
作者:史蒂文·沃尔顿,阿里·哈萨尼,阿布力克木·阿布杜维利,汉弗莱·施。史实验室@俄勒冈大学与PicsArt AI研究(配对)
在本教程中,我们将介绍紧凑型变压器-计算和数据高效变压器-普通人可以在他们的家用计算机上(快速)进行培训,并获得计算机视觉和NLP分类的最新结果。如果您想学习如何编程和培训转换器,但没有一堆花哨的GPU,或者手头的任务需要您处理较小的数据集,那么这是适合您的教程。
变形金刚:他们知道什么?他们知道些什么吗??让我们来看看吧!
变形金刚是机器学习中挡路上最受欢迎的新生代。但他们到底是谁?他们为什么会在这里?它们只是一些流行的新工具,还是真的是一个突破?这些模型是否仅限于拥有大量计算资源和数据的大型实验室,或者它们对您和我这样的普通人有用吗?
通过本教程,我们将分解上图的每个部分,并弄清楚如何创建我们自己的视觉变形金刚。然后我们将讨论如何创建一个更民主的模型,它明显更小,允许您在自己的机器上进行训练和测试,即使您没有最新的硬件,或者即使您没有GPU。我们将从变形金刚编码器开始,首先从最困难也是最重要的部分开始:注意。所以…
请大家注意一下好吗?:注意机制
当人类观看场景时,他们只关注场景中重要的东西。这是有帮助的,因为这样我们只需要处理关于什么是重要的信息,就可以忽略睡觉。如果我们能用机器学习做一些类似的事情,那将是有利的。
这种相似之处被称为注意力。关注的形式很多,但有一个共同的方面特别突出。它们的形式是:注意=相似性(q,k),这里q表示查询(问题),k表示关键字。我们需要这两件事之间的相似性,因为我们希望找到与我们的问题/查询最匹配的关键字。您可以将其视为访问数据库。我们有想要找到的东西,所以我们查询数据库以查找我们想要的信息。
看一下不同的注意力方程式(图1),我们可能会注意到它们都在做一些相似的事情。关于这篇文章,我们将只关注“点状产品自我注意”(等式)。1),但是我们将把这个等式分解成它的基本原理;你将能够应用这些知识来帮助你理解其他类型的注意力。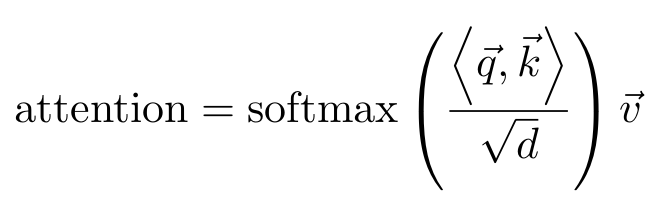
首先,让我们看看里面,我们看到
好的,现在让我们看完Softmax函数的内部,我们仍然有那个√d项。那是我们的秤。你可以认为这只是一种让数字变得不那么大的好方法。D表示向量的维数,因此这将使计算变得更容易。如果d太大或太小,Softmax可能会产生不好的渐变,所以我们只想稍微缩小一下(缩放是数据争论中的常见过程,但我们始终需要小心缩放方式,以免引起偏差)。
现在我们出发吧,我们有了Softmax功能。我们可以把它看作是把我们的函数变成概率分布的一种方式。Softmax函数表示每个元素都在0到1之间,总和是1。就像任何概率分布一样。softmax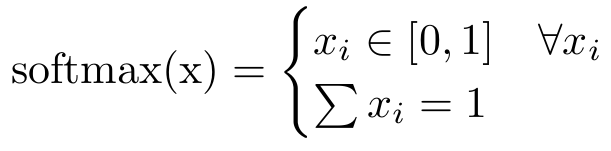
我们为什么要这个?嗯,因为我们想告诉我们的算法应该注意什么。如果我们的注意力分数是0,那么我们就不会注意那些部分,如果我们的注意力分数是1,那么我们只关心那一个像素(这与一个热点向量相同)。有一个概率分布使我们更容易进行计算,因为我们可以保留我们所有的奇特统计数据(例如,我们可以计算可能性)。 likelihood
