

免责声明:如果机器学习模型的准确性不是您的优先事项,那么本文可能不适合您。致我的机器学习工程师、数据科学家、计算机视觉工程师和产品经理:欢迎回家。拿一杯咖啡,让?™‘s开始吧。
对于大多数计算机视觉用例,最初的模型开发相当快速且相对简单。在短时间内,您可以开发一个足以进行概念验证的基本机器学习(ML)模型。
要做到这一点,只需找到一个开源数据集,花一些时间进行标记并使用迁移学习。在任何时间内,瞧:你有了一个基本的模型。
当然,这种模型不会有足够高的精确度或置信度来交付任何业务价值。只有当您想要提高模型的准确性和可信度时,开发才会变得更加昂贵和日益复杂。
这是因为ML模型的学习速度停滞不前-欧元越远,这就是长尾的诅咒。
在我的上一篇文章中,我们讨论了大海捞针问题。我们探索了这个问题如何与ML相关,以及为什么它是对真实数据挑战的过度简单化。如果您还没有™,您可以在这里查看帖子。In my last article check out the post here
在本文中,我们将探讨为什么在开发自治系统和ML远景模型时数据挑战很重要,以及为什么ML团队需要在他们的工具箱中提供数据解决方案。
早在2019年,当我在一家顶尖的自动驾驶汽车公司工作时,自动驾驶系统开发的挑战对我来说变得格外明显。我很快意识到,™最重要的就是找到正确的数据。
到目前为止,数据是向我们的ML模型提供准确性改进的最大障碍。从我们现有的数据集中发现高质量数据的能力是从实验室到道路,最后到经销商所需要的。
模型准确性的主要挑战在于数据。在商业应用中,我们看到机器学习模型的主干通常是相当标准的,通常不是问题的根源。
提供高质量的数据是一个迭代的过程。在完成与自动驾驶汽车团队的工作后,我意识到这个数据发现过程不仅仅是制造自动驾驶汽车所需要的,基本上所有的自动驾驶系统和ML计算机视觉应用程序都面临着这个数据挑战。考虑到这一点,我和我的团队决定将重点从咨询转移到组建一家产品公司,唯一的目的就是解决这个问题。
许多公司在改进ML模型时面临着回报递减的问题,特别是当准确率从80%提高到>95%时。为了提高模型精度,您通常需要先经过一条长尾的改进。这种长尾减慢了增量模型精度的提高,并因此减慢了产品上市时间。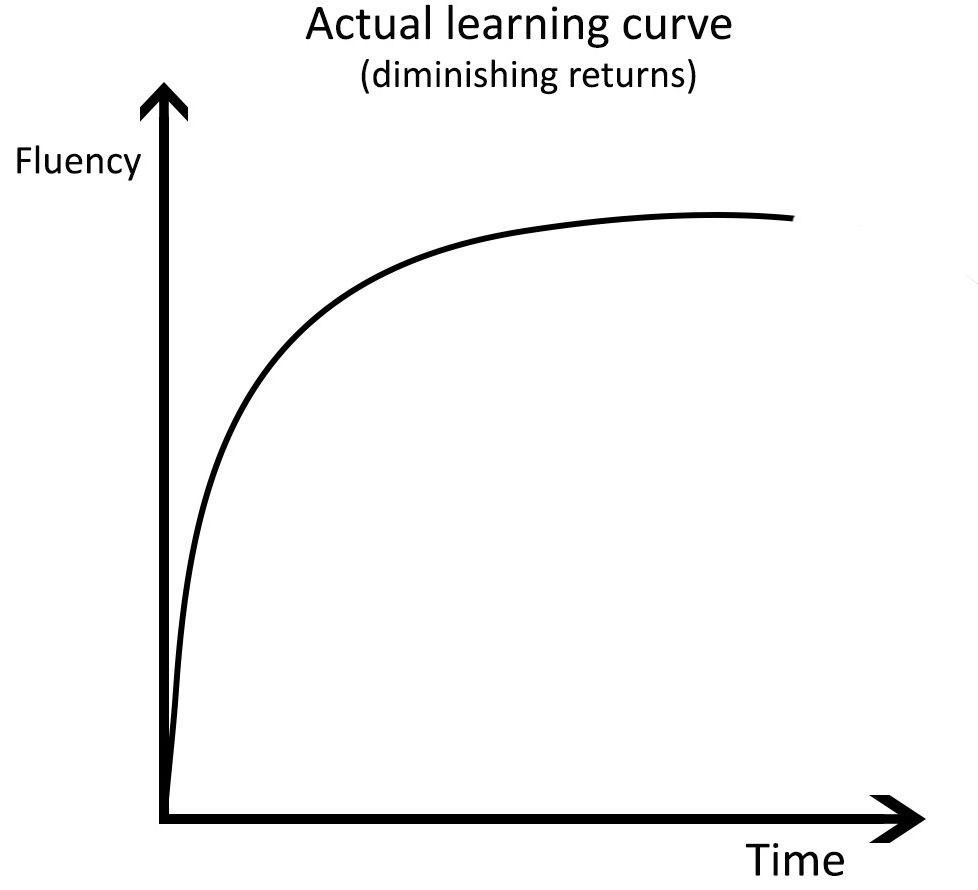
人类的学习中也出现了长尾现象。上图是一条语言学习曲线。看起来眼熟吗?
