
上下文
使用最广泛、最古老的物种识别技术之一是œ形态学识别技术,也就是通过解剖学特征识别个体的�。然而,这种技术的缺点是不总是准确的,因为它依赖于观察和执行者的识别协议。
这种识别技术的替代方案可以是计算机视觉算法。这些算法让我们可以快速准确地识别图像的特征,因此只能通过照片来识别物种,使其更便携。
在下文中,我们试图借助计算机视觉来识别不同的蘑菇图像。这项工作与DataScience数据科学家课程的期末项目相对应。DataScientest data scientist course
项目作者:Karina Castillo和Cyril Vandenberghe。
该项目
数据源
在这个项目中,我们使用了来自http://mushroomobserver.org,的数据,这是一个专门收集和识别蘑菇图像的网站:用户上传图像,社区识别它们。目前,它的注册用户超过1万人。http://mushroomobserver.org
在我们最初的书目研究中,我们发现Github上之前的一个项目“蘑菇观察者-数据集”已经在这个网站上进行了探索,创建了一个从2006年到2016年的图像数据集。此外,12个JSON文件包含有关每个图像的附加信息。mushroomobser-dataset
数据探索
处理数据的第一步是创建一个数据框,其中包含有关蘑菇的图像和分类的信息。在生物学中,分类是一种基于共同特征定义层次组的方式,如下图所示:
在表1中,“排名”列表示在我们的数据框中蘑菇标识达到的最后一个分类级别。因此,如果条目在`rank`列中具有值`KINGDOM`,则`label`列值将是最一般的标识,例如,`Fungi.因此所标识的图像可以属于任何蘑菇。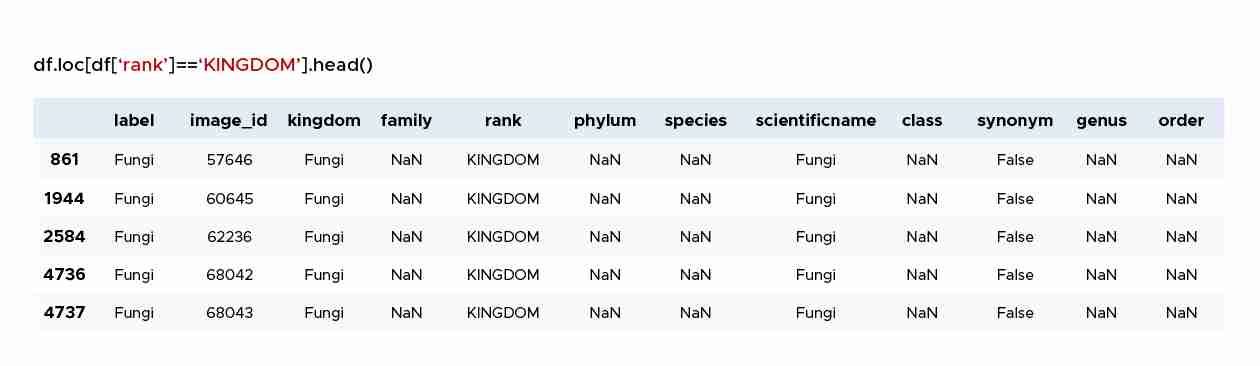
