
图像识别在过去的10年里达到了一个新的高度,这主要是因为CNN的发展及其在解决现实世界图像识别和定位任务中的应用。由于多年来的发展,研究人员和科学家正在做的工作是为了在以下方面取得接近人类的表现:
开发人员已经确定了不同的方法和AI/ML技术,以解决不同的图像识别场景。在我们的场景中,用例基于对象检测和图像推荐,图像推荐可以是任何基于计算机视觉的推荐系统的独立组件。下面是这样一个图像推荐系统的处理流程
选择了一个包含约180k个图像的图像目录进行推荐,并确定了总共22个服装类别以供培训。下面是目录图像的分布情况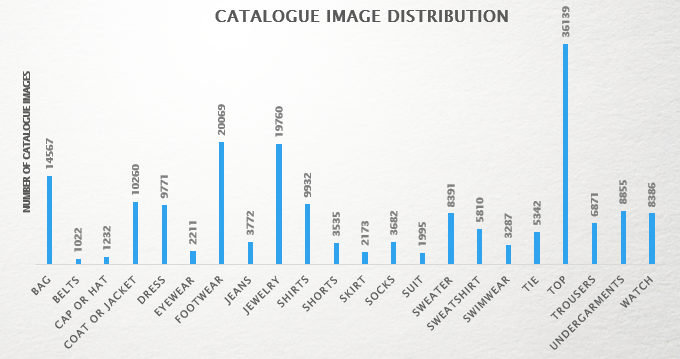
用于检测的YOLOv5
YOLO执行单级检测,为目标检测提供最先进的解决方案,并在推理时进行实时预测。有关YOLOv5的更多详细信息,请单击此处。如果你想了解更多关于YOLO的进化,你可以阅读这篇文章。here this
目录图像的YOLO检测:
在受约束的环境中采集目录图像,并对仅包含服装对象的图像进行裁剪。在这种情况下,在这样的图像上训练的任何模型都会受到真实图像中的可变性的影响。为了解决这样的问题,下面提到的两种技术很有帮助:
img = cv.imread(input_path+img_name)
y,x,_ = img.shape
gap = 5
rm = round(random.random())
padding_top = random.randint(int(0.1*y),int(0.5*y)+rm*2*y)
padding_bottom = random.randint(int(0.1*y),int(0.5*y)+rm*2*y)
padding_right = random.randint(int(0.1*x),int(0.5*x)+rm*2*x)
padding_left = random.randint(int(0.1*x),int(0.5*x)+rm*2*x)
image = cv.copyMakeBorder(img, padding_bottom, padding_top, padding_left, padding_right, cv.BORDER_CONSTANT)
height,width,_ = image.shape
w,h = x-2*gap,y-2*gap
x,y = padding_left+gap,padding_bottom+gap
x,y = int(x + w/2), int(y+h/2)
x,y,w,h = x/width, y/height, w/width,h/height
cv.imwrite(input_img_path+img_name,image)添加填充后,对象通常以不同的形状放置在的不同部分。然后在填充的图像上进行大小调整。还保存x、y、w、h坐标,以作为对象检测网络的参数。
准备YOLO格式数据集:
--data
--images
-- train
- image1.jpg
- image2.jpg
-- valid
- image11.jpg
- image22.jpg
--labels
-- train
- image1.txt
- image2.txt
-- valid
- image11.txt
- image22.txt
Example: for any file which is present in /images/train, filename should be same in /labels/train but the extension will be '.txt'训练YOLO时只需对结构稍作改动,以调整旋转、透视变换等增强参数。图像缩放至320×320像素大小,并使用YOLOv5中等大小模型训练40个历元。由于硬件限制,未使用大尺寸模型。
使用目录图像进行检测的挑战:
随机填充在一定程度上可以帮助模型学习相对于真实图像在图像位置和大小方面的可变性。然而,学习的检测模型在正确识别真实世界图像的包围盒方面仍然有很大的困难。主要原因是在不同的环境中拍摄的照片在背景和像素差异方面缺乏变化。
微调YOLO:
我们已经从Flickr、Reddit和其他流行的网站收集了大约5k个样本,并使用Makeense.ai对图片进行了标记。本网站提供下载YOLO易耗品格式注释的选择。手动收集图像背后的主要思想是在以下方面增加训练图像的可变性makesense.ai
