

在根除糖尿病,我们每天处理1200到1500份血液报告。我们的营养师需要大约10分钟的时间来读取每份报告,并将血液标记值手动更新到数据库中。这相当于每天浪费200-300个小时,每年浪费100,000个小时。加上手动读取和更新到数据库,错误率为15-20%。
使命宣言旨在解决具体的挑战。
- 阅读文本&从手写图像中提取信息&由于笔迹的多样性,手写文本很难从一个人读到另一个人。
- 读取不同格式(pdf、各种图像格式)的文本,如血液报告值、处方数据。
- 如何以精确的格式随时提供给用户。
因此,我们试图探索上述挑战的解决方案,
- 通过应用计算机视觉技术从报告、手写信息中读取和提取文本。
- 由于提供了许多解决方案,我们尝试利用Amazon提供的AWS TExtract服务。
让我们来了解一下,TExtract是什么?
- AWS TExtract是亚马逊提供的一项服务,它将帮助我们从扫描的文档和手写图像中自动提取文本。
- Amazon TExtract提供了仅检测文本的服务和分析发现更广泛关系(如表单数据和表格)的文本的操作。
- 在当今世界,许多公司都在处理从pdf文档、表格格式和手写信息中提取数据的问题。这项服务将有助于获得相当好的自动读取和提取信息的结果。
关于从图像中读取文本的TExtract实现的思考。
Amazon TExtract检测和分析文档中的文本,并将其转换为机器可读的文本格式。这是Amazon TExtract的API参考文档。
关于Boto3库:Python(Boto3)用于创建、配置和管理AWS服务,如Amazon Elastic Compute Cloud(Amazon EC2)和Amazon Simple Storage Service(Amazon S3)。SDK提供面向对象的API以及对AWS服务的低级别访问。
要使用AWS TExtract服务,请遵循以下实施流程:
!pip install boto3 #install required service.
import boto3 #AWS SDK for python
client = boto3.client('textract') #create client & client representing
amazon textract.
import boto3.session #Boto3 acts as a proxy for the default session & created automatically when we create a client for the session.
my_session = boto3.session.Session()
#Environment Variables for below to create successful connection to AWS, aws_access_key_id, aws_secret_access_key, & region_name.
Another way to create session,
client=boto3.client('textract',aws_access_key_id="",aws_secret_access_key=" ",region_name=" ")
#In the above code it will create session giving access to key values by initializing textract.
documentName =(r"C:/Users//Desktop/project/Example.jpg") #mention path of the document stored in your system.
with open(documentName, 'rb') as document:
imageBytes = bytearray(document.read()) #read documents by using python file i/o functions and mention read mode.
response = client.detect_document_text(Document={'Bytes':imageBytes})下面拍摄的一些图像将用于文本提取。
让我们了解Analyze Document方法在文本提取过程中有何帮助。要分析文档中的文本,请使用Analyze Document方法并将文档文件作为输入传递。
1.Analyze Document返回一个JSON结构,该结构在表单数据(键-值对)中包含分析的文本。
2.关联数据通过两个挡路对象返回,每个对象类型为KEY_VALUE_SET:Block
一个关键的挡路对象和一个有价值的挡路对象。
3.表挡路对象包含检测到的表的相关数据。
将为表中的每个单元格返回一个单元格挡路对象。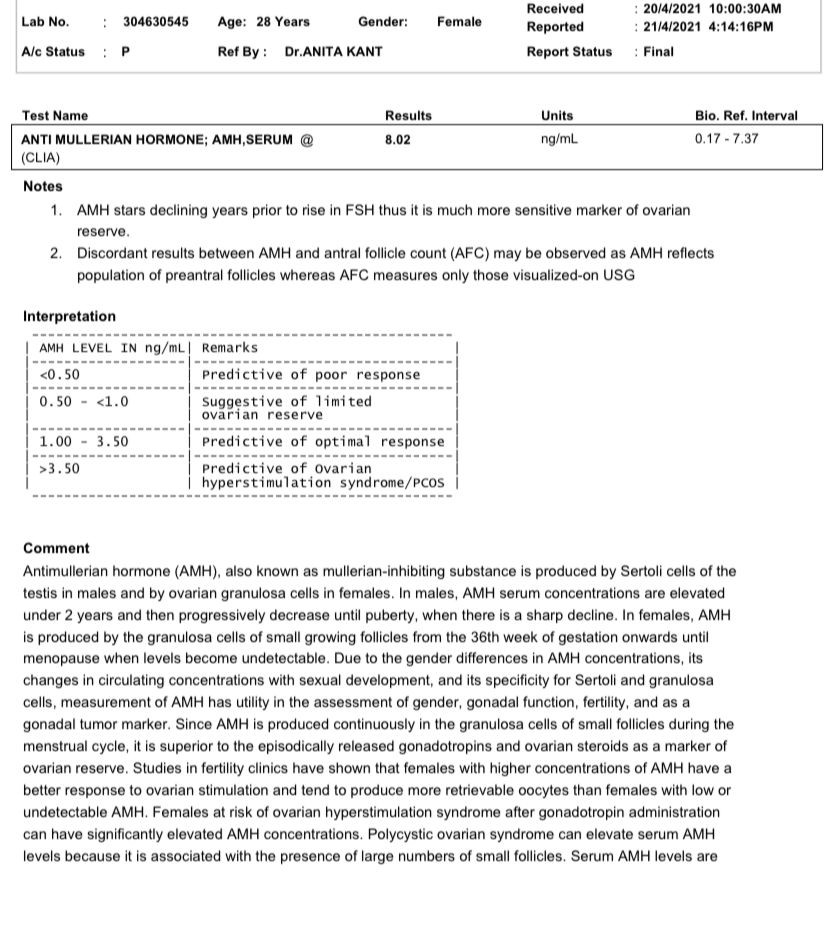
我们可以通过指定特征样本列表来确定要执行的分析原型。因此,我们可以很容易地从提供的图像和文档中提取文本,并且只需使用很少的tExtract操作,就可以阅读以表格格式提供的文本。
我相信这些细节将有助于理解从存在于各种格式的众多文档中提取文本。
祝您学习愉快!
参考文献:
这篇文章最初发表在2021年6月13日的https://www.numpyninja.com上。https://www.numpyninja.com
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/02/%e4%bd%bf%e7%94%a8aws-t-extract%e5%af%b9%e6%89%8b%e5%86%99%e5%9b%be%e5%83%8f%e8%bf%9b%e8%a1%8c%e6%96%87%e6%9c%ac%e6%8f%90%e5%8f%96%ef%bc%9a%e6%a0%b9%e9%99%a4%e7%b3%96%e5%b0%bf%e7%97%85%e3%80%82/
