
我们刚刚进入2021年4月,印度每个人的日常生活都在恢复正常。我在孟买的家里工作了一年多,很高兴订了10天后返回班加罗尔的机票。快进一周后,第二波浪潮已经在印度开始,出现了一些危险的迹象。立即实施了封锁,我不得不取消返回办公室的计划。每天我都希望每天的病例数量开始减少,结果却截然相反。这一数字已经开始以指数级大幅增长。有两周多一点的时间,每天都有我认识的人死于CoVid。很难目睹医疗行业与这场可怕的流行病作斗争。更艰难的是,我感到非常无助,无法在应对这场流行病中发挥自己的作用。我想做一些或创造一些可能被证明有一些有形价值的事情。很快,我看到了一项关于使用人工智能模型来识别肺部柯萨奇病毒感染区域的研究报告。我决定在此基础上建立一个模型。这个项目开始的目的是为更美好的未来贡献我的一小部分。reasearch study
概述
本文假设您具有一些神经网络和卷积网络的基本知识,我已经尝试以非常简单的方式解释所有内容。对于我认为您可能会遇到困难的术语,我已将它们链接到各自的文章或研究论文。这是我的第一个成熟的计算机视觉人工智能项目,我已经构建了从TensorFlow模块的基本构建块到代码的一切,代码可以在这里找到。here
