造一个特征向量,该特征向量将从光流提取的均值、方差、偏度和峰度与边界框的中心、边界框的面积以及检测到的对象的类别概率组合在一起,该特征向量结合了从光流中提取的均值、方差、偏度和峰度,以及边界框的面积和检测到的对象的类别概率。因此,在任何给定时间t,n表示可能类别的数量,特征向量的维数由D=n+7给出。
它们利用转移学习模块提取不包含任何异常的训练集,并根据未知的复杂概率分布进行分布。为了以非参数的方式确定标称数据模式,它们使用k-最近邻(KNN)欧氏距离来捕捉标称数据点之间的交互作用。
给定提取的运动、位置和外观特征的信息性,预计异常实例位于离标称训练集更远的位置,这将导致测试(查询)集中的异常实例相对于标称数据点的统计上更高的KNN距离。
以前的许多方法首先学习一个通用模式,并假设任何违反该通用模式的模式都应该是异常的。但实际上,要定义一个所谓的正常模式是困难的,而且几乎是不可能的,因为正常模式可能包含太多不同的事件和行为。同样,很难定义异常事件,因为异常事件也可能包含太多类型的情况。
[3]提出了两个新概念,一是在弱监督框架下学习异常事件检测任务。这里的监管不力,是指在培训过程中,只知道一段视频里有没有异常事件,异常事件的类型和具体发生的时间都不得而知。
第二,异常事件检测任务应采用两阶段框架,即不考虑异常事件的类型,先生成异常事件的提案,然后对提案中包含的异常事件进行分类。这有助于提高异常事件检测的召回率。这样的框架在目标检测中与类RCNN方法非常相似。
基于这一思想,[3]采用多实例学习(MIL)方法构建算法框架,并提出了包含稀疏和平滑约束的MIL排序损失来训练模型。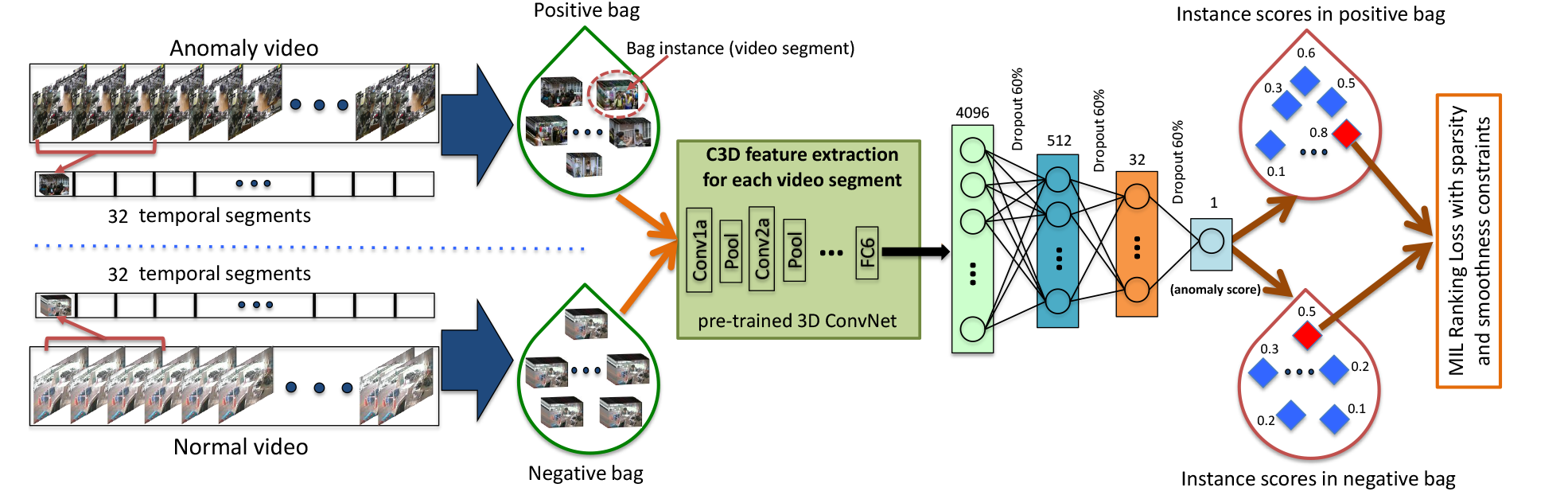
主要利用多属性学习的思想构建训练集,利用C3D+FC网络获取异常得分,最后利用提出的多属性学习排序损失对模型进行训练。
在MIL中,视频中异常事件的精确时间位置是未知的。取而代之的是,只需要指示整个视频中存在异常的视频级标签。包含异常的视频被标记为正的,而没有任何异常的视频被标记为负的。
然后,我们将积极的视频表示为积极的袋子Ba,其中不同的时间段在袋子中形成单独的实例,其中我们假设这些实例中至少有一个包含异常。类似地,否定视频由否定包Bn表示,其中该包中的时间段形成否定实例,没有一个实例包含异常。
