
俗话说:“一幅画胜过千言万语”。我们的目标是检测图片中的单词并进行识别。文本检测,也称为光学字符识别,已经发现了许多应用,如护照识别、自动车牌识别、将手写文本转换为数字文本等。但这些都是具有结构化文本的受限环境的示例。真正的挑战在于当文本处于不受约束的环境中,而非结构化的文本。
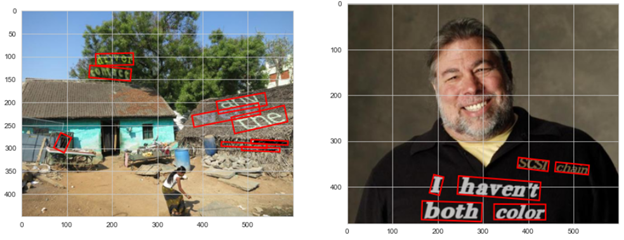
不受约束的环境:如复杂的背景、噪声、不适当的闪电条件、不同的字体和图像中的几何失真,如下图所示
非结构化文本:自然场景中任意位置的文本。文本稀疏,没有适当的行结构,背景复杂,在图像中的随机位置,没有标准字体。
附带场景文本识别被认为是文档分析社区中最困难和最有价值的挑战之一。附带场景文本指的是出现在场景中的文本,而用户没有采取任何特定的先前动作来使其出现或改善其在帧中的位置/质量。在日常生活中,文本存在于各种自然场景中,如路牌、店名、海报、招牌等,这些图像中的文本有时甚至有助于人们理解图像的语境。下面的图片可以给你一个完整的概念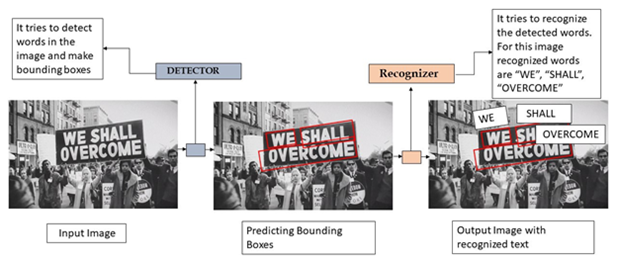
在传统的方法中,文本的检测和识别是按顺序进行的。在这项工作中,我们实现了Fots,它同时实现了检测和识别,减少了时间。拟讨论的内容如下
目录
2.机器学习上下文
3.数据来源
4.探索性数据分析
5.数据生成
6.Fots的架构
7.使用的损失
8.模范训练
9.推理流水线
10.下一步工作
11.提述
1.业务问题:
近十年来,文本检测与识别越来越受到计算机视觉领域的关注。由于它涵盖计算机视觉和自然语言处理的范围更广,因此具有巨大的商业价值。自然场景中的文本检测是一项具有挑战性的任务,比文档文本图像中的文本提取要复杂得多,因此,如果能有效地解决这一问题,它可以应用于文档分析、图像检索、机器人导航、自动驾驶汽车等众多实际应用中,更重要的是场景文本识别
2.机器学习问题公式:
从自然图像中提取文本的问题可以表示为一个两个阶段的过程:1)文本检测/定位。文本检测可以进一步表示为边界框回归,即获得文本的x、y坐标和每个像素的分类(无论像素是否为文本的一部分)。2)文本识别,即用实际文本对方框进行标注。FOTS将这两个阶段结合起来,同时进行,并允许训练端到端模型,以实现准确的文本检测和识别。利用深度学习技术,如CNNs,ResNet,LSTM,顺序解码器等,我们将以最小的损失执行这两种操作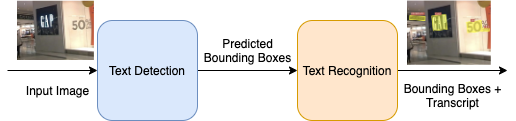
3.数据来源:
由于ICDAR 2015数据集不足以像研究论文所建议的那样训练Fots端到端模型,因此我们使用以下数据集来解决我们的问题,因此有大量的数据集可用于场景文本检测和识别
a)SynthText数据集:这是一个合成生成的数据集,其中单词实例放置在自然场景图像中,同时考虑场景布局,数据集由80万张图像和大约800万个合成单词实例组成。每个文本实例都使用其文本字符串、词级和字符级边界框进行注释。这对于探索性数据分析很有用,并帮助我们的机器学习场景文本的详细信息