相反,如果“rank`”列是“SPECIES`”(更具体的分类单元),我们就有更详细的图像描述(表2)。
因此,`rank`列中有`KINGDOM`、`PHYLUM`、`CLASS`和`ORDER`值的图片会被丢弃,因为它们太笼统,信息量也不大。对于项目的睡觉,我们将只使用属于分类单元种、属、科的数据,如下图所示: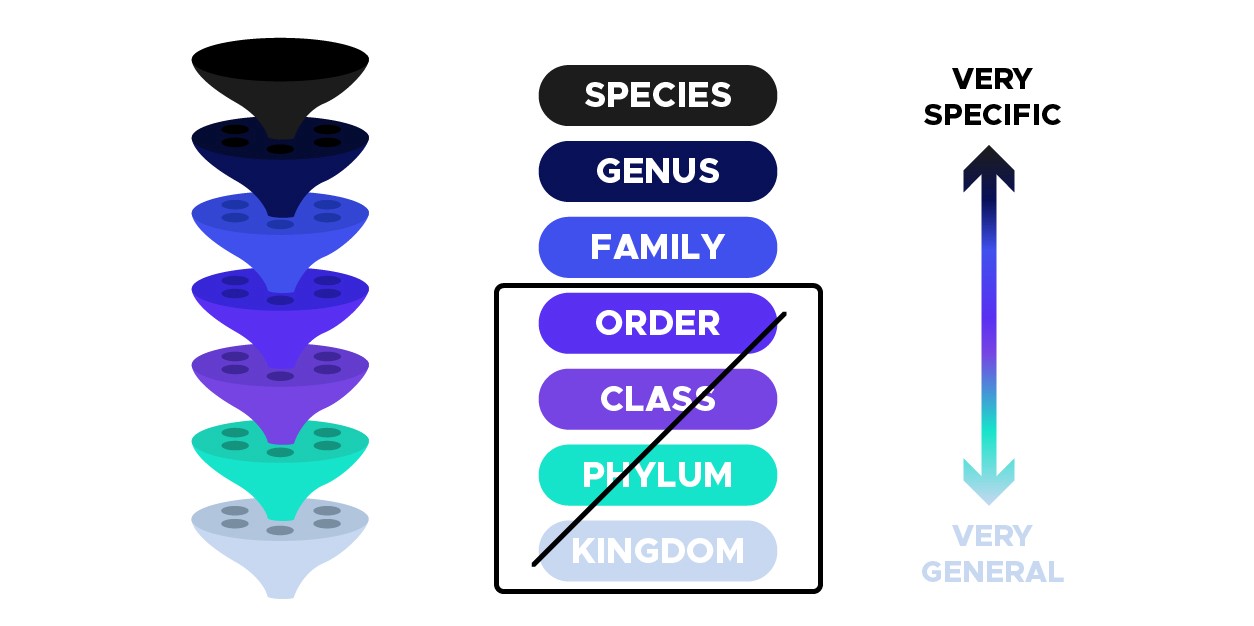
数据可视化
拥有大量的图像是成功开发计算机视觉项目的关键。在这个项目中,我们需要标签(即`label`列中的值)来为每个分类单元提供大量的图像来表示它。
下图(图2)4)是分类群中图像数量分布的可视化。四个面板中的每一个都显示由1到10个图像、11到100个图像、101到1000个图像和1000多个图像表示的给定分类单元(x轴)的标签数量(y轴)。
物种分类单元是最具特异性的分类单元,是理想的分类单元。然而,仅由1至10个图像表示的标签数量相当于物种总数的75%。在区间[101âuro“1000]内,只有7个物种的图像超过500张,只有一个物种的图像超过1000张。
相比之下,在包含1000多张图像的类别面板中,我们观察到属和科的分类群各有大约40个标签,这使它们成为很好的目标。从分类学上讲,家族是最不具体的级别,所以如果我们选择这个级别,我们会期望图像中有更多的异质性。那么,使用属似乎是分类学水平和可用图像数量之间的一个很好的折衷。
最终数据集:属类群
