
最新的研究不仅仅是检测物体
计算机视觉与模式识别会议(CVPR)是最重要的计算机视觉会议之一,其特色是由计算机视觉领域的领先者进行的最新同行评议研究。会议连续第二年在网上召开。尽管如此,CVPR仍然没有达到很高的期望,提供了充满刺激的技术内容、补充研讨会和教程的日程安排。
Flyreel在其产品中大量使用人工智能和计算机视觉,来自Flyreel的几名机器学习科学家参加了会议。(此外,Flyreel在今年的CVPR上发表了一篇关于3D布局重建的论文。)虽然CVPR的主题多种多样,但我们注意到出现了几个主题:Flyreel 3D Layout Reconstruction
- 用更少的数据做更多的事情
- 从2D图像看到3D
- 利用变压器作为通用神经架构
在CVPR之后,我们不能只拿出5篇顶级论文,不得不再增加一篇。以下是参加会议的Flyreel机器学习工程师总结的前6篇论文。
1.自我监督模型传输情况如何?
看看这份报纸。Check out the paper.
CVPR以及相关的机器学习社区(如ICML和NeurIPS)的一个发展趋势是在无监督和自我监督表示学习方面不断取得进展。自我监督学习是无监督学习的一种形式,其中数据表示是自动学习的,不需要任何标签监督。在过去的三年中,自监督方法在ImageNet分类上的性能已经接近监督性能。
尽管自我监督学习如雨后春笋般兴起,但当涉及到对不同下游任务的转移和评估时,仍有一些重要的开放问题没有得到回答。有两种类型的自监督评估:(1)线性评估,其中从未标记数据中学习的特征表示是固定的,并且只对目标任务训练头部;以及(2)在对目标任务进行微调期间更新整个网络或层的子集。
Ericsson和他的同事评估了13个顶级自监督模型在40个不同的下游任务上的传输性能,包括多镜头和少镜头识别、目标检测和密集预测,同时将它们与有监督的特征学习进行比较。他们使用的数据集与源ImageNet数据集具有很大程度的相似性,在源ImageNet数据集中,128万张图像可以进行标签监督。关于自监督传输性能,作者得出了以下结论:Ericsson and colleagues
钥匙外卖
这项工作的更广泛的实际意义是令人难以置信的令人兴奋的。对于研究和工业应用中的许多任务,计算机视觉社区一直(过度)依赖于有监督的ImageNet特征表示。然而,现在完全可以从野外未标记数据的宇宙中学习健壮的自我监督表示,从而避免了对可能昂贵得令人望而却步的人类监督和注释的巨大资源的需求。随着无监督表示学习的持续和持续进展,我们现在正在接近人工智能的一个重要里程碑:教计算机在更少的人类帮助下做更多的事情。
2.探索简单暹罗表征学习
看看这份报纸。Check out the paper.