b)ICDAR 2015:这是真实世界的数据集,其中包含来自可穿戴式相机的图像。与SynthText数据集相比,该数据集相对非常小(仅1000个训练图像)。
4.探索性数据分析(EDA):
通过EDA,我们得到了一些概括性的数据分布及其在合成数据集上的特征
将图像可视化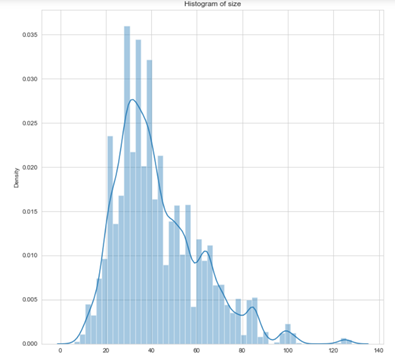
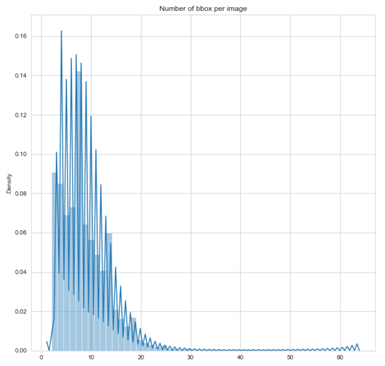
观察:可以观察到的
- 大多数图像的边界框都小于20
- 很少有图像的边界框超过60
- 边界框是根据地面实况数据计算的

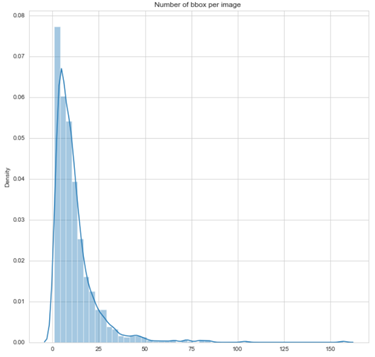
- 每幅图像的大多数边界框小于25

5.数据生成/地面真相生成
我们正在创建分别适用于文本检测分支和文本识别分支的生成器函数,这在训练这两个分支时都会很有帮助。为了训练Fots模型的文本检测组件,需要为训练该模型时将使用的每个原始图像生成以下地面真实掩码/图像
a.Score Map:-这是一个图像通道,表示对于给定图像中的每个像素,该像素是文本区域的一部分还是非文本区域的一部分(1表示文本区域,0表示非文本区域)
b.地理地图:-地理地图包含5个掩码/通道:对于作为文本一部分的每个像素,前4个通道预测其到包含该像素的边界框的顶部、底部、左侧、右侧的距离,最后一个通道预测相应边界框的方向。
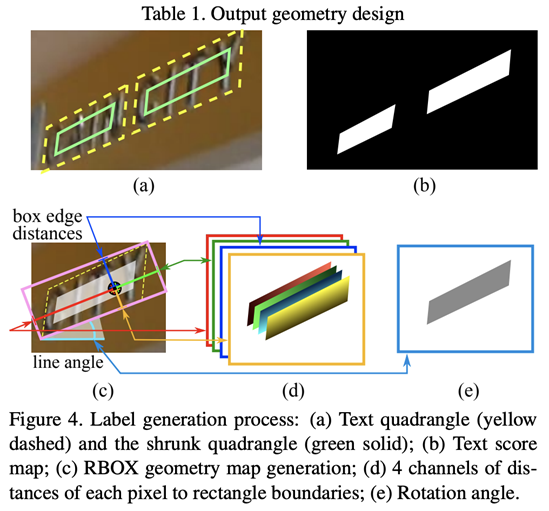
c.训练掩码:这是一张单通道图像,用于忽略非常小的包围盒和没有训练和损耗计算过程中抄本的包围盒。
因此,在训练模型之前,必须生成以下地面事实:1)得分地图,2)地理地图3)边界框列表4)文本抄本5)训练掩模
6.Fots的整体架构
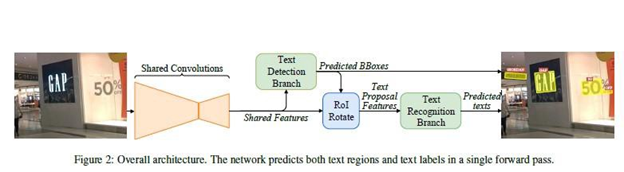
正如Fots白皮书中提到的,该模型由以下主要组件组成:
特征提取
为了从输入图像中提取高级特征,使用共享卷积层,并以预先训练的(在ImageNet上)ResNet50为骨干。共享卷积只不过是它们之间具有共享权重的卷积层。以下是共享卷积的架构: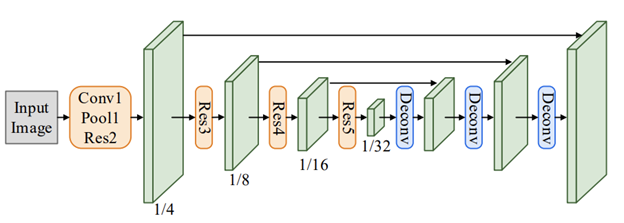
浅橙色块是用于特征提取的预先训练的ResNet-50层。浅绿色块是对应的ResNet50挡路的输出要素。DECONV挡路用于对输入图像/特征进行上采样,以增加输出图像/特征的大小。还要注意,低级功能直接与高级功能地图相连,高级功能地图在上图中显示为黑色箭头。
文本检测分支
对于文本检测分支,他们借鉴了高效准确的场景文本检测器(EAST)研究论文中的思想,其中文本检测分支采用全卷积网络作为文本检测器。这些卷积层将有5个通道用于记分图和地形图。一旦文本检测器分支提出了边界框,将使用位置感知NMS(非最大抑制)来获得在地面真实边界框上具有最高IOU的边界框。
