

数字化,特别是互联网,不仅为我们提供了似乎取之不尽的文本数据来源,而且还提供了图像数据。在文本的情况下,这一宝藏已经通过BERT或GPT-3等语言模型以与任务无关的预培训的形式被解除。对比语言-图像预培训(简称:Clip)现在对图像做了类似的事情,或者更确切地说:图像和文本的组合。
在这篇博客文章中,我将给出一个粗略的非技术概要的剪辑如何工作,我也会告诉你如何尝试剪裁自己!如果你有更多的技术头脑并关心细节,那么我建议你阅读原版出版物,我认为它写得很好,很容易理解。original publication
背景
尽管过去十年在机器和深度学习领域取得了巨大的进步,但有一点批评依然存在:即使是表现最好的最先进的模型,学习效率仍然非常低。
考虑一下计算机视觉,特别是图像分类:当人类需要一个示例图像或可能需要几个图像来学习视觉概念并在新实例中识别它时,ML模型通常需要数千个图像才能实现与人类相似的性能。
问题不是没有足够的数据来填充ML模型,而是对于大多数培训任务,我们必须首先给它贴上标签-这通常是非常昂贵的。
但是,即使一群手动标签员努力产生像ImageNet(1400万张标记图像)这样的巨大注释数据集,并且我们在它上训练我们最好的模型,并且确实达到了人类水平的精度,甚至超过了它-那么,已经证明,这些模型在来自稍微不同的分布的数据集上的性能仍然非常差(例如,在照片上训练的图像分类模型通常不能识别对象的草图),并且很容易被敌意的例子所愚弄。
简而言之:即使是我们拥有的最大的手动标记的数据集也太小,无法使在它们上训练的模型很好地泛化。这个问题有两种可能的解决方案:要么开发更好的模型,要么提供更大、更多样化的数据集。CLIP攻击的是后者。
屏蔽语言建模
在自然语言处理任务的背景下,利用大量(未标记的!)以数字化形式提供的文本数据(例如,维基百科文章、数字化书籍)。
诀窍是自动生成标签。要做到这一点,一种方法是屏蔽语言建模。它有不同的变体,但一个简单的版本是将文本切成方便的小块,例如句子,并掩盖每句话一个词。然后,任务是猜测掩蔽的单词: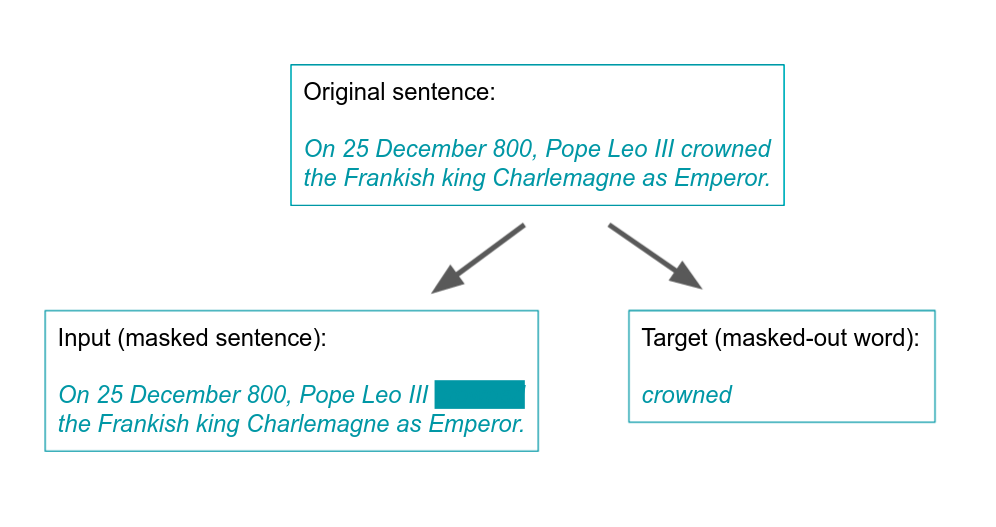
此程序允许定义受监督的任务,即使没有手动标签,也可以对像BERT这样的NLP模型进行培训。
如果以这种方式训练的模型只适用于预测掩蔽词,那么所有这些都不会很有趣。但事实证明,在这一过程中,他们经常学习有意义的单词嵌入,即编码统计语义关系的这种嵌入,这对所有类型的NLP任务都是令人难以置信的有用的。
夹子-基本理念
剪辑背后的基本思想非常简单。就像语言模型可以在没有人工监督的情况下对互联网上的大量文本进行训练一样,CLIP对图像也做了类似的事情。
其工作方式如下:
换句话说,CLIP假设我们确实有关于从网络上抓取的图像的有用信息,我们可以利用这些信息来定义受监督的预训练任务。图像标题类似于图像分类任务中的类别标签,但有一个明显的警告:对于后者,我们有固定的、通常数量相对较少的离散类别。相比之下,图像字幕更像是一个连续的类空间。为了理解此空间并使其元素可与图像相比较,Clip依赖于文本编码器。潜在空间使图像可以与文本相称,例如,在潜在空间中,我们可以比较图像的内容与某些文本描述的内容有多相似。
字幕和类别标签之间的所述差异也是为什么CLIP没有将训练目标定义为从图像生成字幕(这将是最接近于预测类别的事情),而是使用所描述的“对比”训练目标,即预测给定的字幕是否属于给定的图像。在连续的字幕空间中精确定位字幕太难了。
