
-Abhishek Madaan,Neha Rana,Pallab ChakrabortyAbhishek Madaan Neha Rana Pallab Chakraborty
引言
在这个项目中,我们展示了四个模型,一个是没有任何注意机制的,另一个是分别受到Bahadanau的注意和展示、出席和讲述的软注意的启发而具有注意机制的。
图像字幕是一种用人类语言生成图像的简短文本描述的技术。它要求模型识别图像的内容,了解每个对象的上下文和关系,并提供语义上准确的描述。这对传统技术来说是一个严峻的挑战,因为它需要强大的逼近能力。随着技术的进步和深度神经网络技术的快速发展,最近的工作表明在生成更自然的描述方面有了显着的改进。
传统上,编码器-解码器体系结构用于图像字幕任务。编码器通常是卷积神经网络(CNN),而解码器通常是递归神经网络(RNN)。图像字幕涉及机器学习中被广泛划分的两个领域,即CV和NLP。随着大规模图像分类数据集的出现,这一主题的研究激增,而随着人们的关注,系统只得到了改进。注意力可以让突出的特征显现出来,解码器可以更好地将图像的这些特征翻译成自然语言。我们展示了4个不同的模型,一个没有注意,另一个有注意机制的撞击图片字幕。在Flickr8k数据集上,使用复杂的图像编码器和有注意的解码器可以获得良好的结果。
数据集和评估指标
我们提出的图像字幕模型在Flickr8k数据集上进行了评估。该数据集包含8091张图像。这些图像中的大多数描绘了人类正在进行各种活动。每张图片都配上了5个描述的字幕。我们使用了不同的度量标准,包括BLEU、流星、胭脂、苹果酒和香料,来评估所提出的模型,并将其与其他基线进行比较。所有指标都使用公开发布的代码进行计算。
基线A
对于第一个基线,我们实现了以下步骤。首先,我们在每个字幕的开头和结尾添加了“startonee”和“endonee”。然后对字幕进行预处理,改善文本数据的结构。在此阶段执行几个步骤,例如转换为小写、删除标点符号和包含数字的单词。对于嵌入层,我们使用了手套42B300d预先训练的单词嵌入。使用预先训练好的Network InceptionV3从图像中提取2048个长度特征。每个字幕都被处理成令牌,并与图像一起输入网络,以预测字幕中的下一个单词。