由于阳性实例的确切信息是未知的,所以可以针对每个包中得分最高的实例来优化目标函数。
将异常检测定义为回归任务,即异常样本的异常值需要高于正常样本的异常值。
直观的考虑因素可以将排名损失定义为: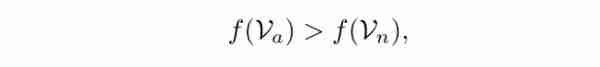
这里,Va和Vn分别是异常样本和正常样本,f是模型预测函数。由于在MIL中,不知道阳性袋中每个样品的真实标签,因此采用以下形式: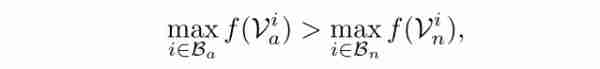
这意味着,在训练中,只有得分最高的样本才用于正反两个包的训练。具体来说,阳性袋中得分最高的样本最有可能是阳性样本,而阴性袋中得分最高的样本被认为是硬性阴性,即硬性案例。在此公式的基础上,为了使正负试件之间的距离尽可能小,采用了铰链损耗的形式。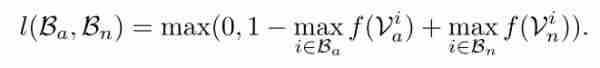
但这一损失没有考虑到视频的时序结构,笔者给出了两条让他改善损失的意见:
- 因为视频片段是连续的,所以异常的分数也应该是比较平滑的。
- 由于阳性包中阳性样本的比例很低,所以阳性包中的分数应该是稀疏的。
基于这两点,作者在损失函数中增加了两个约束,即定时平滑约束和稀疏约束。如下所示。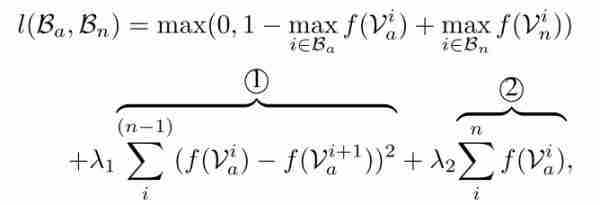
最后,将模型参数的L2规律性相加,得到最终的损失函数。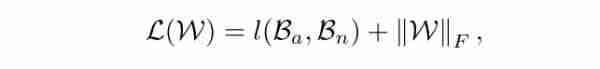
在具体实现中,本文采用预先训练好的C3D模型来提取视频片段的特征。对于提取的特征,使用三个完全连通的层来获得最终的异常得分。上面提出的MIL排名损失被用来训练网络。
[7]提出了一种基于预测未来帧的视频异常事件检测体系结构。具体地说,在给定一些训练视频片段的情况下,模型将学习生成预测器,该预测器可以基于现有视频帧预测下一个正常帧。在测试阶段,输入一些帧,模型根据学习到的内容预测下一帧。如果帧满足预测输出,则判断为正常,否则判断为异常。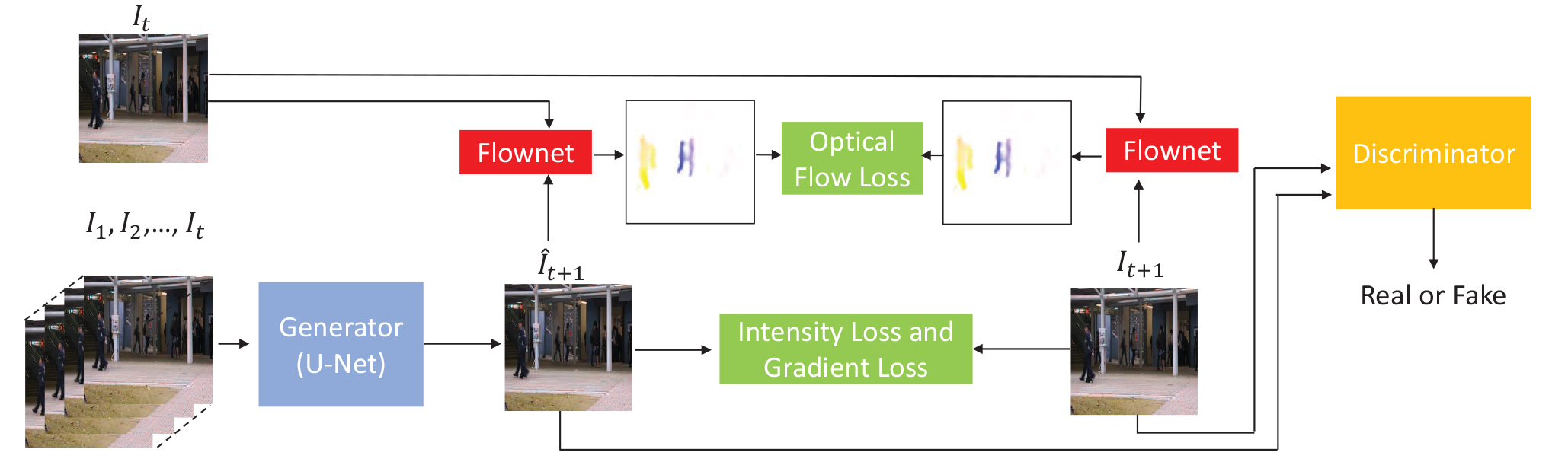