下面的条形图显示了41个选定属的图像数量(图5)。我们决定将自己限制在包含约1,000张图像的15个突出显示的属中,以减少计算时间并避免有偏见的表示。这样,我们总共有18,412张图像可用于我们项目的分类/建模部分。
基于神经网络的分类方法
建筑设计
正如前面提到的,这个项目的目标是识别蘑菇图像,这是一个典型的图像分类问题,通常通过深度学习方法来解决。为了实现我们的目标,我们测试了三个模型,详细说明如下。
- 乐网
首先,我们在具有LeNet架构(Y.LeCun等人,1998)的CNN模型上测试我们的数据,该模型包含适合图像处理的层。我们用两层卷积层测试了这个模型。
在0.98%的准确率值下,基本模型似乎不适合我们的目标,所以我们没有进一步追求这个模型。
- VGG16
接下来,我们使用了VGG16模型(Simonyan和Zisserman,2015),这是一种采用迁移学习方法的图像分类模型。
在第一步中,我们的模型有一个具有序贯模型的分类层,两个神经层(密集)和两个正则化层(Dropout)。
结果令人振奋,准确率约为70%,但模型存在过度拟合的问题。为了解决这个问题,我们添加了一层致密层并增加了Dropout值。图6显示了模型的最终架构。
此外,我们使用了来自KERAS包的EarlyStopping和ReduceLROnPlatform回调,耐心值分别为5和3。这样,在没有过拟合的情况下,我们获得了75.5%的精确值。
- 高效NetB1
我们在本项目中使用的第三种图像分类方法也是使用TensorFlow EfficientNet模型的迁移学习方法(Tan和Le,2019年)。我们从之前的模型(VGG16)中获得了我们实现的分类体系结构的灵感,因为我们得到了积极的结果(图3)。7)。我们还使用了具有相同值的回调函数EarlyStopping和ReduceLROnPlatform。