本研究针对肺部CT扫描图像进行图像分割。图像分割是为图像的每个像素分配标签的过程。在下面给出的示例中,右图像(也称为标签遮罩)是左图像的图像分割结果。黑色像素被标记为“背景”,粉色像素被标记为“马”,而乳白色像素被标记为“人”。
在研究中,分析了两种结构不同的模型-U-Net和SegNet的性能,这两种模型都是目前流行的图像分割模型框架。它讨论了它们各自的优点和缺点,以及如何对它们进行微调以获得最佳输出。
数据集
为了构建能够完成此任务的模型,我们需要准备一个包含大量图像及其对应分割图像的数据集。然后,该数据集被提供给模型,模型从中学习。一旦模型已经从数据集学习,它将能够对具有与它在其上学习的数据集中的图像集合类似性质的图像进行图像分割过程。
用于训练我的模型的数据集是将100张单层CT扫描图像调整到512×512维之后的一组图像。这个数据集是由意大利医学和介入放射学协会准备的。然后手动标记这100幅图像,并根据肺组织、肺炎感染水平和Covid感染水平制备标记掩模。这些标签被命名为-C0,C1,C2和C3。C0是优势区域,包括肺包膜组织和非感染区。关于数据集是如何准备的更多见解可以在这里找到。here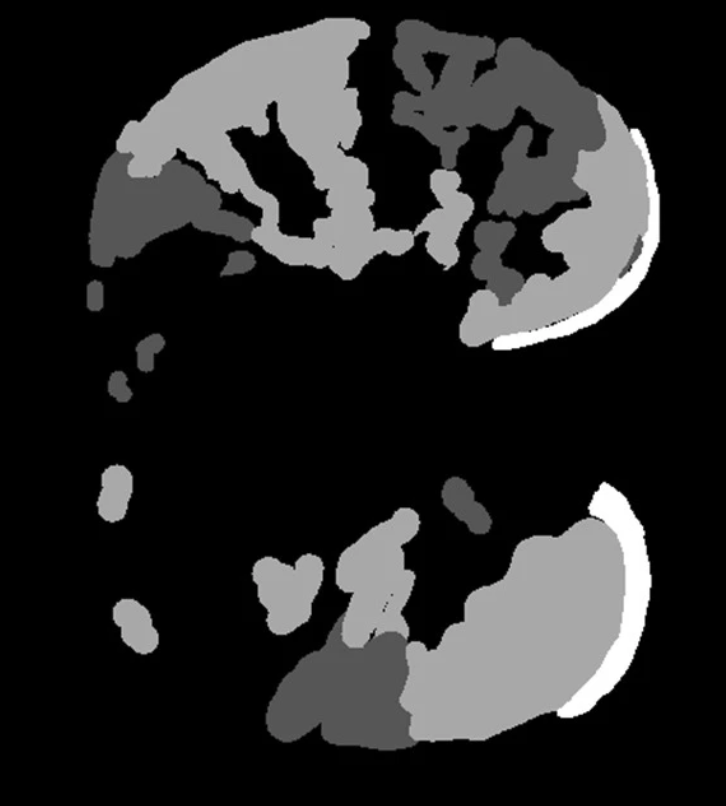
模型框架