总体思路是学习正常帧的模式,然后基于现有帧使用类似于U-Net的结构对未来帧进行预测,该预测被记录为预测。如果预测与地面事实相差较大,则视为异常事件。例如,如果有视频,第一部分是人们正常过马路,模型可以实时预测下一帧。如果突然出现一辆卡车,而模型预测的帧仍然是过马路的人,那么较大的差异就被认为是异常事件。以往的工作大多只考虑了前述的外观信息,但运动信息也很重要,因此提出了光流常数的概念。
在数学上,给定一些连续的帧I1、I2、…,它,预测帧记录为\HAT{i}_{t+1},地面真实帧为I_{t+1},我们最小化两种类型之间的强度距离和梯度距离,这是前面提到的外观约束,计算如下: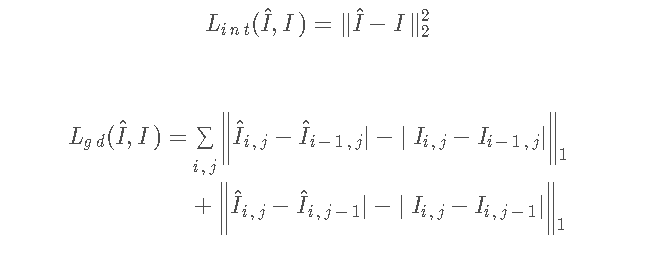
梯度约束的目的是确保预测中的每个像素与其左侧和上方的像素之间的梯度与地面真实情况一致。
为了保持相邻帧之间的时间相干性,它们强制I_{t+1}和I_{t}之间以及HAT{i}_{t+1}和I_{t}之间的光流接近。
光流约束的数学公式表示如下: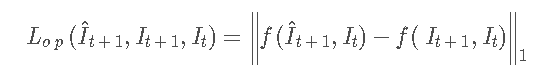
其中,f是基于Flownet估计光流的函数,Flownet是基于CNN的光流估计器。
作者选择了一种相互矛盾的训练类型,他们将基于U网的预测网络视为G。对于D,他们使用了一个斑块鉴别器,这意味着D的每个输出标量对应于输入图像的一个斑块。
[6]提出了流量异常检测来检测、定位和识别以自我为中心的视频中的异常事件。一个名为流量异常检测(DOTA)的新数据集,包含4677个带有时间、空间和分类注释的视频。
他们没有使用AUC度量,而是提出了一种新的时空评估度量(STAUC),并将无监督视频异常检测(VAD)和有监督视频异常检测(VAD)都与AUC和STAUC进行了基准测试,以显示新度量的有效性。
根据输入输出类型的不同,将无监督VAD分为帧级方法和以对象为中心的方法。受监督的VAD类似于时间动作检测,但输出指示异常或无异常的二进制标签。
帧级非监督VAD方法通过重建过去的帧或预测未来的帧并计算重建或预测误差来检测异常,它们基准三种方法及其变体:
