
这篇文章是关于我们最近发表的关于领域泛化的CVPR 2021口头论文。众所周知,领域漂移是指训练数据和测试数据在分布上存在显著差异。这导致仅在训练或源数据上训练的机器学习模型在测试或目标数据上表现不佳。处理这个问题的一种天真的方法是用新数据微调模型,这通常是不可行的,因为很难为每个新的目标域获取标记数据。一类域自适应(DA)方法通过利用(未标记的)目标数据来最小化域漂移来解决这一问题,但是当未标记的目标数据不可用时,它们不能使用。CVPR 2021 Oral paper
另一方面,领域泛化(DG)从以下角度来看待问题:如何使在单个或多个源域上训练的模型在完全不可见的目标域上泛化。这些方法通过(I)使用诸如对抗性学习的方法来学习对于数据域不变的特征表示,(Ii)在通过元学习方法学习的同时模拟域转移,以及(Iii)用来自虚拟目标域的合成数据来扩充源数据集来做到这一点。这些方法已被证明是处理畴移位问题的有效方法。然而,除了单纯的分类之外,现有的大多数方法都没有利用推理时可用的目标分布的测试样本。另一方面,当人类遇到一个看不见的物体时,通常会把它与之前感知到的相似物体联系起来。
基于这一直觉,本文对分布式电源问题的解决做出了以下贡献:
(A)给定来自多个源分布的样本,我们建议学习源域不变表示,该表示也保持类别标签。
(B)我们建议在分类前将目标样本“投影”到源数据特征的流形上,通过对生成模型(在训练中学习)的输入进行推理时间标签保存的优化过程,该生成模型将任意分布(正态)映射到源-特征流形上。
(C)我们通过广泛的实验证明,我们的方法在标准DG任务上取得了新的最先进的性能,同时在鲁棒性和数据效率方面也优于其他方法。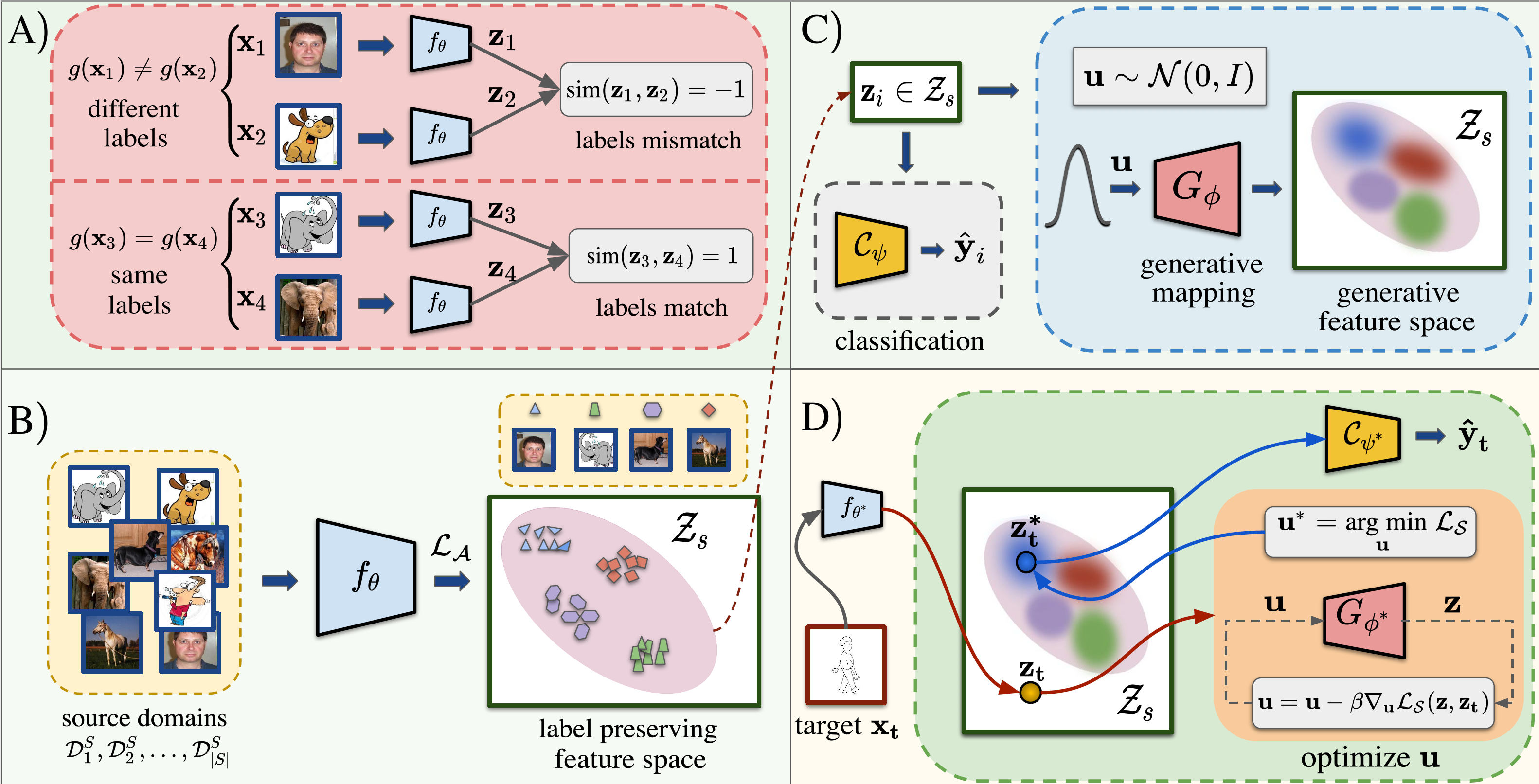
如图1所示,A)我们从设计函数f(神经网络f\θ)开始,以学习标签保持度量,该度量在一对图像之间的基本事实标签(由函数g给出)匹配时产生相似性分数1,否则产生-1。函数‘sim’指的是余弦相似函数。b)f使用神经网络f\θ来实现。在训练过程中,利用来自源域的示例使用损失L_A来创建源流形Z_S,使得流形上的特征被隐式聚类以保持示例的标签。c)在流形Z_s的保标特征上训练分类器C_\psi和生成模型G_\φ,使得G_\φ学习将高斯向量‘u’映射到流形Z_s上的一点。d)在推理过程中,f_\θ*将目标x_t投影到保标特征空间上的点z_t。我们提出了一种推理时间过程,将目标特征投影到源流形上的一个点zt*,最后对源流形进行分类,以预测其标签HAT{y}t。