现在我们有了最后一个组成部分,是什么让这种“自我关注”呢?这其实是最简单的部分。这意味着我们要将这一点应用于…它本身。我们的向量q和k实际上是神经网络(通常是线性的),如果它们有相同的输入(q(X),k(X)),那么它们是自关注的(我们的v也需要相同的输入v(X))。
因此,我们对(√d)点积(
在我们继续讨论转换器之前,我还想带您进行另一个类比,这就是为什么我们使用这个查询,键,值,“胡说八道”的原因。我们实际上可以把它看作是一个我们试图获取值的数据库。为此,我们有一个查询来帮助我们查找具有相应值的键。这应该有助于我们更好地联系在一起,为什么我们需要q和k之间的一些相似性。我们只是想学习一种方法,以确保我们的查询抓住适当的键。
现在我们就知道了。我希望我能够通过所有这些吸引您的注意力,现在是一些代码。
我们在这里利用线性层的一个很好的技巧,我们可以只使用一个层,它的作用就像我们有三个不同的层,一个用于Q,K和V,因为层之间没有相互依赖,我们可以认为这些层是模块化的。我们稍后还会看到类似的戏法,不过是卷积。
视觉变形金刚:不仅仅是与眼睛相遇
瓦斯瓦尼说,你只需要注意,但我们还需要一些变压器的东西。对于Vision Transformers,我们只需要查看编码器,但如果您希望全面了解变形金刚,这仍然会有所帮助。 Attention Is All You Need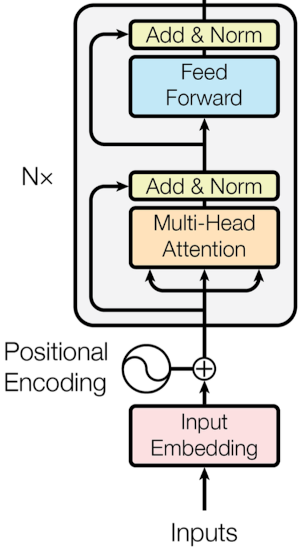
我们将从底部开始,然后向上移动。这看起来可能有些吓人,但我们已经涵盖了这个网络中最复杂的部分–注意力。我们只需要再多一点就可以把它变成我们的变压器模型了。
输入嵌入是网络中最简单的部分。有很多方法可以做到这一点,你必须进行一些试验。这只是一种获取数据并以不同方式表示它的方式。您可以通过修补(一张图像相当于16×16个字)、卷积、线性网络或其他方式来实现这一点。我们稍后会更多地讨论这个问题,但现在只需将其视为“接收数据”即可。我们将这些嵌入的数据称为令牌。An Image is Worth 16×16 Words
位置嵌入
位置嵌入是一个极其简单的概念,但对于新手来说,通常会被小题大做,所以让我稍微分析一下。如果您不需要这个,只需知道PE是我们表示数据如何在位置关系中排列的一种方式。我们需要这个,因为我们使用的是数据序列,如果我们不添加有关数据如何位于序列中的信息,我们将很难了解序列之间的关系。
让我们快速了解一下PE最常见的形式,即正弦嵌入。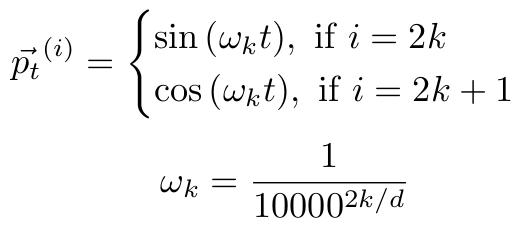
如果您不熟悉波/信号,那么只需知道我们有两个波是异相的,并且它们的频率很高(ωₖ)。偶数频率由sin给出,赔率由cos给出(sin和cos相差90°)。利用高频和相位偏移,我们可以向我们的网络传输大量的信息。一个简单的插图将比我能写的任何东西都更好地说明这一点,所以给您。
从这里你可以看到图像,我们得到了一个非常有表现力的表示,它将对我们的每个位置参数进行不同的加权。每个点表示我们在其嵌入空间中的相应位置给予令牌的偏移量。完成这项任务的任何函数都可以,即使是学习过的函数。通常情况下,我们只想要高频的东西来保持稳定性。在实践中,大多数人发现可学习的体育和固定的体育之间没有太大的区别,所以你通常会看到上面的一个。