第一个结果显示精确值约为80%,优于VGG16,但仍然显示出过拟合,因此我们增加了Dropout图层的值,最终在没有过拟合的情况下获得了79%的分数。
这里展示了欧罗·™对六张图片的预测:
误差分析
- 念力矩阵
念力矩阵(图2)9)显示0、3和8类倾向于分别归类为7、4和13类: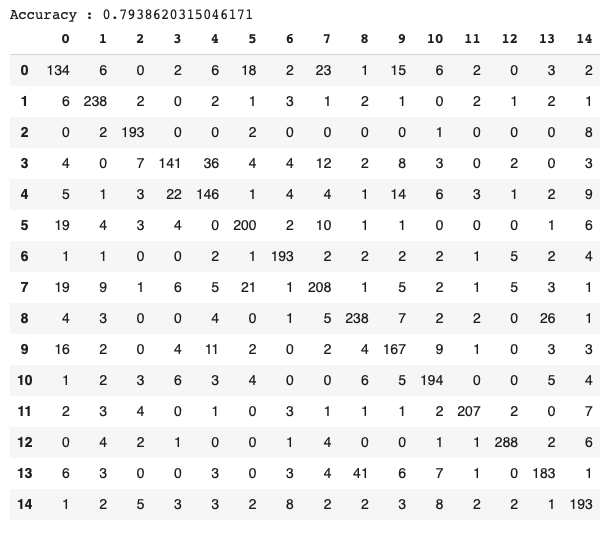
文献表明,这些混淆的纲在形态上非常相似,属于相同的分类科(表3)。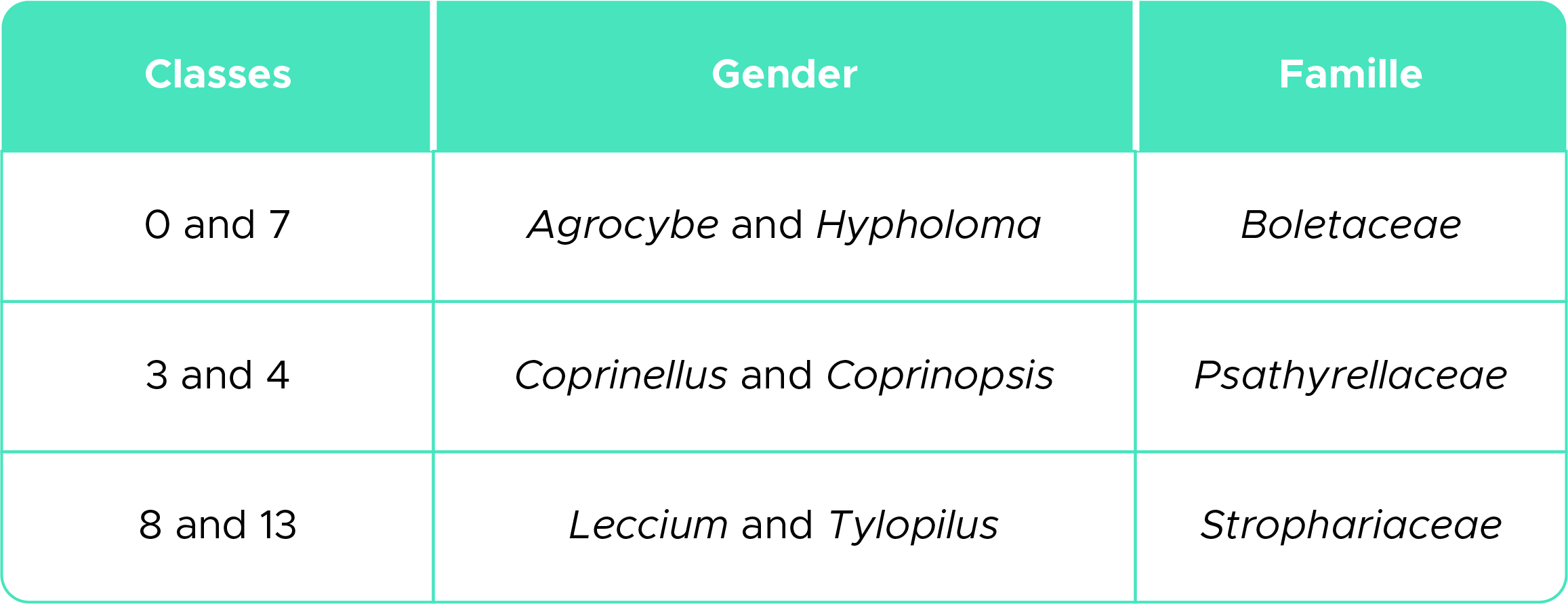
图10显示了混淆类之间的这些形态相似性:
类念力的原因之一可能是蘑菇的分类鉴定有误。我们使用的图像来自一个网页,在该网页中,用户只通过查看图像并根据他们的经验而不是根据客观的分类识别协议来对蘑菇图像进行分类。
考虑到念力矩阵的结果,我们希望评估我们的模型,而不使用其中一个混淆的类,以查看模型中数据的影响,如表4所示。
12个属(未剔除3个属)的准确率为85%,比以前的结果(79%)提高了6%。这一结果表明,如果我们有一个更准确的分类数据集来训练模型,我们可能会提高准确性。
- 图像质量
我们还注意到图像的质量非常不同(图11)。事实上,一些图像包含可能会阻碍模型正确识别蘑菇的元素,例如要分类的蘑菇周围有大量噪声的图像(图像1和2)。没有蘑菇要分类的图像(图3)。带有多个蘑菇的图像(图4)。
结束工作