除了通常在变形金刚(NeurIPS 2017)中的主导地位和日益增长的兴趣之外,在CVPR 2021上,视觉表征的自我监督对比学习还有另一个日益增长的趋势。支持对比学习框架的关键思想是在小的变换下强制相同图像的表征之间的一致性,这一思想可以追溯到Becker和Hinton(Nature 1992)。现代对比学习模型将同样的思想与最近在数据增强、神经网络结构和潜在空间中的对比损失方面的进展相结合,以学习鲁棒的无监督表示。
对比学习框架的核心结构是一对权重共享的暹罗网络,即编码器,用于比较和对比两个或多个输入。在最简单的形式中,编码器应该在给定同一输入数据样本的一对不同增强但相关的视图的情况下预测相似的输出。对比损失的目的是最大化由编码器从扩充数据示例中提取的表示向量之间的相似性。对比学习可能会产生一个不受欢迎的平凡解决方案,暹罗网络预测输出会“崩溃”为一个常数。最近的工作制定了缓解暹罗网络崩溃的策略:
- SimCLR利用反例对
- Byol介绍了使用指数移动平均权重的动量编码器。
- SwAV采用在线群集作为避免持续输出的一种方式。
为什么会发生崩塌仍然是一个悬而未决的问题。
陈和他使用一个简单的暹罗网络(他们称之为SimSiam)进行了一项全面的实证研究,没有其他竞争方法中发现的任何复杂策略。它们表明,当使用“停止梯度”操作时,SimSiam不会崩溃为平凡的解。他们推测,停止梯度的引入意味着应该有另一个正在解决的优化问题,并提出了一个假设,即SimSiam是期望最大化算法的一种形式,并支持实验分析。Chen and He
虽然需要做更多的理论和实证工作来解释如何以及为什么可以防止坍塌,但SimSiam被证明具有真正的实际应用。与竞争的对比方法相比,SimSiam在ImageNet线性评估上实现了好胜的结果,没有花哨的地方,而在VOC和CoCO检测和实例分割等下游任务上超过了ImageNet的有监督转移学习。值得注意的是,SimSiam很容易使用标准协议、普通的SGD优化和相对较小的批处理大小(512个示例)进行训练。相比之下,SimCLR需要4096或8192个示例的大批量才能正常工作,这可能是典型的计算机视觉工程师和从业者无法访问的。
钥匙外卖
最近自我监督表征学习的成功归功于暹罗网络对比学习的复兴。SimSiam在不增加复杂性的情况下提供了强大的基线,以防止“折叠”琐碎的解决方案,同时从未标记的数据中实现健壮的自我监督表示。毫无疑问,计算机视觉社区将建立在SimSiam的基础上,以进一步了解其潜在的理论属性,同时改进其强大的基线性能,以推进自我监督表示学习的包络。
3.使用包围盒检测进行深度估计
看看这份报纸。Check out the paper.
CVPR以几篇使用深度网络从单目图像中提取深度信息的论文为特色。这一领域一个出人意料的热门论文是“相机运动和对象检测的深度”一文,Griffin和Corso提出了一种非常简单的方法,可以重用从日常2D对象检测管道生成的边界框来估计真实世界的深度信息。Depth from Camera Motion and Object Detection
本文假设,每次在二维图像上检测物体的包围盒时,除了确定物体在图像中的位置外,还可以得到物体的物理尺寸信息。更大和/或更近的物体应该有更大的盒子。虽然一次探测可能不能告诉我们太多,但从几个相机位置进行的一系列探测实际上可以告诉我们很多关于探测到的物体有多大以及有多远的信息。
本文中的技术依赖于几种大多数人可能非常熟悉的日常光学效果。第一个是光学膨胀,这意味着我们离物体越近,它就应该看起来更大(即,在相机图像上占据更多像素)。但是,对象像素大小的变化速率取决于对象离相机的距离。特别是,当摄影机向远处移动时,远处的对象更改像素大小的速度非常慢(想象朝遥远的山脉走去),而物理上靠近摄影机的对象在摄影机四处移动时更改像素大小的速度要快得多。
然后还有视差运动,这是同一原理的变体。如果我们在观看对象时横向移动相机,距离越远,它在图像上移动的速度就越慢。视频游戏一直使用这种效果来在2D屏幕上显示深度。
还有其他要考虑的光学效果,包括是否涉及旋转,或者对象边界框对于一两帧来说是否错误。研究人员没有试图刻板地模拟这一切,而是训练了一个LSTM网络,以了解边界框变化、深度和相机位置之间关系的复杂性。其结果是,仅给出帧到帧摄像机运动和规则边界框检测的估计,网络就可以估计检测到的对象的真实世界深度!
钥匙外卖
深度提取在CV领域是一个古老的问题。然而,有了深深的网,新的(有时非常简单!)对于利基领域,这个问题的解决方案仍然层出不穷。
4.全深度全景图
看看这份报纸。Check out the paper.
