

计算机视觉听起来可能像科幻小说,但它已经成为现实。从简单的物体检测到面部情感识别,我们可以找到许多直接应用到我们生活中的例子。object detection facial emotion
这听起来可能很复杂(确实如此),但是您可以实现一个系统来用几行代码来识别一个人。few lines
您可以在程序中使用许多选项来实现,如OpenCV和TensorFlow,而不必了解深度学习或花哨的算法。OpenCV Tensorflow
什么是AWS Rekognition?
亚马逊识别(Amazon Rekognition)就是其中一项服务。这是一项来自AWS的服务,可以轻松地将图像和视频分析添加到您的应用程序中。它有很好的应用,例如:Amazon Rekognition
- 物体检测:您可以检测图像或视频中的物体和场景。您可以使用自定义对象对模型进行包含式培训。
- 面部识别:您可以检测和识别图像中的人脸,这可以用于用户验证,也可以来自名人。
- 文本检测:它可以从图像和视频中提取文本内容,因此您可以在应用程序中启用OCR。
并且它可以与其SDK一起使用。因此,您只需几个步骤即可与应用程序集成。让我们看看怎么做。
配置
我们需要设置凭据才能使用AWS SDK执行任何操作。如果您已经有一个,您可以跳过这一部分。
我们将创建一个用户来访问S3服务。为此,请访问IAM控制台,转到Users菜单,然后单击Add User:IAM console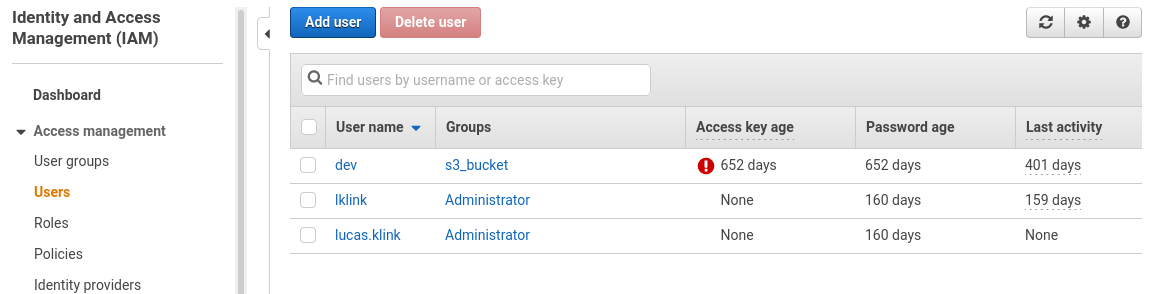
键入您的用户名,然后单击Programical Access Option(程序访问选项)。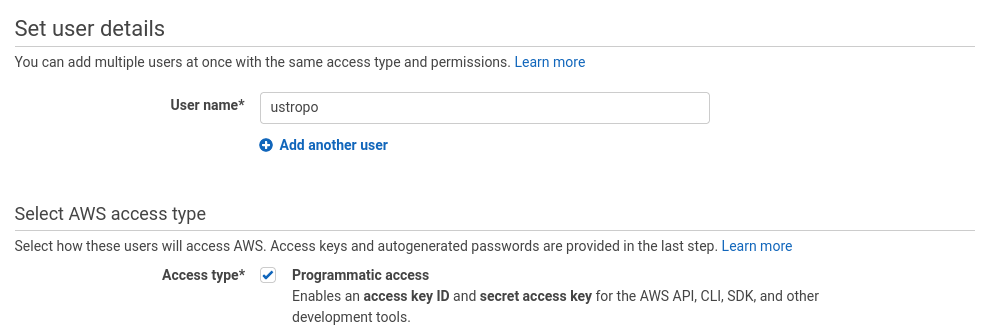
下一步是为用户设置权限。这里有几个选项,比如添加到组或从其他用户复制。要访问Rekognition服务,您需要一个Rekognition权限。在我们的示例中,我们选择AmazonRekognitionFullAccess。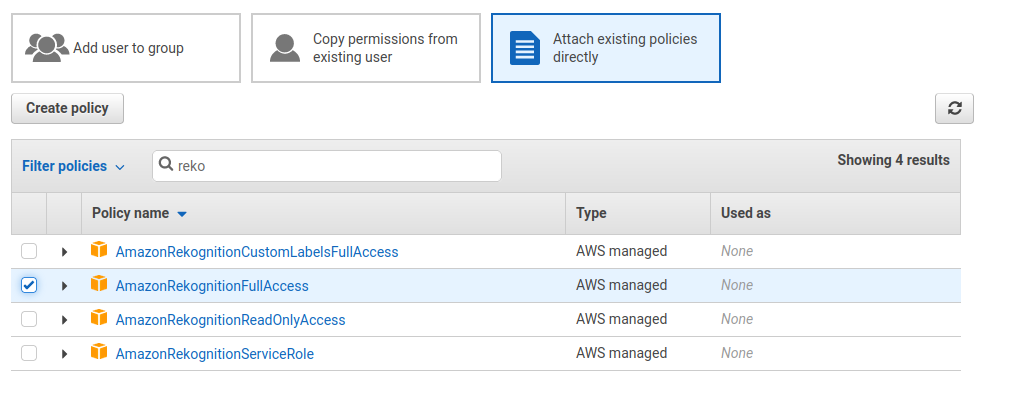
查看您的数据,然后单击Create User(创建用户)按钮。在您的访问密钥ID和秘密访问密钥旁边应该会显示一条成功消息。复制这两个文件并将其放入安全文件中(或下载.csv文件)。
接下来,我们需要通知这些数据,以便Boto3可以访问AWS服务。为此,我们创建一个名为~/.aws/Credentials的文件:
[default]
aws_access_key_id =
aws_secret_access_key =
region=us-east-1然后,我们可以安装Boto3软件包:
pip install boto3我们还安装了Pillow软件包来处理图像:
pip install Pillow检测标签
对于AWS Rekognition来说,标签(或标签)是它在图像或视频中可以识别的所有内容,如对象(人、树)、场景(海滩)或概念(室外)。如果您正在使用视频,它还可以检测到活动(如游泳)。
要检测图像中的所有标签,我们首先需要获取Rekognition客户端。Rekognition client
import boto3之后,使用方法Detect_Labels()获取对象内部所有标签的响应,并在Image参数中传递图像。
您有两个选择:
- 通过Bytes参数上传图像字节。