多头自我注意
我们又开始注意了,但这一次我们有多个头。我们已经学习了困难的部分,我们只需要知道这个多头是什么意思。那么如果我们考虑关注度,我们可以说它是表现成对数据的关系。如果我们有两个注意力头,那么我们就可以得到成对的。三?成对的。诸若此类。您可以看到这是如何极具表现力的,但同时也可能引入太多的复杂性。一个头通常做得很好,但这只是你要搜索的另一个超参数。因此,让我们修改上面的代码,使其成为多头关注的对象。我们唯一真正的区别是将嵌入维度除以磁头数量,然后更改比例因子。但是现代的注意力网络,就像你会在PyTorch的图书馆里发现的那样,要比这个复杂一点。所以让我们边做边做这些修改吧。 PyTorch’s library
我们可以看到,我们在这里添加了一些东西。偏差变成了一个参数,我们可以用它来获得一些额外的表现力。我们添加的两个重要部分是辍学和投影层。丢包是防止网络过拟合和提高网络泛化能力的重要工具。在这里引入这一点可能会有类似的效果。我们用来投影所有成对…的投影层使我们的网络能够权衡这些特征。这很有帮助,因为正如您可能想象的那样,并不是所有的n对都一样有用。 dropouts
编码器
现在我们已经解决了复杂的部分,让我们构建转换器编码器的睡觉。我们真正需要做的就是把一些东西放在一起,并添加一些剩余的连接!
向前部分已被拆分,以便从上方看起来像变形金刚编码器图像。就这样!我们创建了一个转换器编码层!您还可以在此处添加辍学。但从代码中您可以看到,我们接收数据,添加一些位置编码,通过MHA层发送,使用剩余连接,然后我们添加和标准化,通过前馈网络发送,添加残留层,然后再次标准化。您可以任意多次重复此编码层,但要小心,因为参数的数量将快速增长。
我们应该只剩下两个问题:“为什么会有残余连接”和“为什么会有正规化层?”剩余连接是一种常见的深度学习技术,它允许我们以更稳定的方式构建更深层次的网络,请参阅ResNet。残留层更容易优化,因此如果您使用深度神经网络,请确保将其包括在内。归一化将我们的数据返回到正态分布,均值为0,方差为1。层归一化是另一种有助于稳定网络和提高训练速度的技术。 ResNet normalization
16×16字,视觉变形金刚
视觉变压器(VIT)是一类应用于视觉问题的变压器。Dosovitski等人介绍了“一个图像相当于16×16个单词”,他们展示了第一个完全由变压器组成的图像分类器。但我们现在是变压器方面的专家,所以问题是:“我们如何重复他们的实验?”(研究和学习的一个重要部分是复制结果)。让我们看一下它们包含的图像。 Dosovitskiy et al
如果你看着这张图片说“等等!我可以做到的!“那就祝贺你自己吧!如果你不这么做,那也没关系,我们无论如何都要谈谈这件事。我不想谈的是那个标有“变形金刚编码器”的灰色大盒子,因为我们刚刚谈完^_^。请注意,在MHA和MLP之前有一个标准化,相应地更改编码器。
剩下的唯一要讨论的事情就是打补丁了。这篇论文的标题让我们走了一半的路。“一张图片相当于16×16个字。”所以让我们把图像分成16×16的块,当然有3个通道。这非常简单,我们知道如何使用一些基本的python技能来做到这一点。然后,我们只需要平整图像块,并通过嵌入层(变压器模型的标准)发送它们。那我们就完事了!
