
深度学习系列
引言
尽管深度学习给计算机视觉和自然语言处理带来了革命性的变化,但使用当前最先进的方法仍然很困难,需要相当多的专业知识。
OpenAI方法,如对比语言-图像预培训(CLIP)?旨在降低这种复杂性,从而使开发人员能够专注于实际案例。
CLIP是在大集合(400M)图像和文本对上训练的神经网络。作为这种多模态训练的结果,可以使用CLIP来找到最能代表给定图像的文本片段,或者给出文本查询的最合适的图像。
这种特殊性使得剪辑对于开箱即用的图像和文本搜索非常有用。
它是怎么工作的?
对剪辑进行训练,使得给定一幅图像,预测该图像在训练数据集中与32768个随机采样的文本片段中的哪一个配对。其想法是,要解决该任务,模型需要从图像中学习多个概念。
这种方法与传统的图像任务有很大的不同,在传统的图像任务中,通常需要模型来从一大组类(例如ImageNet)中识别一个类。
总之,Clip联合训练图像编码器(如ResNet50)和文本编码器(如BERT)来预测一批图像和文本的正确配对。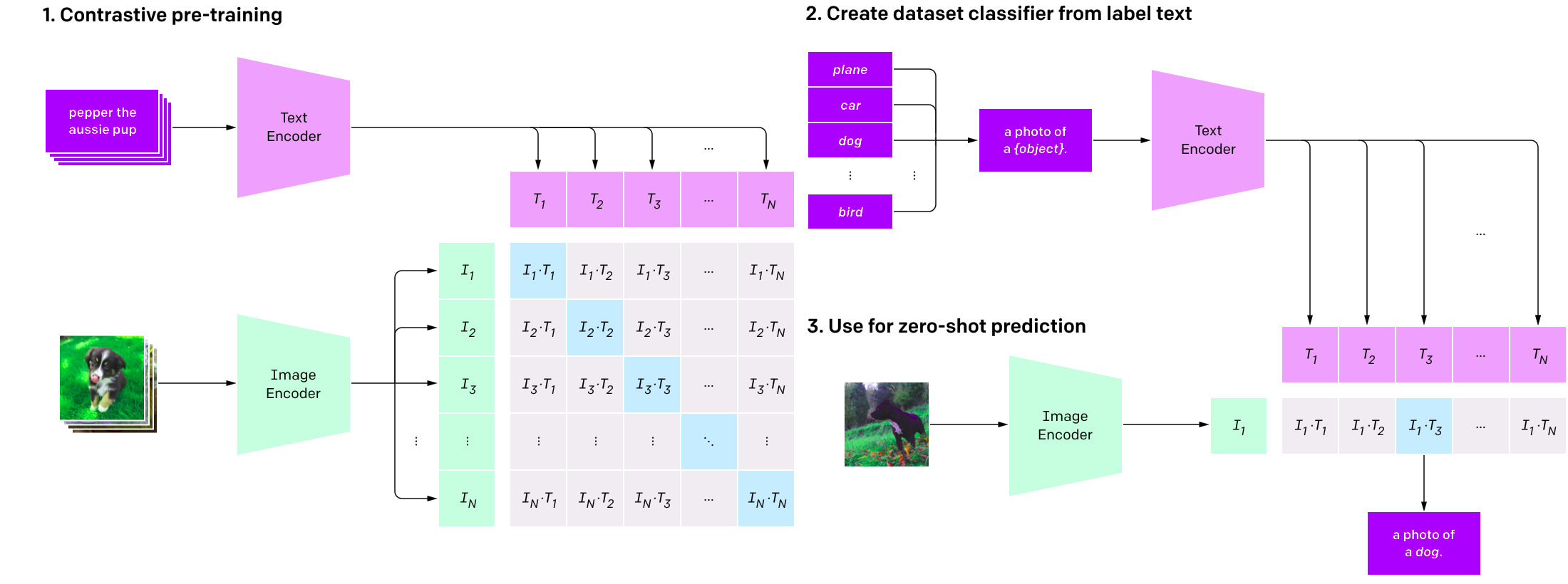
如果希望使用该模型进行分类,则可以通过编码并与图像匹配的文本来嵌入类别。这个过程通常被称为零机会学习。
快速入门
以下部分说明如何在Google Colab中设置剪辑,以及如何使用剪辑进行图像和文本搜索。
安装
要使用Clip,我们首先需要安装一组依赖项。为了促进这一点,我们将通过Conda安装它们。此外,Google Colab还将用于简化复制。
在浏览器中打开以下网址:https://research.google.com/colaboratory/https://research.google.com/colaboratory/
然后,单击屏幕底部的新Python3笔记本链接。
正如您可能注意到的,笔记本界面类似于Jupyter提供的界面。有一个代码窗口,您可以在其中输入Python代码。
2.查看Colab中的Python
要安装正确的Conda版本以与Colab协同工作,我们首先需要知道Colab使用的是哪个Python版本。要在CoLab类型的第一个单元格中执行此操作,请执行以下操作
这应该返回如下内容
/usr/local/bin/python
Python 3.7.103.安装Conda
在浏览器中打开以下网址:https://repo.anaconda.com/miniconda/https://repo.anaconda.com/miniconda/
然后复制与上面输出中指示的主要Python版本对应的miniconda版本名。miniconda版本应该类似于‘miniconda3-py{version}-linux-x86_64.sh’。
最后,在CoLab的新单元格中键入以下代码片段,确保CONDA_VERSION变量设置正确。
再次确认Python主版本仍然相同
这应该返回如下内容
/usr/local/bin/python
Python 3.7.104.安装CLIP+依赖项
康达现在应该准备好了。下一步是使用conda安装剪辑模型(pytorch、torchvision和cudatoolkit)的依赖项,然后安装剪辑库本身。
为此,请将以下代码片段复制到Colab中。