我选择了建立一个U-Net模型。U-Net是2015年在“U-Net:用于生物医学图像分割的卷积网络”一文中最初创建的一种架构。它是对完全卷积网络概念的改进。该模型的前半部分使用卷积矩阵对图像进行多步压缩,并在几个检查点提取图像的所有特征。模型的后半部分使用去卷积过程将图像的压缩形式恢复到其原始尺寸。在对特征进行去卷积的同时,它还使用了上半年在检查站保存的特征。有关U-Net模型及其构建的详细说明,可以在这里找到。“U-Net: Convolutional Networks for Biomedical Image Segmentation” here
在研究中,将CT扫描图像从512×512像素压缩到256×256像素尺寸作为输入馈送到模型中,以减小模型大小和训练时间。我选择将512像素的图像直接输入到模型中。即使它增加了模型大小,也最大限度地减少了数据丢失。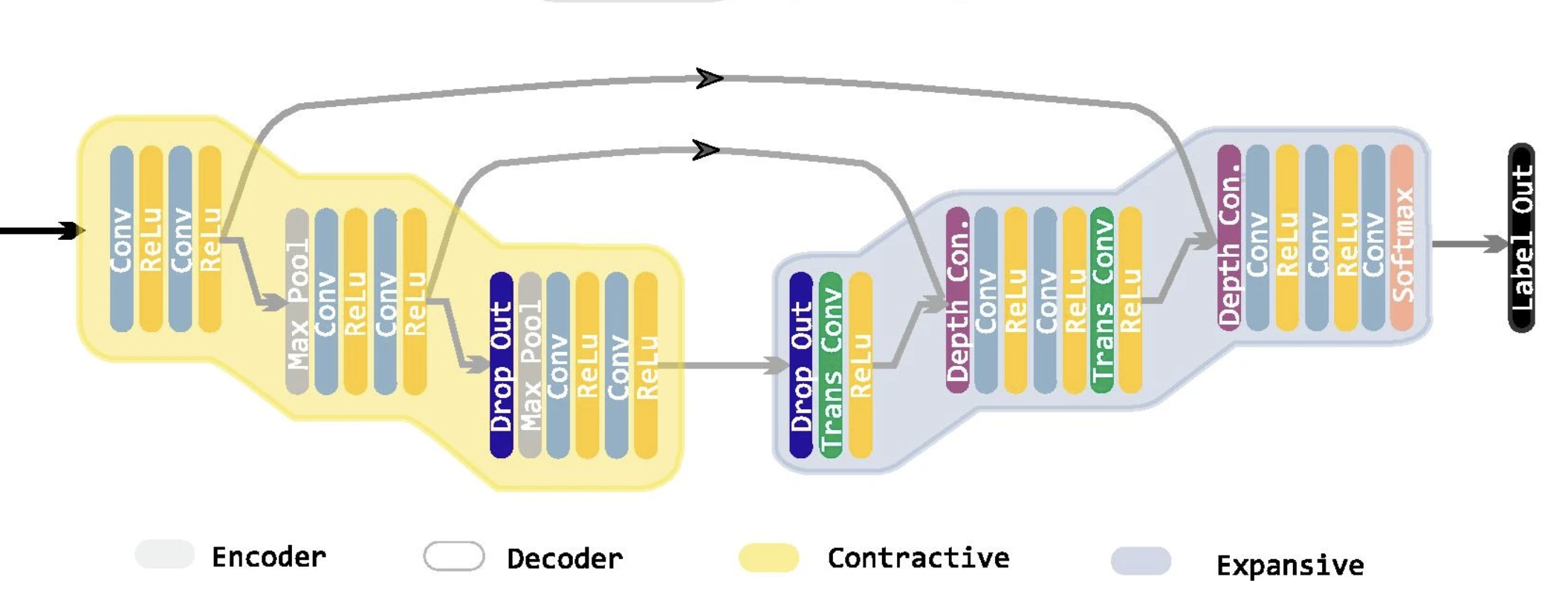
损失函数
损失函数是用于训练模型的函数。如果模特贴错了标签,就会受到惩罚,如果是正确的,就会得到奖励。在数据集中,每个标签的密度非常不平衡。您可以注意到,在上面的示例标签遮罩中,标签C0的出现频率非常高。与它相比,肺炎和Covid感染区域的发生非常少,因为在轻度或中度感染的患者中,这些区域非常小。因为C1、C2和C3区域变得非常小。如果我们使用正常的交叉熵损失函数,这种标签出现的不平衡会在训练模型时产生问题。