感兴趣的读者可以观看YouTube视频,以获得清晰的内容。
我们方法的动机来自以下观察:学习领域不变表示的DG方法只使用源数据。因此,不能保证在这种表示上训练的分类器对源数据流形之外的目标数据执行得很好。因此,如果将目标样本投影到源特征的流形上,使得在分类之前保留地面真实标签,则可以改善目标数据的性能。为此,我们提出了一个由三部分组成的域泛化过程:
1.使用源数据学习保持标签的区域不变表示。我们首先将来自多个源域的数据转换到一个空间中,在那里它们根据类别标签进行聚类,而与域无关,并在这些特征上构建分类器。通过在源数据上构建生成模型,学习如何从源数据创建的领域不变特征流形生成特征。
3.给定测试目标样本,以保留标签的方式将其投影到源特征流形上。这是通过在前述产生式模型的输入空间上解决推理时间优化问题来实现的。最后,对投影的目标特征进行分类。

图2描述了学习f、G(生成模型)和分类器C的训练过程,而图3示出了所提出的用于投影目标数据点的推理时间优化方法。
综上所述,我们提出了一种新颖的领域泛化技术,该技术利用源域来学习领域不变的标签保持度量空间。在推理过程中,每个目标样本都被投影到这个空间上,这样对源特征训练的分类器就可以很好地对投影的目标样本进行泛化。我们已经证明了该方法在多源、单源和健壮的域泛化设置上产生了SOTA结果。此外,该方法的数据效率使其适合在低资源环境下很好地工作。未来的迭代工作可能会尝试将这种方法扩展到领域泛化,用于分割和零镜头学习。
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/05/%e5%9f%ba%e4%ba%8e%e6%8e%a8%e7%90%86%e6%97%b6%e9%97%b4%e4%bf%9d%e6%a0%87%e7%9b%ae%e6%a0%87%e6%8a%95%e5%bd%b1%e7%9a%84%e4%b8%8d%e5%8f%af%e8%a7%81%e5%8c%ba%e5%9f%9f%e6%b3%9b%e5%8c%96-2/
