
本案例研究基于从扫描图像中提取表格数据。在这些扫描的文档中有大量的非结构化数据,这些数据可以是零售收据、发票、保险索赔等。这些图像通常包含表格形式的信息。
问题陈述
这些扫描的图像通常是人工处理的,这具有很高的劳动力成本,并且有时还可能存在低效或不准确的数据处理。我们的主要目标是准确地检测表格区域,并从行和列中提取信息。
如何使用深度学习来解决这个问题?
计算机视觉是人工智能的一个部门,它允许计算机理解和标记图像。我们将有扫描的图像,在计算机视觉的帮助下,我们将从图像中分割出表和列区域。
数据概述
我们将在旱獭数据集上训练我们的TableNet模型。
Marmot data set已经扫描了图像以及它们各自的.xml文件,该文件包含有关表和列坐标的信息。这是一个可免费用于研究目的的公共数据集。
业务目标和约束
绩效指标
我们将使用F1分数作为我们的性能指标。F1分数是准确率和召回率的调和平均值。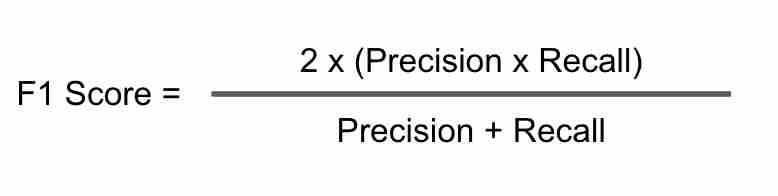
为了在图像分割任务中测量精度和召回率,我们将每个预测掩码与每个像素上的目标掩码进行比较。
数据集准备和EDA
我们总共有509个图像,但是原始数据集中缺少14个注释文件,所以我们将使用495个图像。

对于每个图像,我们都有各自的.xml文件,它将帮助我们找到表和列坐标。
此代码片段是上述扫描图像的XML文件。它包含许多元素,如文件名、大小、路径等。通过大小我们可以得到图像的高度和宽度。对于每个表和列,我们都有xmin、xmax、ymin和ymax坐标。
在读取XML文件并获得坐标之后,我们将拥有表和列掩码,如上图所示。我们还将创建一个Pandas数据帧来保存图像、列掩码和表掩码的地址。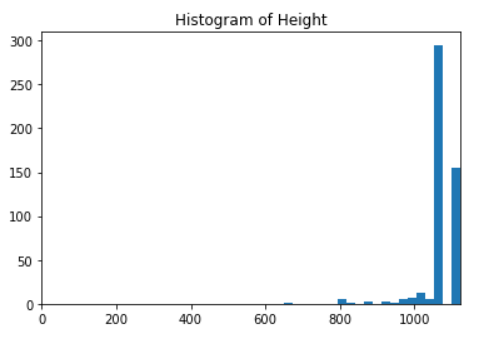