在从全景图重建边界线方面已经做了很多工作(包括今年Flyreel在CVPR的工作),这可以用于深度估计任务。SliceNet的论文采取了一种不同的方法,专注于以逐个垂直切片的方式从全景图中直接提取360度深度图。Flyreel’s work SliceNet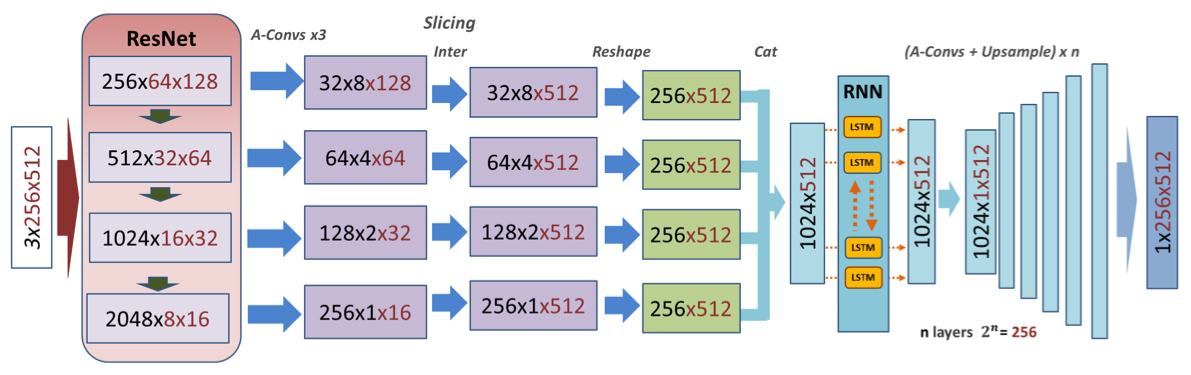
基于RNN的解码器架构与Flyreel在CVPR的研究中探索的架构相似,结果表明,与之前的全景深度测量相比,在分辨率和精确度方面都有一定的提高。
这种方法在计算上也很高效,作者开玩笑说,随着未来的一些改进,这种类型的全景深度架构甚至可能在AR或VR等实时应用中有用。当全景图变得更容易捕捉时,想象一下会发生什么也是令人兴奋的。在亚马逊上快速搜索一下,就会发现一些非常有趣的选择,可以让消费者购买360度相机。
本文论证了深度信息可以从一幅图像中提取出来。人们只能想象当360度全景格式的视频变得司空见惯时的可能性。
钥匙外卖
全景图包含大量信息,其超宽视场格式可通过有效利用像素之间的长物理距离交互进行深度估计。鉴于全景图广泛适用于从娱乐到建筑的所有领域,预计在未来几年内将在这一子领域取得快速进展。
5.长颈鹿:将场景表示为构图生成神经特征场
看看这份报纸。Check out the paper.