想象一下,你决定搬到西班牙,在一家咖啡馆工作,学习西班牙语。有了同事的一些基本知识和培训,您很快就能接受简单、常见的点餐,如Cafao©或Cerveza。然而,如果有人带着一个不寻常的或定制的订单来找你,比方说要一份tostada contomate,aceite,y jam ao³n,你可能很难产生他们想要的结果。
在ML中,我们将这些不同寻常的订单称为EUROURE˜EDGE CASES AND EURO™,不幸的是,它们似乎有无限的数量。
比方说,在80%的时间里,人们会下简单的订单。这意味着80%的时间我们可以完成他们的订单,而20%的时间我们的语言培训(我们的培训数据)无法满足我们的要求。
通常在ML开发中,一旦您的模型准确率达到约70%“80%”,大多数容易完成的任务(咖啡、啤酒等的订单)已经学会了。
从这里开始,您可以通过识别模型的这些边缘情况/故障模式来改进模型,然后找到其他类似的实例来训练您的模型。
说得容易,做得难。
棘手的部分是查找和修复这些导致模型失败的边缘情况。这些是你们草堆里的针。
地面真实值标签中的错误也可能导致模型失败。这就是为什么你要向西班牙专家学习,而不是向同样在学习这门语言的美国同事学习。
查看上面的ML开发曲线,基本事实中的错误通常会出现在开发的长尾部分。
找出基本事实中的错误是很困难的,这通常是通过基于共识的质量控制检查,或通过手动的、批判性的基本事实审查来完成的。
如果您的用例优先考虑模型准确性,那么在某些情况下,您将需要一个可扩展的平台来可视化和管理您的数据。最终,特别是如果您正在构建任务关键型自治系统,您需要升级您的ML数据操作。
通过使用预先建立的生产级ML DataOps平台,您将能够消除最初3个“6个月”的构建时间,这会降低ML开发的速度。如果您可以使用需要24个多月构建的高级平台,具有比基本内部解决方案能够提供的更高级的功能和更好的集成,为什么还要构建呢?
回到我们的长尾,这3?欧元“6个月的初始构建时间阻碍了您开始迭代您的任务关键型ML项目。为了开始迭代,您首先需要一个数据操作解决方案。
一旦开始迭代,您的项目就有几个组件需要查看,特别是模型:
为了保持本文的简洁性,我们将重点介绍第三个组件,即查看模型中的数据差距。也就是说,查找模型中缺少的数据,在现有数据中查找该数据,然后将其插入到模型中。
检查和测试您的模型需要您找到并定义这个数据鸿沟,即针的样子。在每次迭代中,这都需要一些时间。然后,实际收集或查找符合此标准的数据也需要大量时间。the needle
当接近模型精度的上限时,曾经需要5周才能提高5%的模型性能开始需要5个月。
例如,您决定要建立一个使用历史卫星图像预测中国年度小麦收成健康状况的模型。
你的前2周和1,000张带标签的图片会给你带来令人印象深刻的60%的模型性能提升–“欧元”,从0%提高到60%。
接下来的2周和1000张带标签的图片将模型从60%-80%(欧元)改进到现在只有20%的跳跃。
然后,同样的努力将模型从80%提高到85%,跃升了5%。
而且越来越平坦。
您的下一次迭代可能会产生2%到87%的增长。
你走得越远,它就变得越难。
使用与不使用专用ML DataOps平台的迭代的简化示例。
使用现有的生产级平台,您不仅可以跳过初始构建时间和无限的维护和改进,而且上面概述的迭代模型改进过程从几周持续到几天。
使用此工具,您可以更有效地查找模型的故障模式、找到正确的数据、处理数据的标签,并确保标签的质量。
以这种方式使用正确的工具集,您可以通过以下三种方式更快地达到所需的精度:
许多处于计算机视觉模型开发前沿的大公司出于需要,已经为ML构建了DataOps平台。你可以在这里和这里了解更多关于他们的发展。here here
在过去的两年里,我们口径数据实验室一直在努力解决上述挑战,并构建了一个最高水平的平台来撞击解决这些数据问题。我们的平台SceneBox是当今市场上最全面的感知数据操作工具。Caliber Data Labs SceneBox
我们的愿景是为各种规模的组织提供现成的相同口径的工具,这样他们就可以以相同的速度发展,而不会在AI/ML竞赛中掉队。我们的目标是降低组织扩展其计算机视觉开发的进入门槛。您可以将生产级系统与我们的旗舰产品SceneBox配合使用,而不必在内部处理这些数据操作工具集。SceneBox
如果您有兴趣了解更多信息并想安排演示,您可以在这里注册或通过hello@Caliberdatalab.ai联系我们。sign up here hello@caliberdatalabs.ai
我很想听听您对这篇文章的看法。我们的团队总是乐于对话。如果你想和我一起深入研究,请在LinkedIn上联系我。LinkedIn
请继续关注本系列的下一期:平台的智能。
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/03/%e9%95%bf%e5%b0%be%e5%b7%b4%e7%9a%84%e6%95%85%e4%ba%8b/