由于模型会太频繁地遇到类C0,所以它会偏向该类,并倾向于将其分配给比正常情况下更多的像素。为了解决这一问题,我们使用中值频率平衡加权交叉熵损失函数来代替。如果该模型错误地对出现频率非常低的标签进行分类,则该损失函数会对该模型造成严重的惩罚,但是对于出现频率更高的标签,该损失函数会对其进行轻微的惩罚,反之亦然。这使得模型考虑到这些标签的低频率并最小化其偏差。median frequency balancing weighted cross entropy loss function
培训和评估
在100张图片中,我使用了84张用于训练,其余16张用于评估模型如何处理看不见的数据。在试验了几个优化器和学习率之后,我得出结论,学习率为3×10^(-5)的ADAM优化器最适合这种情况。我对模型进行了50个纪元(训练循环)的训练,这似乎是最优的计数,以避免过度拟合并最大限度地提高精度。
结果
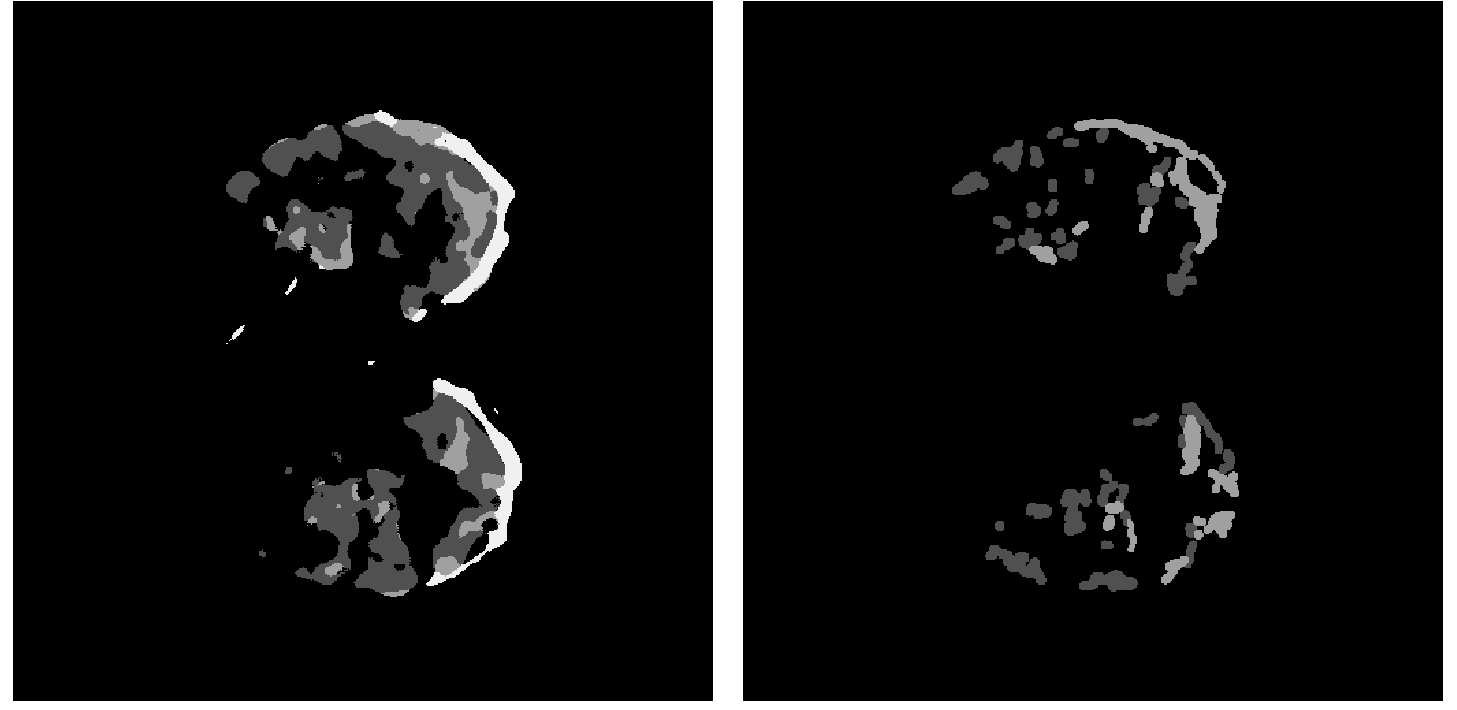
上图中的左图是CT扫描的模型输出,右图是手工制作的同一CT扫描图像的标签掩模。如你所见,它们都非常相似。该模型训练效果良好,总体评价准确率达到92%,评价损失为0.0166。下面的图表显示了每个时期的精确度和损失的进展情况。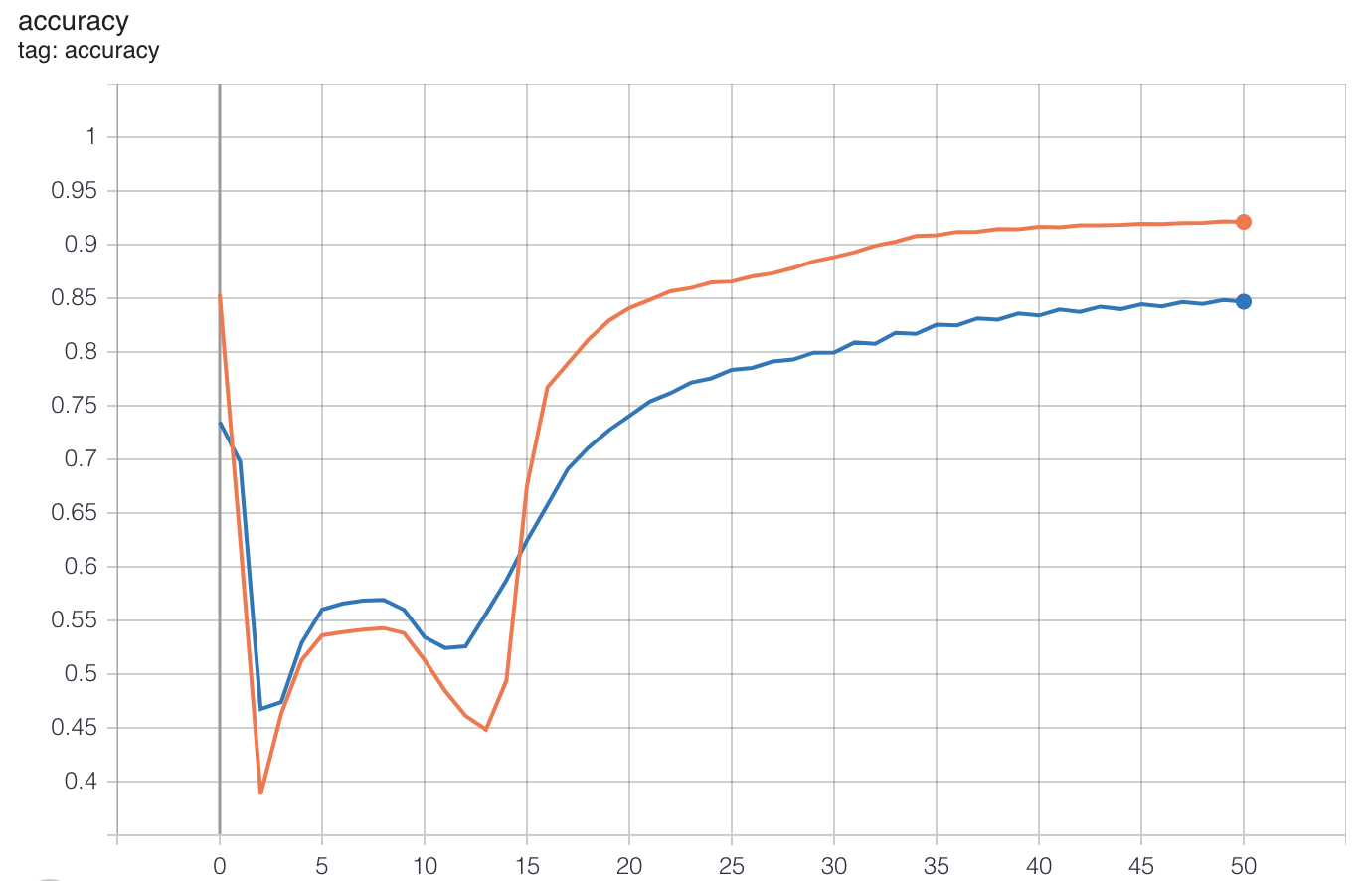