ROIRotate(感兴趣区域旋转)
RoIRotate对定向/对齐的特征区域应用变换,以获得轴对齐的特征映射。以下是RoIRotate过程的直观可视化:
请注意,上图仅用于可视化。RoIRotate的实际实现操作通过共享卷积而不是原始图像提取的特征映射。
文本识别科
文本识别分支用于使用由共享卷积提取并由RoIRotate变换的区域特征来预测文本标签。考虑到文本区域中标签序列的长度,LSTM的输入特征仅通过沿宽度轴的原始图像的共享卷积减少两次。否则,将消除紧凑文本区域中的可辨别特征,特别是窄字符的特征。我们的文本识别分支包括一个顺序卷积(如VGG)、一个只沿高度轴递减的集合、一个双向LSTM、一个完全连接的最终CTC解码器。该部分主要类似于CRNN,结构如下图所示
上述Fots结构的工作原理如下:第一幅图像被馈送到共享卷积中,从中提取共享特征。共享卷积(共享特征)和文本检测分支(图像中的文本预测框)的输出被馈送到ROI旋转算子中,后者提取文本建议特征,然后将这些特征馈送到文本识别分支,文本识别分支由递归神经网络(RNN)编码器和连接式时态分类(CTC)解码器组成,用于识别和预测文本,最后将文本检测分支和文本识别分支的输出合并到一幅图像中,该文本识别分支由递归神经网络(RNN)编码器和连接式时态分类(CTC)解码器组成,用于文本识别和预测,最后将文本检测分支和文本识别分支的输出合并到图像中由于该网络中用于模型的所有损耗都是可微的,因此整个网络可以端到端地训练。
7.使用的损失
在这个问题中,我们分别训练检测和识别部分,对于这些部分,我们使用不同的损失进行检测和识别,如下所示
1.骰子损失-此损失用于文本检测分支,用于将输入图像中的天气像素分类为文本区域或非文本区域。请参考这个Refer this
2.IOU(交集超过并集)损失:这是我们在培训文本检测科时使用的第二个损失,用于在文本区域周围生成正确的边界框。请参考这个Refer this
3.CTC(Connectionist Temporal Categical)损失:该损失用于训练文本识别分支将检测分支预测的边界框中的文本转换为实际文本。请参考这个Refer this
8.模范训练
为了解决这一问题,由于合成文本数据集非常大,即800k图像(41 GB),因此由于计算能力较小,不可能从整体上训练我们的模型。因此,作为解决方案,我们从该数据集中随机选择10k张图像,并使用它们来训练我们的模型。
对于模型训练,我们基本上将整个训练过程分为检测和识别两个部分,分别对检测和识别模型进行训练,最后将两者结合ROI旋转进行推理。下面讨论这些分支机构的概述培训
文本检测分支