更新的YOLOv5模型使用这张真实世界的图像进行了微调。在执行微调之后,还观察到了MAP的巨大跳跃(增加到0.78,而在之前的场景中只有0.42)。
下面是几个检测网络的例子

以下几个技巧有助于进一步提升性能:
对检测到的对象的推荐
到目前为止,我们构建并验证了一个检测网络,能够检测出包围盒,并为我们提供预测的服装类别。下一个任务是创建一个推荐网络,它将把我们带回目录图像,以便基于检测到的对象进行推荐。这里的几个假设包括:
在这个用例中,对象检测是我们验证是否可以使用裁剪的目录图像作为起点来构建高效的AI应用程序的主要关注点,该应用程序也可以在现实世界的图像上工作。为了构建推荐系统,我们没有使用YOLOv5作为功能描述符。取而代之的是,我们试验了一个独立的基于CNN的分类模型来构建一个单独的图像推荐组件。在这种情况下,我们使用VGG16网络构建了两个独立的分类器。这两个型号的功能是:
此类网络的代码片段可从此处参考:
class BotNet(nn.Module):
def __init__(self,n_classes=None):
super(BotNet, self).__init__()
self.model = models.vgg16(pretrained=True)
self.n_classes = n_classes
for param in self.model.parameters():
param.requires_grad = False
self.fc1 = nn.Linear(25088,2048)
self.fc2 = nn.Linear(2048,256)
self.fc3 = nn.Linear(256,self.n_classes)
self.relu = nn.ReLU()
self.logSoftMax = nn.LogSoftmax(dim=1)
def forward(self, x):
x = self.model.features(x)
x = x.view(x.shape[0], -1)
y = self.fc1(x)
y = self.relu(y)
x = self.fc2(y)
x = self.relu(x)
x = self.fc3(x)
out = self.logSoftMax(x)
return y,out一旦训练了类别分类模型,所有180k目录图像都通过了类别分类网络,并为每幅图像保存了2048维的特征向量。对于每个性别和类别组合,特征向量被保存在一个组中,以便在搜索排序最接近的图像时,我们可以只查找相关的一组特征。
import pickle
import time
start=time.time()
image_size = 224
transform = A.Compose([
A.Resize(image_size,image_size),
A.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
ToTensorV2()
])然后基于预测的性别和预测的类别进行推荐,然后查找正确的性别_类别级别特征集。
#define euclidiean distance and find n closest matches
def euclidean(p1,p2):
p1,p2 = p1.cuda(),p2.cuda()
dist =torch.dist(p1,p2)
return dist这极大地缩短了推理过程中的响应时间。然而,这也伴随着错误推荐的代价,因为对服装类别或性别的错误分类。造成误分类的主要原因是模型的能力有限以及星表图像WRT真实世界图像背景的多变性。
改进范围:
改进的范围分为两个主要部分。它们如下所述:
模型性能改进:
应用程序性能提升:
结论:
实验表明,YOLO在执行最先进的物体检测方面是有效的。通过适当的架构和代码设计,该应用程序只能用于实时推荐。我们可以将这样的应用程序与任何聊天机器人或基于网络摄像头的应用程序集成在一起。
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/02/%e7%9b%ae%e5%bd%95%e4%b8%8e%e7%8e%b0%e5%ae%9e%e4%b8%96%e7%95%8c%e7%9b%b8%e9%81%87%e7%9a%84%e6%a3%80%e6%b5%8b%e4%b8%8e%e6%8e%a8%e8%8d%90%e2%80%8a-%e2%80%8a-2/