- 如果您已存储在S3存储桶中,则指示S3Object内的对象的Bucket和名称。
让我们以下面的计算机照片为例。
要检测所有标签,我们将图像传递给Detect_Labels方法。detect_labels
此方法返回一个字典,其中包含键标签内的标签数组。每个标签都是一个可以包含以下字段的对象:
- 名称:标签的名称
- 置信度:图像包含标签的置信度。
- 实例:包含图像内检测到的对象的每个实例的边框。
- 父级:包含此标签的所有祖先的列表。例如,如果您有一辆汽车,则可以将车辆和交通工具作为其父级返回。
如果我们对图像运行上面的代码,我们会得到以下结果:
Found 14 labels in the image:
> Label "Pc" with confidence 99.93
> Label "Computer" with confidence 99.93
> Label "Electronics" with confidence 99.93
> Label "Laptop" with confidence 99.77
> Label "Computer Keyboard" with confidence 99.55
> Label "Hardware" with confidence 99.55
> Label "Keyboard" with confidence 99.55
> Label "Computer Hardware" with confidence 99.55
> Label "Wood" with confidence 81.52
> Label "Furniture" with confidence 78.39
> Label "Table" with confidence 77.92
> Label "Plywood" with confidence 77.74
> Label "Desk" with confidence 72.95
> Label "Tabletop" with confidence 61.14如您所见,它为同一对象(如计算机、笔记本电脑和硬件)获取多个标签。
我们可以使用实例信息在它检测到的对象周围绘制方框,这样我们就可以在图像中实际看到该对象。
我们使用每个Label实例中可用的边界框信息在标识的对象周围绘制一个矩形。坐标是图像总高度和总宽度的百分比,因此我们需要将其转换为实际位置。
然后我们得到一个类似于这个的结果。
结论
目标检测是计算机视觉的一小部分。虽然这听起来可能很复杂和不可能,但事实是现在将其与您的应用程序集成非常简单。
您可以使用一些不错的选项,AWS Rekognition就是其中之一。它不仅具有物体检测的功能,还具有更多的功能。
只需几个额外的步骤,您就可以将其与您的应用程序集成,并且无需了解任何花哨的算法或复杂的代码即可使用它。
如果您已经在使用AWS服务,也可以考虑使用AWS Rekognition。
感谢您的阅读。
更多内容请访问Playenglish.ioplainenglish.io
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/06/23/%e5%a6%82%e4%bd%95%e4%bd%bf%e7%94%a8python%e5%92%8caws-rekognition%e6%a3%80%e6%b5%8b%e5%af%b9%e8%b1%a1/