- ConvAE是一种时空自动编码器模型,它使用2D卷积编码器对时间堆叠的图像进行编码,并使用反卷积层进行解码来重建输入。
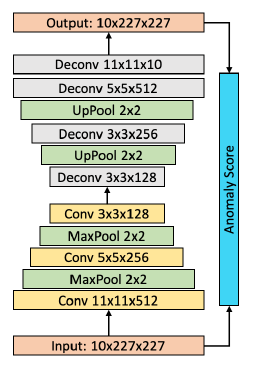
每像素重建误差形成异常分数图∆i,并计算均方误差作为帧级异常分数。
- ConvLSTMAE类似于ConvAE,但分别对空间和时间特征建模。2D CNN编码器首先捕获每帧的空间信息,然后由多层ConvLSTM递归编码时间特征。然后,另一个2D CNN解码器重建输入视频剪辑。

- AnoPred是一种帧级的VAD方法,它以连续的四个先前的RGB帧作为输入,并应用UNET来预测未来的RGB帧。AnoPred通过包含图像强度、光流、梯度和对抗性损失的多任务损失来提高预测精度。

- TAD使用多流RNN编解码器对交通场景中的正常包围盒轨迹进行建模,以编码过去的轨迹和自我运动,并预测未来的对象包围盒。收集预测结果;使用预测一致性而不是准确性来计算每个对象的异常得分。对每个对象的分数进行平均,以形成每个帧的分数。
对于受监督的VAD,他们对具有正常和异常类别的多个视频动作检测方法进行基准测试,以提供对受监督的VAD的洞察。他们使用ImageNet预先训练的ResNet50模型来收集帧特征并训练不同的分类器:
- FC:一个用于图像分类的三层全连通网络
- LSTM是一种用于序列图像分类的单层LSTM分类器。
- 编码器-解码器,具有对当前帧进行分类的编码器和预测未来类别的解码器的LSTM模型。*
- 它们还训练建立在编解码器基础上的时间递归网络(TRN),除了将预测反馈给编码器之外,还将其反馈给编码器以提高性能。
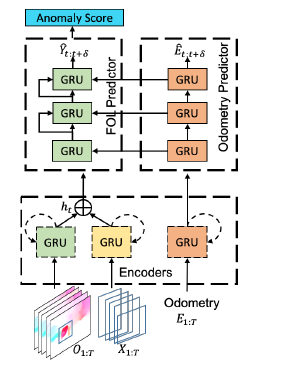
[5]对驾驶员注意力预测问题进行了研究,将以往针对正常情况和危急情况的工作扩展到意外情况。
他们构建了一个有2000个视频序列(称为DADA-2000,超过65万帧)的大规模基准,费力地注释了司机的注意力(注视、扫视、聚焦时间)、事故对象/间隔以及20名观察员的54个事故类别,他们还仔细地注释了实验室中不同天气条件(晴天、下雪和下雨)、光照条件(白天和夜间)、场合(高速公路、城市、农村和隧道)和不同事故类别的注意力数据。
