
这个博客有一个独特的目的,那就是帮助宠物店老板(理论上)使用深度学习/计算机视觉识别进入他们店的狗的品种。在这篇文章的最后,多亏了fast.ai,人们应该可以毫不费力地构建一个图像分类模型。为了简单起见,这个模型训练了4种不同的品种:可卡犬、比格犬、拉布拉多犬和使用冰的金毛猎犬。fast.ai bing
不要再费劲了,让-euro™直接开始编写代码吧。我们需要做的第一件事是导入必要的库,并从Bing search下载训练图像。我们将使用“EUROURE˜-BING-IMAGE-Downloader”“EURO™”来完成此操作。请参见下面的内容:
一旦我们运行下载程序,我们将为每个品种提供100个图像[LIMIT=100]来训练模型。这可以根据我们希望如何训练模型来增加/减少。我们总共有大约400张图像,因为一些图像可能会因为差异而被过滤掉,也可能不会被过滤掉。为了验证图像是否已下载到我们的目录中,我们运行以下代码。
其想法是验证映像是否有效,并取消链接/删除失败的映像。正如您在下面看到的,我们从Bing下载的图像已经存储在指定的路径中,其中属于每个类别(Breed)的图像位于各自的文件夹结构下(在本例中为Labrador)。
数据挡路和数据加载器
一旦我们在指定的路径中获得了图像,就可以使用™数据块API了(如下所示)。我们™基本上是试图告诉Fastai将下载的图像转换为DataLoaders对象的四件事:确定模型必须处理的数据类型、递归地获取模型的项目列表、标记项目并启动验证集。为此,我们使用数据挡路接口。
第一个元组-欧元˜块-欧元™由用于进行预测的自变量和作为目标的因变量组成。在我们的例子中,图像是自变量,品种是目标/类别。第二部分是底层项目集,它将是文件路径。-uro-˜GET_IMAGE_FILES-EURO™就是通过递归返回该路径中的图像来实现这一点的。欧元随机拆分器(˜RandomSplitter)™执行训练和验证分离,留下20%用于使用随机种子进行验证,从而确保每次运行验证集时都保持不变。至于标签,FastAI使用?EUEURE˜PARENT_LABEL?EURO™函数根据父文件夹(品种名)为图像添加标签。
因为我们下载的图像可以有不同的大小和形状,所以我们应用-Euroresize?˜™转换将图像大小指定为128像素。数据挡路对象几乎充当我们的数据加载器的模板。数据加载器由批量训练和验证集组成。在上面的示例中,我们运行的是-euro˜dls.valid.show_Batch(max_n=8,nrow=1)-euleBatch,因此我们在一行中从验证集中获得了8个图像。[在这里输出样本,单元格11。]here
挤压/填充/最小比例图像
未经训练的模型通常不知道图像何时轻微旋转或弯曲,因此有时使用由轻微弯曲、挤压的图像组成的图像数据来训练神经网络可能是有用的。(™)然后是-uro™的min_scale,它告诉模型每次需要选择多少图像。这些概念中的大多数(如果不是全部的话)都是有问题的。例如,挤压的图像可能会导致不真实的形状,填充的图像可能会导致空白空间,这在计算方面基本上是浪费的。此处显示了单元格12、13、14[使用UNIQUE=FALSE查看不同形式的相同图像]的示例以及图像在挤压、填充和使用min_scale时的外观:here
这让我们对这些功能如何影响图像的形状/大小/质量有了一些直观的了解。这些都很重要,因为模型需要了解图像组成的基本概念以及表示图像的方式。
数据增强
沿着这些思路,另一个有用的概念是数据增强。它基本上是在不改变其含义的情况下创造我们的图像的随机变化的过程。可以增加数据的一些方式有:“EURO˜Rotation”、“EURO™”、“EURO˜Flip”、“EURO™”、“EURO˜BIGHTENCE CHANGE”、“EURE™”,仅举几例。我们可以将其中一些增强应用到我们的图像上,看看模型如何从图像本身的不同形式中学习。
iâuro™使用了-uro˜Unique=False-euro™,所以我的输出返回不同图像的不同放大效果。您可以随意尝试使用-EUROURE˜UNIQUE=TRUEURE™在同一图像上查看不同的放大效果。
模范训练
我们现在已经准备好训练我们的图像分类器了。我们使用带有?EUROU˜RESNET 18?EUROU™参数的学习器来训练模型。我们将模型调到4个纪元,并使用念力矩阵来解释我们预测的标签的结果。
模型历元将返回历元编号、Training_Loss、Validation_Loss、Error_Rate和每个历元花费的时间。下面显示了一个输出示例,其中包含模型返回的念力矩阵的快照。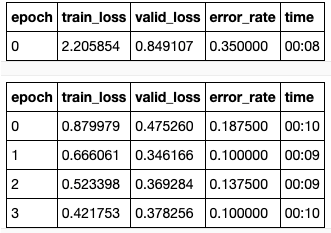

正如我们从两张快照中可以看到的:“我们的训练损失和错误率在每个时期都下降得相当好,念力矩阵在大多数情况下都设法准确地预测了每个标签。让我们来看看欧元™‘s的最大损失(模型做出的一些错误预测)。正如我们在这里看到的19号细胞,模型预测-欧元˜拉布拉多犬-欧元™在第一幅图像,而不是在第二幅图像中的“欧元˜可卡犬猎犬-欧元™和”欧元˜金毛猎犬-欧元™,而不是“欧元˜拉布拉多”欧元™,虽然第二幅图像也包括一个人,所以它-欧元™不是最具代表性的图像。here
™有一些很酷的东西,我们可以用这些不想要的图片来做。我们可以使用名为“EUROURE˜ImageclassfierCleaner?™”的图形用户界面进行数据清理,它允许我们从不同的集合中清除脏图像(按类别分类)。让我们?Euro™‘s来看看吧。
确保只在使用小部件删除图像的情况下运行-eulewider.delete-˜™。小部件显示在这里。here
模型推理
我们现在有一个训练有素的模型可供推理。让âuro™‘s继续运行一个应用程序,根据我们上传到小部件的图像对狗的品种进行分类。
我们走吧。我们已经有了自己的应用程序,可以预测一只狗是否属于我们训练的模型中的四个品种之一。这个博客最酷的地方在于,您可以通过下载不同的图片,将整个模型用于完全不同的目的。例如,一个有趣的用例可能是下载健康皮肤与不健康皮肤的图像,并让模型根据这些数据进行训练。还有很多其他的例子,你可以用来做一些很酷的事情,所以你可以自己尝试一下,弄脏你的双手。您可以在这里找到GitHub回购。here
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/06/28/%e8%ae%a1%e7%ae%97%e6%9c%ba%e8%a7%86%e8%a7%89%ef%bc%9a%e5%93%81%e7%a7%8d%e6%a3%80%e6%b5%8b%e5%99%a8/