每个面片表示序列(或“单词”)中的一个元素,并通过嵌入层发送,嵌入层仅将其从其原始像素空间(16×16×3)映射到d维空间。
嗯,如果我们回想一下卷积是如何工作的,我们可以在这里应用一个技巧!卷积是将内核操作应用于该数据窗口的滑动窗口。那么,为什么我们不做一个补丁大小的窗口,滑动它,这样就不会有重叠,并且内核不会对图像进行操作呢?具有16和d个滤波器(d×(16×16×3))的跨度和核大小的卷积运算将等同于打补层。砰!用卷曲打补丁!我们可以简单地写成:
现在,我们实际上并没有将内核设置为无操作(1矩阵)。我们也可以使用它作为我们的嵌入层。我们一举两得!所以我们要做的就是把它压平,然后我们就可以开始了。那么现在让我们让我们的视觉变形吧!
好吧,我有点鬼鬼祟祟的往里面扔了点我们没看到的东西。如果你回头看这张VIT照片,你也会注意到一些棘手的事情。在“Patch+Position Embedding”下面有一个小星号,MLP头从变形金刚编码器的左侧出来,而不是从中间出来。这实际上是在告诉我们一些信息。与许多转换器一样,VIT使用类令牌作为额外的可学习参数(我们使用nn.Parameter来完成),并且MLP头部在左侧,以指示我们将获取对应于该类令牌的数据(也在最左边的位置)。最后,我们可以使用nn.CrossEntropyLoss进行训练。
就是这样!我们创造了一个视觉转换器。您可以看到,这可能比您想象的要容易得多!
但这里有个大问题。我们在论文引言的末尾隐藏了一句重要的台词:
然而,如果模型是在更大的数据集(14M-300M图像)上训练的,则情况会发生变化。我们发现大规模训练胜过归纳偏差。
对于拥有巨型电脑和大量资源的谷歌大脑团队来说,这可能不是问题。但这对我们大多数人来说是个大问题。我的意思是,我们甚至不能训练ImageNet,而这被认为是“中等”大小的数据集!那么我们这些微不足道的凡人是做什么的呢?如果转换器需要数据,那么这又有什么意义呢?学术好奇心?不是的!我们将进行一些更改,以克服这些问题,并使视觉转换器对您有用!是的,即使你没有图形处理器!
面向凡人的视觉变形金刚:紧凑高效的变形金刚
正如我们刚才所展示的,视觉转换器(以及一般的转换器)很容易理解和实现。然而,该体系结构通常使用大量的训练数据(VIT、GPT、ERT等)进行大规模使用。考虑到VIT,在应用到较小的数据集(例如ImageNet->CIFAR10)之前,您可以在大数据集上进行预训练,从而获得更好的性能。不过,别着急!我们有一些技巧可以解决其中的一些问题。
较小的胸腔