他们提出了一种用于驾驶员注意力预测的多路径语义注意力融合网络(MSAFNet),该网络由多路径3D编码模块(M3DE)、语义引导注意力融合模块(SAF)和驾驶员注意力地图解码模块(DAMD)组成。M3DE使用多个交错的3D块来扩展3D卷积,例如3D卷积、3D批归一化和3D池化。SAF的目的是探索驾驶员注意预测中的语义变化,并通过卷积-LSTM的注意融合实现时空动态转换。
在给定具有几个帧的视频剪辑的情况下,该体系结构预测剪辑内最后一帧的驾驶员注意图。
形式上,假设我们有视频剪辑i,由T个帧{i_t}^{T}_{1}组成。他们首先使用由城市景观预先训练的deeplabV3获得语义图像{S}^{T}{1}。然后,将{S}^{T}_{1}和{i}^{T}_{1}作为输入输入到M3DE的每条路径中。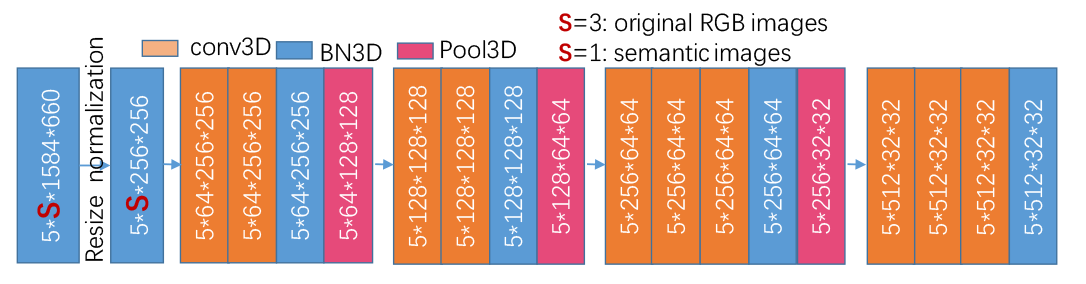
这里,构造了一个3DCNN结构,用于分别对{S}^{T}{1}和{i}^{T}{1}的空间和顺序隐藏表示进行编码,该结构由利用不同尺度的时空表示的3D块的四个集成组成,由若干3D卷积块(Conv3D)、3D批归一化挡路(BN3D)和3D池化挡路(Pool3D)交织而成。
在通过M3DE体系结构后,我们得到视觉和语义路径的时空隐藏表示Z_{v}={Z_{v}^{t}}^{T}_{t=1}和Zs={Z_{s}_{t}}^{T}_{t=1},然后将它们送入后续的SAF模块。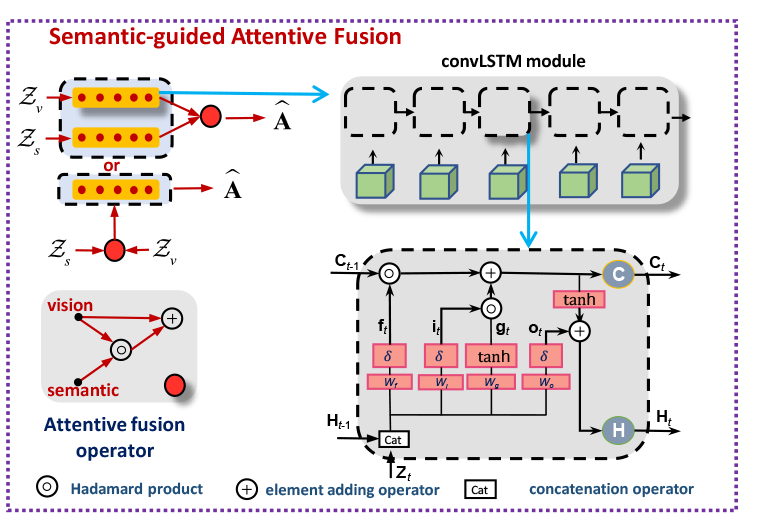
它们采用Conv-LSTM学习并将输入片段内连续帧中的视觉和语义的时空隐藏表示转移到其最后一帧。换句话说,conv-lstm在这里充当信使,将剪辑内的时空动态传输到最后一帧。然后,将语义路径中最后一帧的转移隐含表征作为注意力算子,设计了语义制导的注意力融合(SAF)模块,将时空语义线索集中到视觉路径上。将saf的输出表示为隐藏的驾驶员注意表示Aˆ。考虑到融合阶段(后期融合或早期融合),他们将SAF表示为两种形式: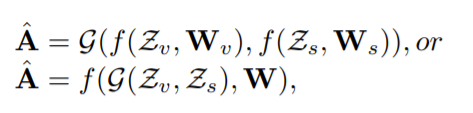