下面的汇总表(表5)显示了使用的三种方法的精确值。我们还计算了软件包sklearn.metrics(Pedregosa等人,2011年)的œtop-k精确度分类分数-�。其中k=2和3来评估实际类别落在两个或三个最可能类别之间的频率。结果表明,对于我们的蘑菇图像分类问题,EfficientNet是最合适的方法,正确率分别为80%和86%。top-k accuracy classification score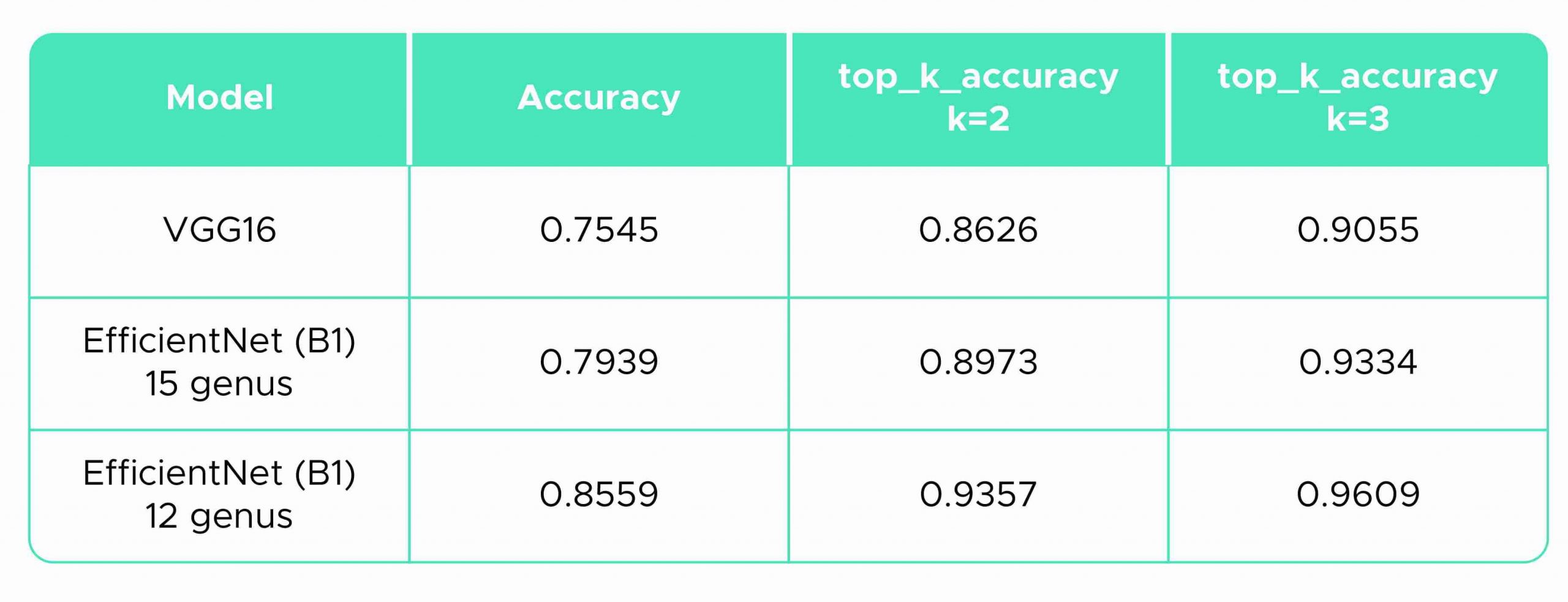
根据结果,计算机视觉似乎是物种形态分类的一个很好的替代方案,如果该模型可以使用大量高质量的图像进行训练,并且出现在图像中的物种具有由专家进行的分类。
需要改进的地方
这些结果可以通过几种方式改进。第一件事应该是用足够的数据集来训练模型,即更高质量的图像和更详细的分类。此外,增加每个标签中的图像数量(例如,从1000增加到2000)可以帮助减少由主观人类评估引起的形态分类错误。
另一项改进将是增加属的数量。目前,我们使用41个属中的15个来训练模型,每个标签有大约1000个图像。此外,对同一模型进行训练以进一步在物种水平上识别蘑菇图像也可以提高准确率。
最后,将模型中的特征提取部分与经典的分类模型(如随机森林模型或支持向量机模型)相结合,可以提高分类效果。
参考文献
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/07/%e8%98%91%e8%8f%87%e8%af%86%e5%88%ab%ef%bc%9a%e8%ae%a1%e7%ae%97%e6%9c%ba%e8%a7%86%e8%a7%89%e5%a6%82%e4%bd%95%e5%b8%ae%e5%8a%a9%e7%89%a9%e7%a7%8d%e8%af%86%e5%88%ab/