原始论文中介绍的VIT变体(VIT-BASE、VIT-LABLE和VIT-GUGGE)在JFT-300M上进行培训并转移到其他数据集(无论是小型数据集(CIFAR-10)还是中型数据集(ImageNet))时被证明非常有效。同样的模型也在ImageNet上进行了预训练,但效果较差。在较小的数据集(如CIFAR-10)上进行预训练会导致严重的过度拟合,以至于在训练集上几乎没有错误,而在测试集上的表现却很糟糕。
基础VIT变体(VIT-Base)由12层12头组成。这个模型大约有8600万个可学习的参数。太多了!相比之下,ResNet50约有2300万,ResNet18约有1100万。现在过度拟合是有意义的,因为参数的数量能够学到更多,它最终会记住一些东西。
这就是为什么我们可以做一些非常简单的事情来避免这种情况:较小的模型。以下是我们发现有用的尺寸: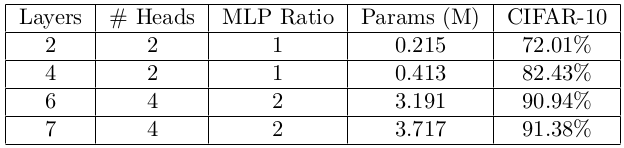
面片大小被设置为4,而不是原来的16,因为我们处理的图像要小得多(32×32而不是224×224)。这提高了性能,但由于增加了序列长度,可能会降低(相对)速度。
紧凑型变压器
即使是小型VITS,其性能相对较弱,参数也很多。我们需要一些方法来提高性能,而不会大幅增加模型的大小。我们的紧凑型变压器,在使用紧凑型变压器逃离大数据模式中推出,使我们能够做到这一点。随着0.07M参数的增加,我们可以将性能提高17%以上!这使得这个模型足够小,您甚至可以在旧的GPU上训练它(而不仅仅是运行它)。事实上,我们已经能够在CPU上进行训练(30分钟到80%)。 Escaping the Big Data Paradigm with Compact Transformers
要实现这一性能,我们不需要做太多修改(请记住,研究是递增的。即使是VIT也只是对“变形金刚”模型做了一些细微的修改)。
从上面的图表中,您可能会注意到只有两个较大的变化。第一个是在CVT中引入的,即序列池,简称为SeqPool。要做到这一点,我们只需要向构造函数添加另一个线性层(称为注意力池),在前进过程中,我们将对该层进行Softmax,然后矩阵将其与输入x相乘(您甚至可以只使用nn.Parameter,但是线性层表现出了更好的性能)。当VIT分割出相应的类令牌位置并将其传递到MLP层时,我们利用了所有信息。我们软化这一点是因为它本质上告诉我们的网络最应该关注变压器编码器输出的哪些部分。这意味着我们的网络中不会浪费参数。所有的东西都是用过的。
下一项创新,正如人们看到的那样,正在向CCT迈进,也很简单。打补丁,就像在VIT和CVT中所做的那样,有一些固有的问题。我们的网络将很难理解补丁之间的边界信息。在没有做其他事情的情况下,我们基本上只是在每个补丁上进行注意,然后确定这些注意是如何关联的。我们可以把这称为关系归纳偏差。相反,让我们使用重叠的卷积,并使用MaxPool。这应该会在我们的模型中引入一些关系偏差,并允许我们的转换器了解更好地嵌入的信息。