这个分支我们使用与上面提到的相同的体系结构,即,我们使用共享卷积,这些卷积是在使用Resnet50作为其主干的ImageNet数据集上预先训练的。在这里,我们首先将图像缩小1/32倍,然后再将其放大1/32倍。在培训这个分支机构时,我们使用了2种损失,骰子损失和欠条损失。
为了避免骰子损失超过欠条损失,我们使用了完全损失,如下所示:
损失=0.01*骰子损失+欠条损失
以下是检测分支的代码
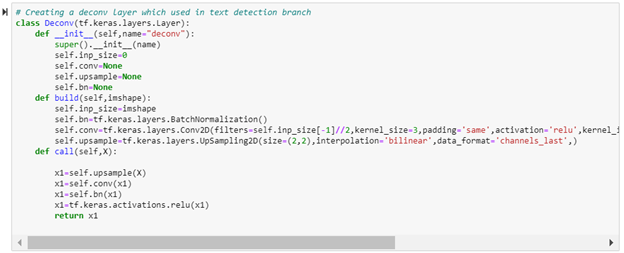
在这里,我们在训练时使用了各种张量流回调,例如:
1.Reduce on Platform回调:-用于当我们的模型权重在局部Minima上卡住时,降低学习率。
2.模型检查指向回调:-用于在训练时保存模型权重。
3.张量板回调:-用于可视化张量板中各层的损耗和权重。
文本识别科
我们利用5k合成文本数据点,并将其与ICDAR数据点相结合,从图像中提取文本框,用于训练识别分支,这是因为ICDAR数据太小,仅基于这些数据的训练模型会导致过度拟合。
我们使用了与上面提到的识别分支相同的体系结构,其中我们使用了一系列卷积操作,然后是批归一化、重新激活和最大合并(仅沿高度轴将维度减少一半)。
代码仍在处理中
9.推理流水线
最终推理流水线由文本检测(包括共享卷积)、感兴趣区域旋转和文本识别三部分组成。在ROI旋转中,我们通过使用文本检测分支预测的得分地图和地理地图来生成文本出现在图像中的方框的坐标。在获得图像上预测边界框的坐标后,将这些生成的边界框传递给文本识别分支,以从图像中特定的文本区域获取文本。
以下是来自最终管道的几个结果

由于缺乏计算资源,我们无法对整个数据进行检测和识别模型的训练,所以没有得到理想的结果。但这些结果可以通过对整个数据进行模型训练来改善。
10.下一步工作
11.提述
12.链接到个人资料
giHub存储库:https://github.com/dhekanesm/Fast-Oriented-Text-Spotting-FOTShttps://github.com/dhekanesm/Fast-Oriented-Text-Spotting-FOTS
Linkedln个人资料:https://www.linkedin.com/in/sandeep-dhekane-9747171b8/https://www.linkedin.com/in/sandeep-dhekane-9747171b8/
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/06/25/fots-%e5%bf%ab%e9%80%9f%e5%ae%9a%e5%90%91%e6%96%87%e6%9c%ac%e6%a3%80%e6%b5%8b-%e4%b8%80%e7%a7%8d%e5%bf%ab%e9%80%9f%e6%a3%80%e6%b5%8b%e5%92%8c%e8%af%86%e5%88%ab%e5%9c%ba%e6%99%af%e6%96%87%e6%9c%ac/