从上面的直方图可以看出,我们的大多数图像的高度都在1000以上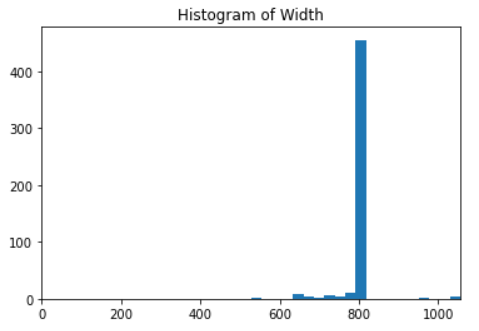
我们的图像宽度在800左右。
TableNet架构
我们有一个VGG-19编码器和两个解码器,一个用于表区域的分割,另一个用于表区域内的列的分割。
该模型采用输入图像,并为表和列输出两个不同语义标签的图像。预先训练的VGG-19网络帮助我们学习低级功能。此模型的编码器在这两个任务中都是通用的,但是解码器作为表和列的两个不同分支出现。因此,我们将训练两个计算图。输入图像首先转换为RGB图像,然后将大小调整为1024*1024。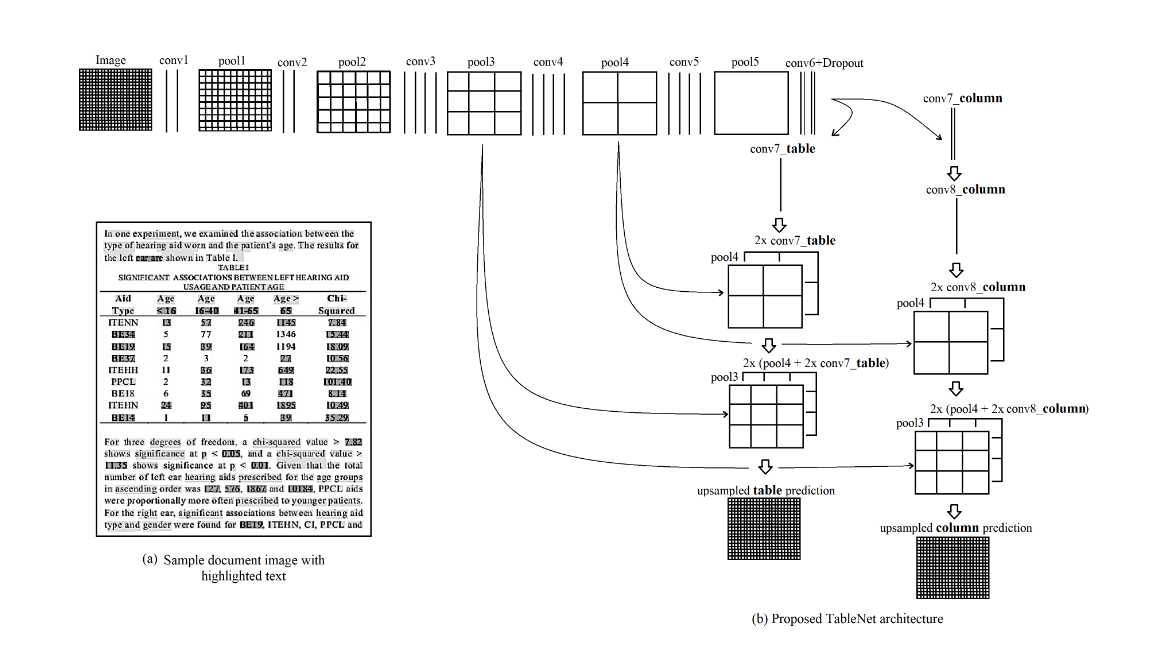
在上面的图像中,con1到pool5是公共编码层。所有五个卷积层在它之后都有最大汇聚层。CONV7_TABLE和CONV7_COLUMN是两个解码器的两个不同分支。在此解码器分支形成后,我们的卷积6层采用REU激活,丢失率为0.8。背后的直觉是列区域是表区域的子集。最后利用Conv2D、Transpose和UpSsaming2D对最终的特征图进行升维,以满足原始图像的尺寸要求。在我们从模型中获得表掩码和列掩码之后,然后使用Pytesseract OCR从原始图像中提取文本。OCR代表光学字符识别。这有助于识别图像中的文本。Tesseract基于神经网络子系统。它在LSTM上进行训练,因为它有助于预测字符序列。
数据预处理
根据研究文件,我们会-
我们将使用TensorFlow的数据加载器来加载数据。
我们将使用批次大小1来训练模型。我们的图像是RGB格式,而我们的列和表蒙版是灰度的。
模范训练