自从去年发表了开创性的论文“NERF:将场景表示为用于视图合成的神经辐射场”(Mildenhall等人。ECCV 2020)之后,研究如何在更广泛的领域中利用NERF最先进的视图合成能力的研究呈爆炸式增长。下图提供了一些由nerfs实现的令人印象深刻的详细合成渲染。explosion
NERF解决了在给定一组图像和用于捕捉它们的相应相机矩阵的情况下,有效地呈现静电场景的新颖视图的问题。上面显示的示例所示的视图不是最初提供的图像集的一部分,但它们非常逼真。
长颈鹿是研究是否有可能通过以一种新颖的方式将nerf和Gans的优点捆绑在一起来学习构图3D场景的生成模型的工作的一部分。大多数现有的方法集中于生成3D场景的图像,其中可以显式地控制特定的属性,例如姿势、形状和外观。然而,底层表示不足以以简单且可控的方式解开属性。本文的主要贡献在于,将3D结构融入到用于生成图像的表示中,可以更忠实地解开感兴趣的属性之间的纠缠,并提供一种直接控制的机制。GIRAFFE
为了实现这一点,作者提出了一种神经体系结构,将场景分解为摄像机姿势(从中采样图像)和一组N个对象(包括背景),每个对象都有姿势和形状和外观的潜在代码。这些3D元素被集成到可区分的渲染流水线中,以生成适合于GaN训练的图像。
生成过程的概述如下图所示。
最终的结果是一个系统,它可以生成具有多个对象的场景的合成视图,这些场景的姿势是可控的。该系统还能够对对象的形状和外观进行采样,以产生一组不同的可能场景。下面的图表更清楚地展示了这一点。
直接的应用包括计算机图形学,其中这样的方法可以生成嵌入在底层3D结构中的高度逼真的合成内容。
钥匙外卖
将构图3D结构添加到图像生成过程中可以帮助模型获得比以前仅在2D中工作的方法更可控和更高保真度的合成结果。此外,NERFS和GAN的耦合已被证明是强大的,可能很快就会产生能够呈现广泛的完全可控的高质量虚拟和增强现实场景的系统。
6.少即是多:通过稀疏采样实现视频和语言学习的ClipBERT
看看这份报纸。Check out the paper.
从视觉和语言等多种形式有效学习是机器学习的一个主要目标。撞击的标准方法这个问题通常涉及针对每个输入模态分别预先训练特征提取器,然后针对目标任务训练跨模态网络,如下所示。
ClipBERT今年获得了最佳学生论文荣誉称号,它提出了一种统一的算法来联合学习表示法,这些表示法可以执行视觉问答和文本到视频匹配等任务,并且可以进行端到端的高效训练。为此,作者引入了一个同时支持视频和语言作为输入的框架,并使用了Bert Transformer,这是一个强大的语言建模体系结构。虽然Transformers以前曾用于跨模式学习,但在过去的一年中,许多出版物都有力地表明,Transformers可以成为一种通用架构,适用于各种任务和模式,并具有语言以外的应用。值得注意的是,最近的工作“当视觉变形金刚在没有预训练或强数据增强的情况下表现优于ResNet”(Chen等人。2021年)为变形金刚的通用性提供了一个令人信服的案例。ClipBERT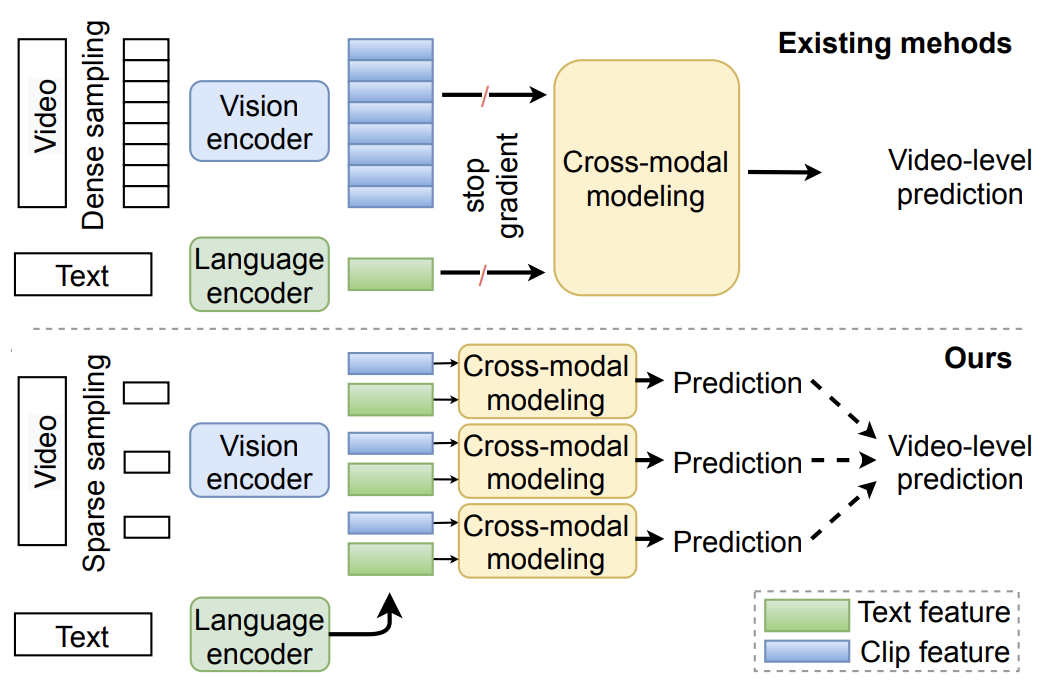