这是向前迈出的重要一步,因为重叠卷积对于空间平移是不变的,并且具有较低的关系归纳偏差。这就是CNN在视觉上如此成功的部分原因。这里和那里还有一些其他的小改动,这推动了性能的进一步提高,但这是模型的核心。以下是不同变种及其性能的汇总: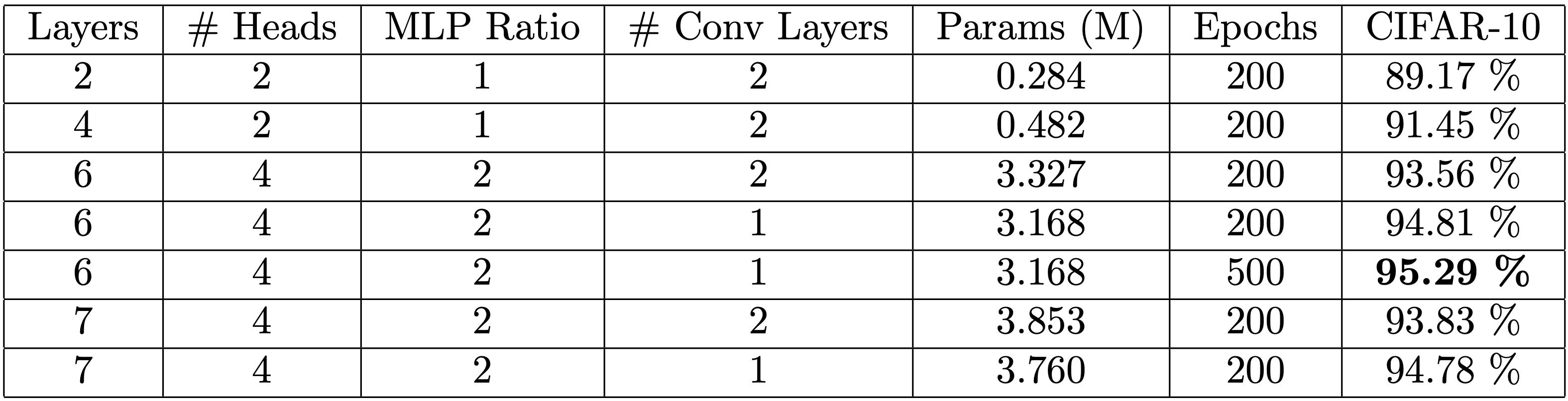
在表2中,我们注意到较少的卷积层数实际上有助于提高大多数模型的性能。我们最好的模型在CIFAR-10上的准确率超过95%,参数刚刚超过300万。应该注意的是,额外的300个历元仅提高了约0.5%的精度。唯一击败我们的ResNet是ResNet-1001,它有10M个参数,最高准确率为95.38%。ResNet-1001
我们还组装了一个Google Colab笔记本,它在CIFAR-10上只训练我们最小的模型10分钟,达到80%的TOP-1准确率。实际上,您可以使用它来查看来自CIFAR-10的随机绘制的图像以及它们的原始和预测的类别标签。 Google Colab Notebook
扩展到ImageNet
我们的模型还扩展到更大的数据集,如ImageNet。目前的模型规模很大,参数数量增加很多。这是因为嵌入维度随着模型大小的增加而增加。我们应该在这里注意到MAC,我们不认为我们的ImageNet模型具有最佳性能。像许多阅读本教程的人一样,我们也受到计算资源的限制,没有像在CIFAR10和CIFAR100上那样进行过多的超参数搜索。无论如何,我们表明我们的模式仍然是好胜。与VIT相比,我们只需要四分之一的参数数量就能获得更高的精确度,并且复杂度更低(MAC)。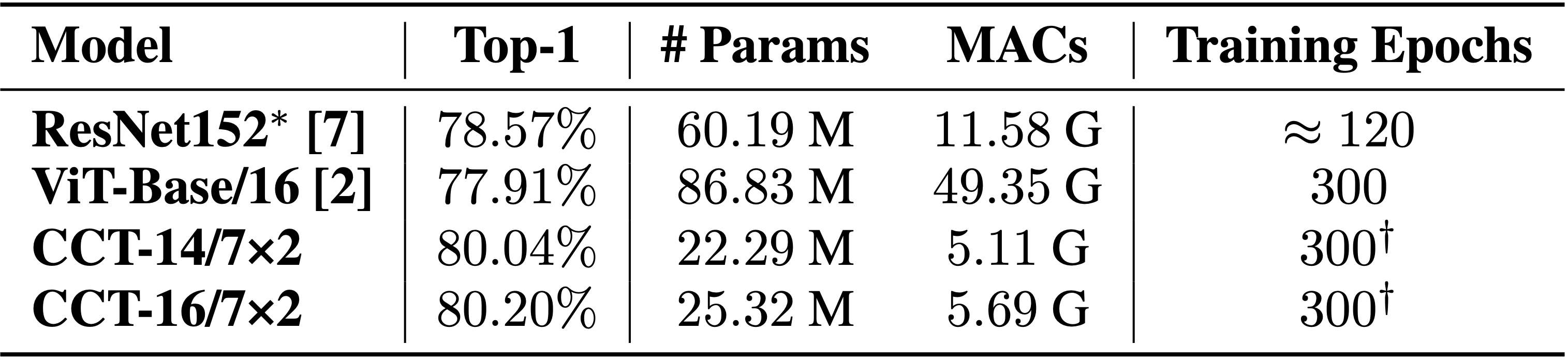
我们将注意到,VIT对大小为224×224的图像进行训练,并对大小为384×384的图像进行微调。在较小的图像上进行培训通常会更容易,因为您可以拥有较大的批次大小,这通常有助于加快培训速度并减少梯度爆炸。根据这篇论文,他们报告说,视觉转换器受益于更大的图像尺寸。如果VIT只报告大小为224×224的图像的结果,他们的模型将具有86.54M参数和16.84个GMAC。
但是等等,还有更多!:自然语言处理
我们也可以将这种类型的网络应用于自然语言处理,特别是文本分类。您可能想要使用这类东西进行垃圾邮件检测或情感分析。基本上,我们把自己限制在与我们的视觉任务类似的NLP任务中,即分类。 Sentiment Analysis
但我们必须在这里做出重大改变。单词是…嗯,文字而不是数字。在图像中,我们有由0到255范围内的数字定义的像素,并使用红色、绿色和蓝色的3个通道。所以我们可以用向量(255,0,0)来定义红色。但是我们怎么才能这样定义一个词呢?我们如何让计算机理解我们的输入呢?