上面是我们使用VGG-19作为编码器的TableNet架构的代码。
从上图我们可以看到,挡路3和挡路4的最大池层串联在表解码器和列解码器中。我们的输出特征地图将与输入图像尺寸相同,即1024*1024。在最终的要素地图中,通道数为2,因为我们有两个类。
培训结果

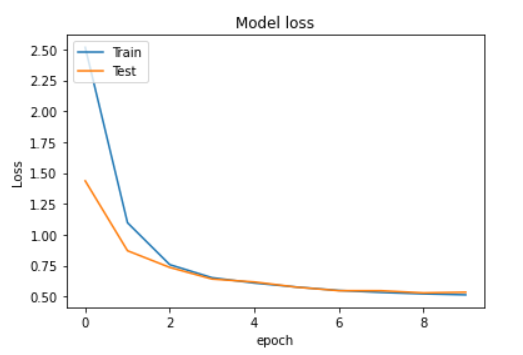
从上面的三个曲线图可以看出,对于训练集和测试集,我们的表掩码准确率都在90%左右,而对于列掩码,我们的表掩码准确率也在90%左右。我们的损失也在每一个时代都在减少。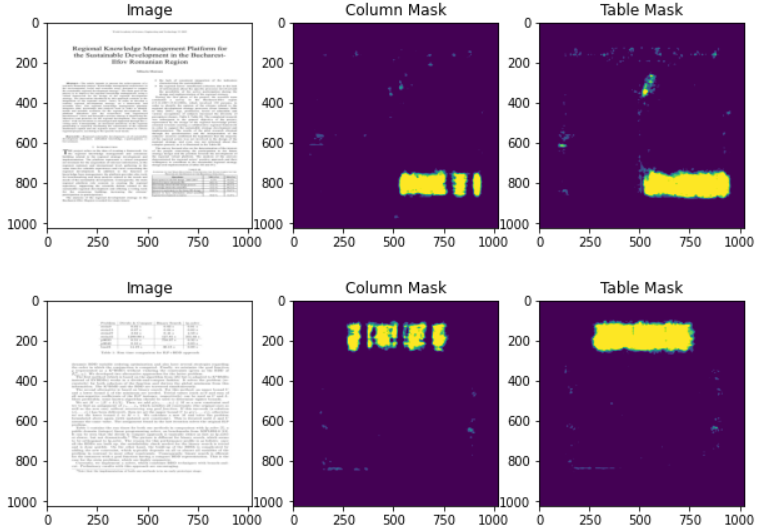
以下是一些预测。如您所见,我们的模型在预测表和列掩码方面做得非常好。在这些掩码的帮助下,我们将能够从表格区域中提取文本。
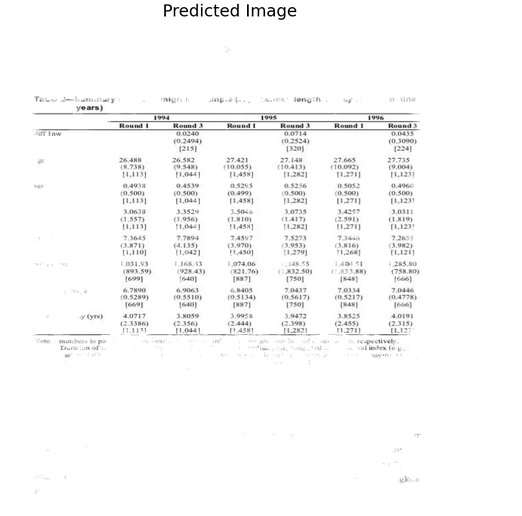
使用PyTesseract OCR从预测图像中提取文本-
从上面的图像可以看出,我们的模型在预测表格图像方面做得很好,并且屏蔽了表中没有的所有内容。我们在测试数据点上的F1分数是-
因为我们只有494张图片,所以我们只使用了10%的数据进行测试。我们还计算了所有494张图像的准确率和召回率。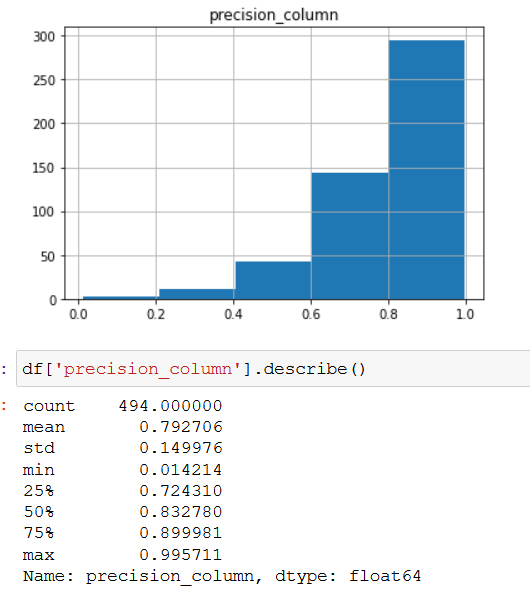
我们可以看到,大约75%的柱形掩模的精度在0.89左右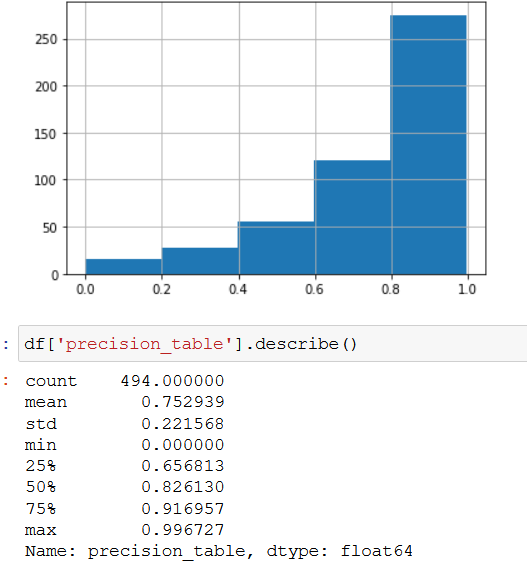
大约75%的台面罩的精确度在0.91左右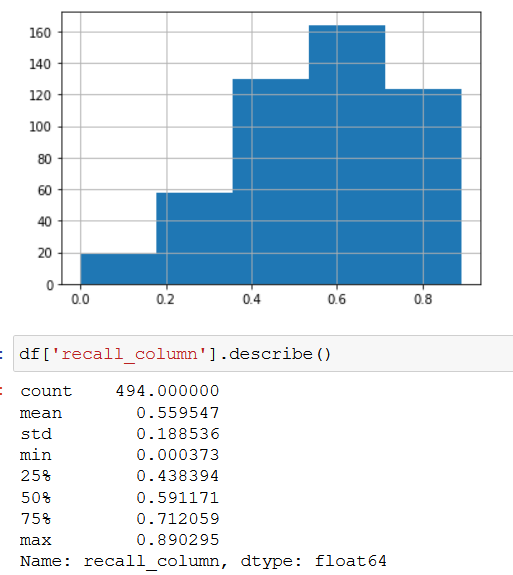
75%的柱面罩召回率约为0.71,最高召回率为0.89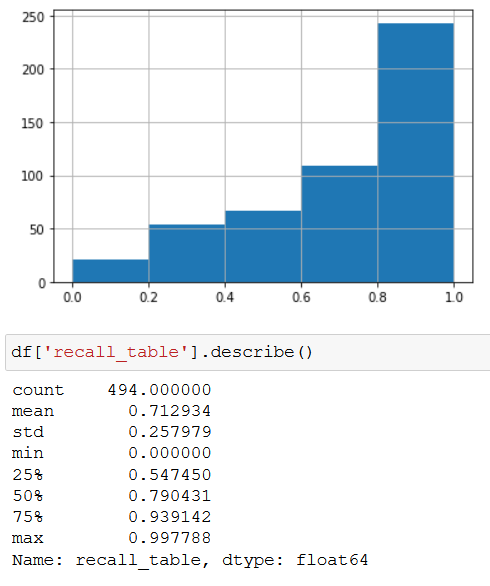