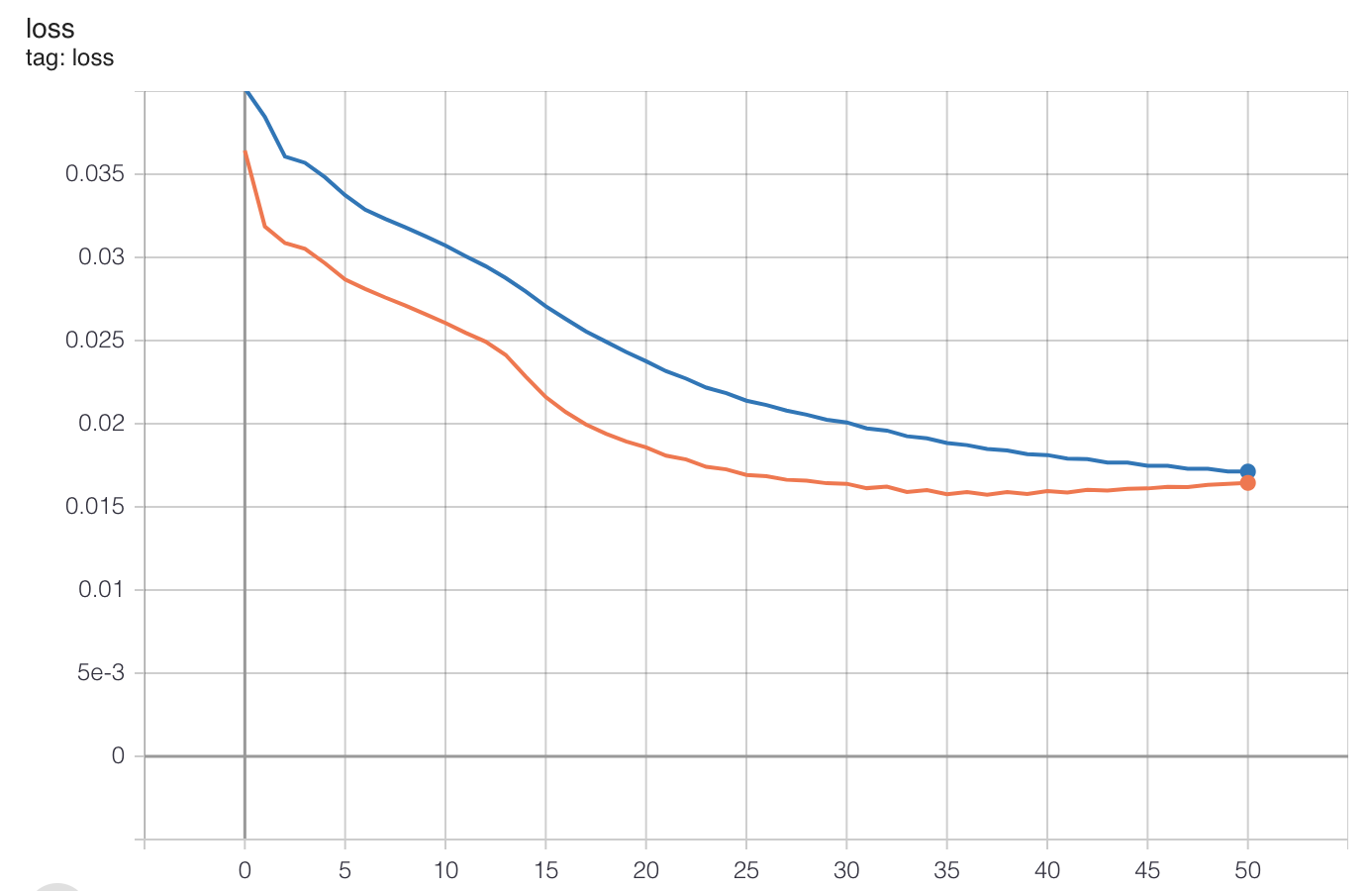
损失值在训练循环结束时开始趋于平稳,这意味着模型已经达到其最佳点,进一步的训练将导致过拟合。有迹象表明,可以通过向模型提供更大的数据集来满足改进范围,这可能会导致更好的结果。
凭据
上述研究论文的出版商持有知识共享署名4.0国际许可,该许可允许以任何媒介或格式使用、共享、改编、分发和复制,只要您给予原始作者和来源适当的信用,提供到知识共享许可的链接,并指出是否进行了更改。research paper Creative Commons Attribution 4.0 International License
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/06/24/%e5%9f%ba%e4%ba%8e%e6%b7%b1%e5%ba%a6%e5%ad%a6%e4%b9%a0%e7%9a%84%e8%82%ba%e9%83%a8%e6%9f%af%e8%90%a8%e5%a5%87%e7%97%85%e6%af%92%e6%84%9f%e6%9f%93%e5%8c%ba%e5%9f%9f%e6%a3%80%e6%b5%8b/