此步骤可能需要一段时间,因为所需的库很大。
5.将conda路径附加到sys
使用CLIP之前的最后一步是将CONDA站点包路径附加到sys。否则,可能无法在Colab环境中正确识别已安装的软件包。
文本和图像
我们的环境现在可以使用了。
要使用Clip Start,请导入所需的库并加载模型。为此,请将以下代码片段复制到Colab。
这应该显示如下所示的Return,表示模型已正确加载。
100%|███████████████████████████████████████| 354M/354M [00:11<00:00, 30.1MiB/s]2.提取图像嵌入内容
现在让我们使用以下示例图像测试该模型
为此,请将以下代码片段复制到Colab。此代码将首先使用PIL加载图像,然后使用剪辑模型对其进行预处理。
这应该会显示样本图像,后跟处理后的图像张量。
Tensor shape:
torch.Size([1, 3, 224, 224])现在可以通过从剪辑模型调用‘encode_image’方法来提取图像特征,如下所示
这应返回图像要素张量大小
torch.Size([1, 512])3.提取文本嵌入内容
让我们创建一组文本片段,其中不同的类值以以下方式嵌入:“a#class#的照片”。
然后我们可以运行CLIP标记器对片段进行预处理。
这应返回文本张量形状
torch.Size([3, 77])现在可以通过从剪辑模型调用‘encode_text’方法来提取文本特征,如下所示
4.比较图像嵌入和文本嵌入
因为我们现在有了图像和文本嵌入,所以我们可以比较每个组合,并根据相似度对它们进行排序。
为此,我们只需在两个嵌入上调用模型并计算Softmax即可。
这将返回以下输出。
Label probs: [[0.9824866 0.00317319 0.01434022]]不出所料,我们可以观察到“一张狗的照片”文本片段与样本图像的相似度最高。
现在,您可以使文本查询包含更多上下文,并查看它们的比较情况。例如,如果你添加“一只狗在草地上奔跑的照片”,你认为现在的排名会是什么样子?
完整的脚本
有关完整脚本,请通过以下链接转到My GitHub页面:
或者通过以下链接直接访问Google Colab笔记本:
结论
Clip是一种极其强大的图像和文本嵌入模型,可用于找到最能表示给定图像(例如在经典分类任务中)的文本片段,或在给定文本查询的情况下最适合的图像(例如,图像搜索)。
夹子不仅功能强大,而且特别容易使用。该模型可以很容易地嵌入到API中,例如通过AWS lambda函数可用。
[1]OpenAI。剪辑:连接文本和图像https://openai.com/blog/clip/#rf36https://openai.com/blog/clip/#rf36
[2]从自然语言监督者那里学习可移植的视觉模型arXi:2103.00020
arXiv:2103.00020
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/06/25/%e4%bd%bf%e7%94%a8openai%e5%89%aa%e8%be%91%e9%93%be%e6%8e%a5%e5%9b%be%e5%83%8f%e5%92%8c%e6%96%87%e6%9c%ac/