大多数桌上面具的召回率在0.93左右,最高召回率为0.99,这是非常好的。我们可以注意到,我们的模型在检测表掩码方面做得很好,但是对于列掩码,可以通过训练更多的历元来提高准确率。
带ResNet编码器的TableNet
我们还使用ResNet-50作为编码器实现了TableNet架构。
使用ResNet-50作为编码器的结果
以下是ResNet-50的结果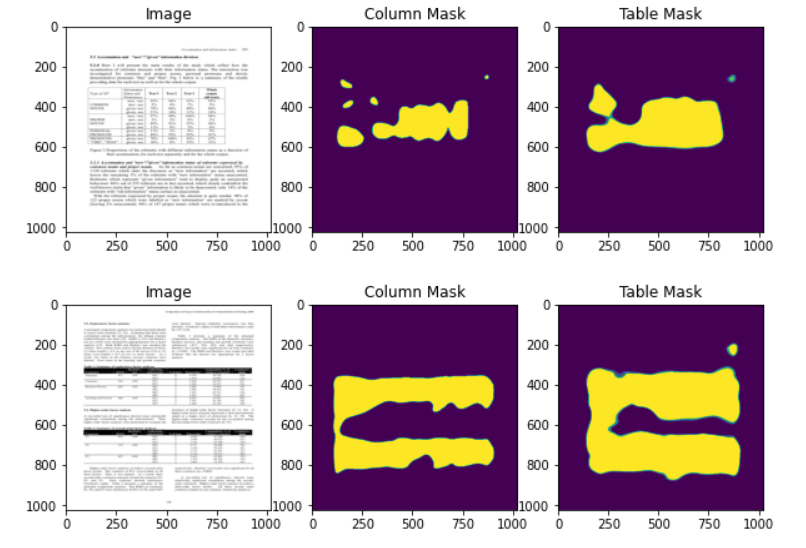
我们可以观察到,我们的列掩码不像VGG-19编码器那样精确。
我们的F1分数为ResNet-50作为编码器,与VGG-19编码器在同一范围内。
部署
模型使用烧瓶部署在本地系统中。
视频链接-
今后的工作
我们这两位模特都只在很少的几个时代接受过训练。在他们的研究论文中,他们已经训练了大约5000个纪元,但由于它需要非常强大的GPU和高计算能力,我无法训练那么多纪元。在未来,我想用更多的数据来训练它,因为目前我们只在490多张图像上训练了我们的模型。
参考文献
您可以从我的GitHub回购中查看所有详细信息和代码-
在LinkedIn上与我联系-
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/06/22/tablenet%ef%bc%9a%e7%94%a8%e4%ba%8e%e7%ab%af%e5%88%b0%e7%ab%af%e8%a1%a8%e6%a3%80%e6%b5%8b%e5%92%8c%e4%bb%8e%e4%b8%ad%e6%8f%90%e5%8f%96%e8%a1%a8%e6%a0%bc%e6%95%b0%e6%8d%ae%e7%9a%84%e6%b7%b1/