最好的办法是使用预先训练好的单词,就像手套一样嵌入其中,但你也可以训练自己的单词。手套有70,000个单词,每个单词被嵌入到300个元素的单词向量中。所以这给了我们额外的2100万个参数!那几乎是我们最小型号的100倍!但是,如果它是预先培训的,那么除了存储大小之外,您就不必太担心了。但是也许你的词汇量有限,不想浪费所有的空间,不用再看了,我们支持你!我们实际上不需要做太多事情,因为PyTorch非常友好地为我们提供了一个嵌入函数。我们真正需要告诉它的是词汇表的大小(我们知道多少个单词)和嵌入维度。当然,较大的嵌入维度将使其更具表现力,但会占用更多空间,因此请尝试使用此选项来找到适合您的内容。300是一个典型的数字,所以从那里开始吧。 GloVe embedding function
因此,我们可以使用此函数来创建单词嵌入。在我们的网络中,我们会把嵌入的单词当作我们的图像补丁。从这个函数中,您还可以看到我们可以传入一些预先训练好的值,例如,如果我们使用手套中的那些值。我们可以通过关闭requesgrad函数来冻结我们的模型,这样它就不会学习。
因为我们改变了嵌入空间,所以我们需要改变一些东西。我们不再有补丁嵌入(很难接受补丁的单词!)因此,为了与NLP术语保持一致,我们将其称为标记器(Tokenizer)。格式略有不同,但在大部分情况下是相同的。不同的是,我们这里需要一维卷积。此外,我们还需要启用掩码,以防我们只想使用以前看到的单词。
在这之后,我们都准备好出发了!我们将使用手套在两个不同的数据集AG_News和TREC(您可以使用PyTorch TorchText分类数据集获得这两个数据集)上测试它。我们不会计算模型尺寸的手套参数,因为这是一个常数。如您所见,我们的模型也可以很好地作为文本分类器。 AG_News TREC torchtext classification datasets
结论
希望我们已经为你揭开了视觉变形金刚的神秘面纱,让你觉得你也可以建造这个强大的模型。由于“变形金刚”缺乏局部感应偏差,人们一直认为这些架构非常需要数据,因此也需要大量的计算。正如我们所展示的,您不需要大量的资源或数据来制作有效的模型,并且已经消除了“数据饥渴的转换器”的神话,甚至允许在CPU上进行培训!我们希望这项工作将帮助那些数据和资源有限的人也为变压器研究做出贡献,并鼓励每个人都参与到这些网络中来。通过这种方式,我们可以帮助人工智能研究民主化,特别是关于变形金刚的研究。
我们已经开放了论文中的代码,以允许任何人查看或修改源代码,以帮助验证我们的结果并鼓励实验。如果您想了解更多我们的工作,您可以查看俄勒冈大学的SHI实验室,或者查看我们的GitHub,了解更多开源作品。 the code paper SHI Lab GitHub
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/06/30/%e7%94%a8pytorch%e5%9c%a830%e5%88%86%e9%92%9f%e5%86%85%e4%bb%8e%e9%9b%b6%e5%bc%80%e5%a7%8b%e5%9f%b9%e8%ae%ad%e7%b4%a7%e5%87%91%e5%9e%8b%e5%8f%98%e5%8e%8b%e5%99%a8/