不过,正如我们将在下一节中看到的那样,CLIP产生的不仅仅是有用的预培训任务。
零射击学习
零镜头学习指的是预先训练的模型在没有事先看到新任务的任何示例的情况下执行它没有接受过培训的任务的能力(看到的是零示例,因此得名)。
剪辑模型实际上是一个可以通过“指令”调整的零镜头图像分类器。如果我们输入字符串“一条尖耳朵的狗。”进入文本编码器,模型将开始寻找显示尖耳的狗的图像。如果你更想对胖红猫的图像进行分类,只需告诉模型。

事实上,在实践中尝试这一点很容易。多亏了OpenAI和拥抱脸,你只需要以下几行代码:OpenAI and Hugging Face
这些URL属于我选择的图片,因为我认为它们很难与真正的“胖红猫照片”区分开来。然后,Clip的任务是判断“一只胖红猫的照片”是否更好地描述了这些图像。或者“不是一张胖红猫的照片。”(这种特定的否定可能不是定义“其他”类的最佳方式,请随意尝试其他提示)。CLIP为每幅图像输出两个相似度分数,对应于这两个类别,我们可以很容易地通过取Softmax将其解释为概率。
结果如下:
事实证明,我们能够愚弄狗,但没有其他图像-即使是苗条的红猫也不行。
Clip没有接受过这项特定任务的训练–它可能从来没有遇到过标题“一张胖红猫的照片”的标题。在训练场上。尽管如此,它仍然知道要查找哪些图像,因为通过文本编码器,它可以理解字幕中出现的单词(以及它们之间的关系)。
更系统地说,我们可以通过将所有类转换为字幕,例如通过“[类名]的照片”,将预先训练的剪辑模型转换为图像分类器。对于给定的照片,我们计算图像编码与所有字幕编码的余弦相似度,并选择得分最高的字幕(=class)作为分类器的预测。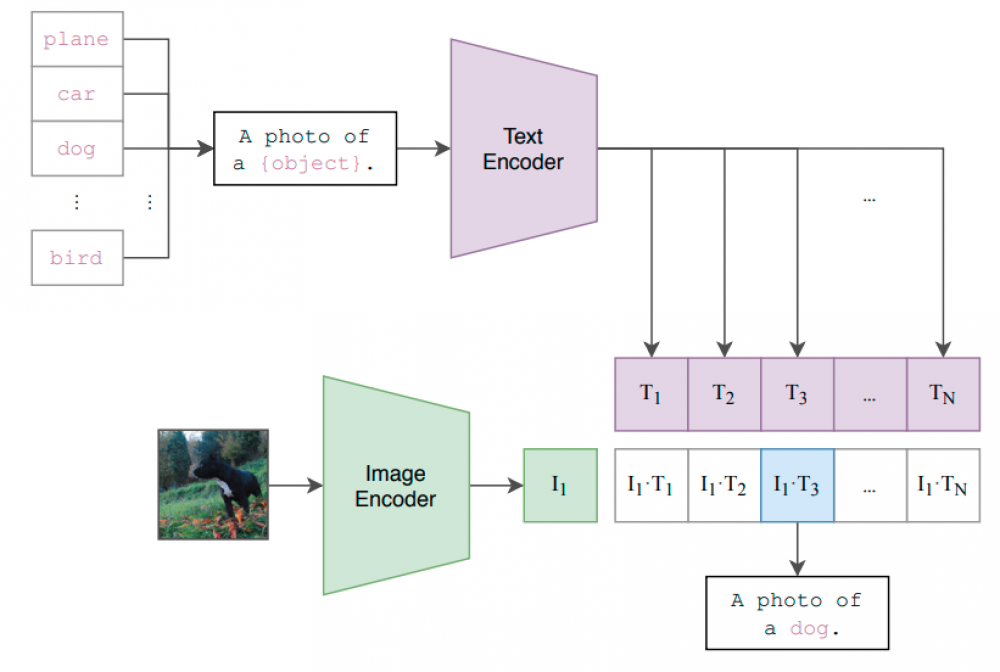
如果我们分类的不是照片,而是草图,甚至是各种类型的图像,我们当然可以调整标题。
事实证明,即使在特定的“窄”数据集(如ImageNet)上,基于片段的通用分类器的性能也与那些特别适合这些数据集的分类器类似。更重要的是,对于分布变化和对抗性示例,基于片段的分类器似乎更加健壮:
CLIP健壮性的原因似乎是它在训练过程中已经看到了更多不同的例子。事实上,Also Clip对其训练集中没有覆盖的图像类型的泛化效果很差。
还有更多直接应用CLIP或构建在其上的更复杂架构的示例。一个特别有趣的例子是StyleCLIP,它使用Clip创建基于文本的图像操作界面。StyleCLIP
结论
我发现剪辑模型及其应用有三个方面特别值得注意:
剪辑的高级大纲到此为止。我再次建议您看一下原稿,它使我所提到的很多内容在技术上更加精确。另一个有用的资源是OpenAI自己的博客文章,它也比我在这里讨论的稍具技术性。original paper OpenAI’s own blog article
最初发表于https://dida.do.https://dida.do
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/06/24/clip%ef%bc%9a%e6%8c%96%e6%8e%98%e6%9c%aa%e6%a0%87%e8%ae%b0%e5%9b%be%e5%83%8f%e6%95%b0%e6%8d%ae%e7%9a%84%e5%ae%9d%e5%ba%93/