在ClipBert中,作者建议在培训期间对视频中的短片段进行稀疏采样,而不是利用整个视频。他们证明,他们的方法比使用完整视频的最先进的方法性能更好。
此外,他们还表明,图像-文本预训练能够提高他们的模型在视频-文本任务上的性能,并具有更高效的额外好处。
ClipBERT的完整体系结构如下所示,以供参考。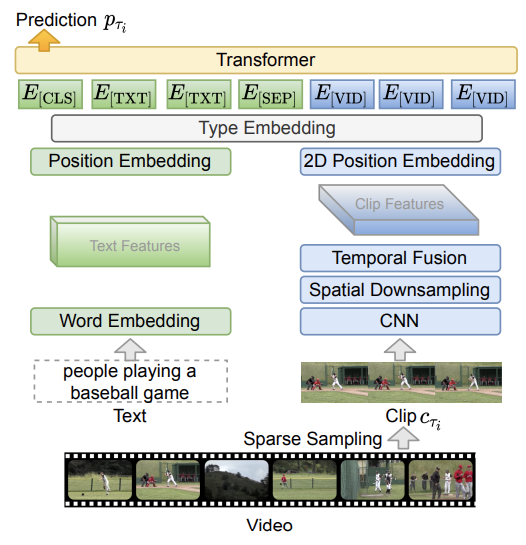
通过利用端到端可训练的跨模式功能和高效的稀疏视频片段采样,ClipBERT能够在各种下游任务上显著优于最先进的方法。
钥匙外卖
当涉及到从视频中进行跨模式学习时,越少越好。因此,越来越有可能利用一系列数据模态来解决现实世界中的问题,如视觉字幕和视觉问题回答。
超越目标检测
CVPR 2021在广泛的研究和应用领域延续了计算机视觉的快速发展。今年我们最喜欢的一些主题包括用更少的数据做更多的事情,提取嵌入到2D图像中的潜在3D数据,以及在NLP以外的应用中使用变形金刚。看到这一领域发展得如此之远和如此之快,令人既兴奋又谦卑。
Flyreel为保险公司提供Total Property Underability(TM),为承保、索赔和风险管理带来更好的保险结果。欲了解有关飞盘的更多信息,请访问https://flyreel.co.。Flyreel https://flyreel.co.
是的,我们正在招聘!
Vu Tran是Flyreel的机器学习科学家。他致力于用有限的标记数据改进计算机视觉模型,使用的技术包括半监督学习和少量学习。弗吉尼亚大学喜欢旅行和户外探险。Vu Tran
维克多·帕尔默(Victor Palmer)是Flyreel的机器学习科学家。他的工作重点是利用深度网络和经典技术的结合,从图像和传感器数据中提取3D结构的系统。Victor Palmer
泰斯特·迪里巴(Tigist Diriba)是Flyreel的机器学习科学家。他热衷于将最先进的方法应用于更广泛的机器学习系统中的无监督学习等领域。Tigist Diriba
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/09/6%e4%b8%8d%e8%83%bd%e9%94%99%e8%bf%87cvpr-2021%e7%9a%84%e8%ae%ba%e6%96%87-2/