基线B
对于第二个基线,我们使用InceptionV3模型提取图像特征,该模型以Imagenet权重作为初始化。“开始”和“结束”被附加在每个标题的开头和结尾。然后使用NLTK库对字幕进行标记化,以供进一步使用。填充是为了使最长字幕的字幕长度标准化。评估使用的训练和测试的比例是80:20。巴达诺的注意力在这条基线上被用来关注图像中的显著对象,这一点的灵感来自于论文“展示,出席和讲述”(Show,Add and Tell)。对于编码器,使用了CNN和RELU层。此外,与基线A不同的是,我们在解码器组件中使用了LSTM,而基线B中使用了门控循环单元。基线B的实现改编自TensorFlow的网站。Show, Attend and Tell
基线A和B的结果
最终型号A和B
对于最终的评估,我们提出了两个基于注意力的模型,分别受到Show、Advised和Tell的启发。模型A使用Madgrad优化器和ResNet152模块,而模型B使用带有VGG16模块的Madgrad优化器。模型B生成的字幕示例:
最终模型的架构: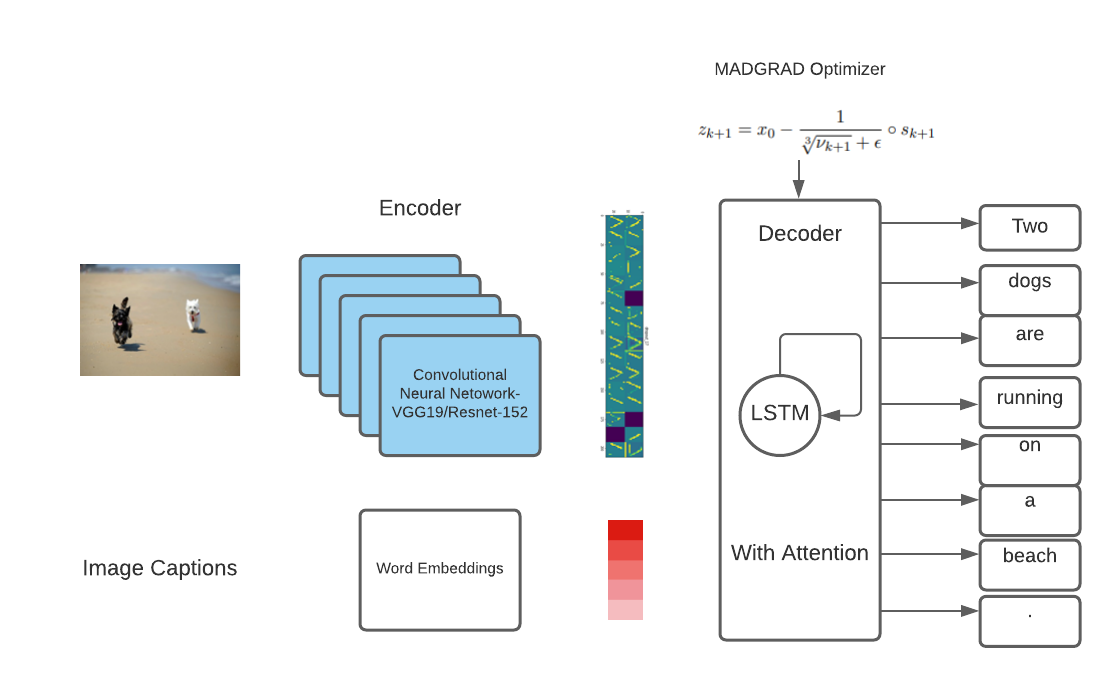
使用模型A(Madgrad优化器和ResNet152模块和软关注)和B(Madgrad优化器和VGG16模块和软关注)获得的结果可以在下表中看到。
以下是最终模型B(带有VGG16模块和软注意的Madgrad优化器)和基线B(Bahadanu注意)的一些结果: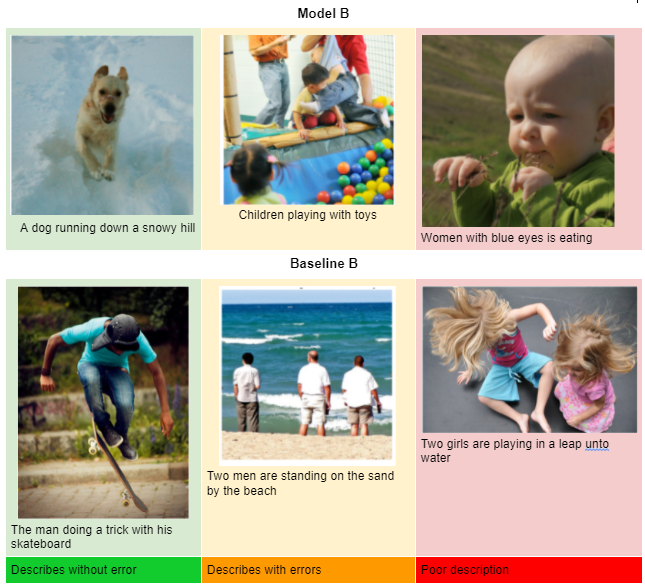

我们可以在下面看到一些最终模型B的注意力可视化示例:

参考文献
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/05/%e4%bd%bf%e7%94%a8%e5%9f%ba%e4%ba%8e%e6%b3%a8%e6%84%8f%e5%8a%9b%e7%9a%84%e6%a8%a1%e5%9e%8b%e7%9a%84%e5%9b%be%e5%83%8f%e5%ad%97%e5%b9%95/
