
“不管怎么说,盒子是愚蠢的,我可能是面具的忠实信徒,除非我不能让YOLO学会它们。”J·雷德蒙
当我在“YOLOv3:一个增量改进”的论文中读到这些话时,我想,对于像包围盒这样的常见结构来说,这样说可能太尖锐了。有什么问题吗?事实上,创建对象检测和实例分割模型是为了解决不同的任务,不是吗?是的,但在一定程度上是这样。它们的目标都是定位某个对象,但精确度不同。分段蒙版的目的是捕捉对象的形状,而不考虑其复杂性。边界框要简单得多。为了扩大“愚蠢”这个词的含义,我想说边界框并不能告诉我们物体的形状、实际占用的面积,而且边界框常常捕捉到太多的背景噪音。
有时候,对于计算机视觉解决方案来说,这可能是件大事。如果某个对象的裁剪图像随后由管道中的另一个模型使用,则边界框的上述缺陷可能会显著影响性能。另一方面,目标检测网络经常用于边缘设备上,以达到实时处理的目的。在边缘环境中运行复杂的逐像素分割神经网络成为一项艰巨的任务。这里我们面临的问题是:我们希望提取的不仅仅是一个简单的矩形,但是能够做到这一点的模型需要不可承受的计算资源。了解了所有这些,问题的表述如下:我们能否以某种方式扩展目标检测,使其能够以分割级别的精度找到目标,同时保持轻量级目标检测网络的所有实时性能优势?
让我们考虑一下。多边形形状可以很好地替代边界框。但是,多边形组件的数量是不同的,它取决于形状的复杂性。因此,多边形不能是具有固定输出维数的神经网络的直接输出。在我看来,解决深度学习中的多边形预测问题有很多研究方向。这些模型的实际应用实际上取决于项目的具体情况。我想强调一下我最近遇到的一种方法–PolarMask。在我们深入到细节之前,我想回顾一下PolarMask所基于的极轴表示的一些基础知识。该点由角度和距离表示,而不是x和y绝对值。PolarMask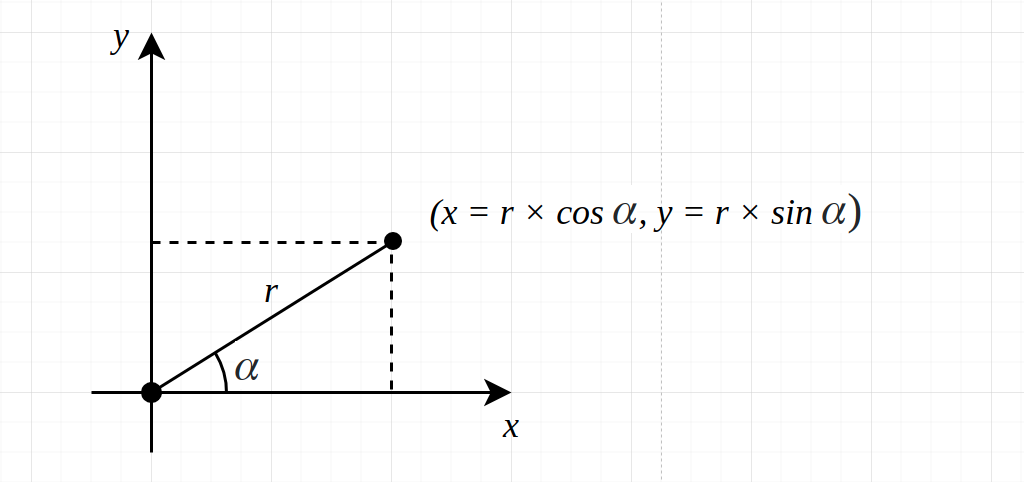
这里是PolarMask的想法:让我们找到一个对象的中心,并以一定的间隔投射一组光线(例如,10度,总共360/10=36条光线)。光线与对象轮廓相交的点是目标多边形的点。这类点的数量是固定的,因为角度是预定义的。模型唯一需要预测的是距原点(中心)的距离。基本上,这里以相当精确的方式解决了不同数量的多边形组件的问题。现在,我们可以将目标数据从未定义的不同维度转换为简单而统一的数据。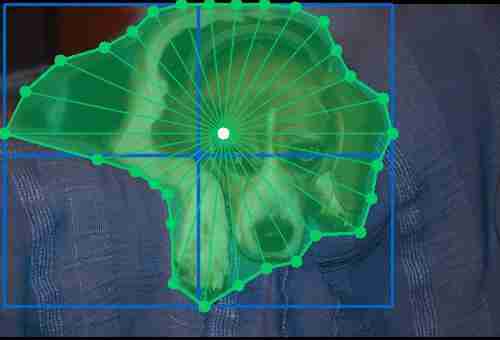
算法工作所缺少的另一条信息是对象的中心,这也是模型输出中所期望的。基本上,这只是两个值的回归。然而,这里的棘手之处在于我们究竟以哪个点为中心。关键是中间坐标不是自由形式对象的最佳选择。还是把“质心”作为一个真实点比较好。所有光线到达其最佳交点的概率更高。
因此,每个对象的模型输出是角度栅格的中心坐标和距离矢量。
为什么我个人觉得上述想法很有趣:
- 从推断时间的角度来看,它几乎与包围盒回归相同,只是我们有更多的值需要回归。此外,边界框可视为具有4个元素的多边形的特例。换句话说,我们几乎免费地得到了更复杂、更笼统的预测。
- 多边形的极坐标表示可以应用于多种神经网络结构,因为它只是建立模型输出的一种灵活方式。例如,可以修改YOLO或FCOS等众所周知的对象检测体系结构,以产生对象多边形而不是边界框,而不需要太大的工作量。
- 它给出了一种介于目标检测和实例分割之间的输出结构。因此,它可以是一种折衷的解决方案,不需要显著改变每像素分割的整个流水线。
- 看到实用的解决方案出现在深度学习中是一件很酷的事情,深度学习充斥着理论讨论和基准争斗。当工程学头脑有了这样的想法,并将人类不同的知识片段连接成一个有用的、有效的解决方案时,这真的是令人兴奋的。
在下一篇文章中,我将讲述我自己使用此方法进行的实验。没有什么真正具有开创性的东西,但我想检查一下从头开始实现这样的多边形回归有多容易。让我们保持联系。
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/02/%e5%9f%ba%e4%ba%8e%e6%9e%81%e5%9d%90%e6%a0%87%e7%9a%84%e7%9b%ae%e6%a0%87%e5%ae%9a%e4%bd%8d-%e5%88%86%e5%89%b2/