其中,Aˆ是SAF的输出,G表示注意融合算子,f(·,·)分别为视觉路径、语义路径或融合路径指定参数为WV、Ws或W的卷积-LSTM模块。
Conv-LSTM通过在学习时间动态时保留预测中的空间细节来扩展LSTM,包括存储单元Ct、时间t的隐藏状态Ht以控制存储器更新和Ht的输出,并在输入Zt时以时间步长传递动态。
准确地说,compLSTM的计算方法如下: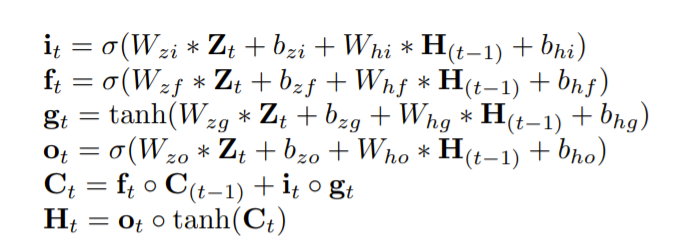
其中σ和TANH分别是Logistic Sigmoid和双曲正切的激活函数。“∗”和“◦”分别表示卷积算子和阿达玛乘积,i_t、f_t、o_t分别是控制输入、遗忘和输出的卷积门。
注意力融合将语义路径中T帧的隐含表示{Z_{s}_{t}}^T_{t=1}或隐含状态H^{v}_{t}作为注意张量,分别选择{Z^{v}_{t}}^T_{t=1}或H^{v}_{t}中的特征表示进行早期融合或后期融合。
通过引入残差连接来保持融合后视觉路径的原始信息。因此,我们将ˆ定义为: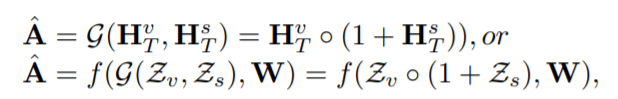
其中f(·,·)是CONV-LSTM模块。
在获得隐藏的驾驶员注意力表示Aˆ后,将其馈送到驾驶员注意力地图解码模块,以生成每个片段中最后一帧的驾驶员注意力地图Yˆ,其大小与输入帧相同,其中8层交织了若干个2D卷积、2D批归一化和上采样层。
使用7种最先进的方法对基准测试和对比实验进行了深入广泛的分析,获得了MSAFNet优越的性能。值得注意的是,在一些典型的意外场景中,所提出的模型可以比人类更早地注意到撞车对象,例如具有交叉行为的场景和涉及自驾车的碰撞行为的场景。
结论
在现代智能视频监控系统中,基于计算机视觉分析的自动异常检测起着举足轻重的作用,它不仅可以显著提高监控效率,而且可以减轻实时监控的负担。
参考文献
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/06/21/%e8%a7%86%e9%a2%91%e4%b8%ad%e5%bc%82%e5%b8%b8%e4%ba%8b%e4%bb%b6%e7%9a%84%e6%a3%80%e6%b5%8b/
