
卫星图像提供了对各种市场的独特见解,包括农业、国防和情报、能源和金融。新的商业图像提供商,如Planet,每天都在使用小卫星的星座来捕捉整个地球的图像。Planet
这些新图像的洪流已经超出了组织手动查看捕获的每个图像的能力,因此需要机器学习和计算机视觉算法来帮助实现分析过程的自动化。
该ConvNet的目的是帮助解决在卫星图像中检测大型船只位置的困难任务。自动化这一过程可以应用于许多问题,包括监控端口活动水平和供应链分析。这个模型可以用在更复杂的框架中,比如YOLOv3模型和Fast R-CNN模型,这样就可以用边界框精确定位港口中的多艘船。
数据集
该数据集由从加利福尼亚州旧金山湾和圣佩德罗湾地区收集的Planet卫星图像中提取的图像芯片组成。它包括4000幅80x80RGB图像,分别标有“有船”或“无船”分类。图像芯片来自PlanetScope全画幅视觉场景产品,这些产品被正射校正到3米像素大小。
要求
下面是它的工作原理
- 我们的输入是一个训练数据集,它由N个图像组成,每个图像都标有2个不同类别中的一个。
- 然后,我们使用这个训练集来训练ConvNet,以了解每个课程的外观。
- 最后,我们通过要求分类器预测它从未见过的一组新图像的标签来评估分类器的质量。然后,我们将把这些图像的真实标签与分类器预测的标签进行比较。
- 然后保存模型及其权重以供将来使用。
代码
让我们开始学习代码吧。
我们将使用matplotlib来绘制图像和标签。TensorFlow和Kera是最常用的深度学习框架之一,我们将使用它们来创建我们的ConvNet并设计我们的模型。
加载数据集
数据集中的图像被加载到NumPy数组中,标签[0,1]对应于类no-ship和Ship。数据被加载到NumPy阵列中,因为数据增强和上采样/下采样更容易执行。
探索性数据分析
在这里,我们将使用条形图对数据集执行简单的EDA,以确定类是否不平衡。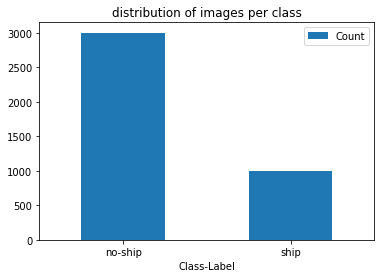
数据增强
Ship类中存在的图像被增加,然后存储在数据集中,因此类具有相同的表示形式。
当前类的比例为1:3,这意味着对于存在于船类中的每个图像,都存在于无船类中的3个图像。这将通过为Ship类的每个原始图像生成2个增强图像来解决。这将使数据集平衡。
则Label NumPy数组是使用来自KERAS的TO_CATEGORIC进行热编码的数组。这通过保持类相对于标签的同等位置,消除了数据集中任何不必要的偏差。
拆分数据
使用在42设置的相同种子值随机混洗图像和标签数组,而不是使用STRAIN_TEST_SPLIT。这允许图像及其对应的标签即使在洗牌之后也保持链接。
此方法允许用户创建所有3个数据集。训练和验证数据集用于训练模型,而测试数据集用于在不可见数据上测试模型。未见数据用于模拟真实世界的预测,因为模型以前未见过此数据。它允许开发人员查看模型的健壮性。
数据已被分成-
- 70%-培训
- 20%-验证
- 10%-测试
模型体系结构
我们的模型结构由四个Conv2D层组成,其中输入层具有2x2MaxPool2D池化层,每个层紧随其后的是由64个神经元组成的致密层和一个由128个神经元组成的致密层,每个神经元具有RELU激活函数,最后一层具有2个神经元和用于进行类预测的Softmax激活函数。
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
zero_padding2d (ZeroPadding2 (None, 58, 58, 3) 0
_________________________________________________________________
conv2d (Conv2D) (None, 56, 56, 16) 448
_________________________________________________________________
batch_normalization (BatchNo (None, 56, 56, 16) 64
_________________________________________________________________
conv2d_1 (Conv2D) (None, 54, 54, 32) 4640
_________________________________________________________________
batch_normalization_1 (Batch (None, 54, 54, 32) 128
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 27, 27, 32) 0
_________________________________________________________________
dropout (Dropout) (None, 27, 27, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 23, 23, 32) 25632
_________________________________________________________________
batch_normalization_2 (Batch (None, 23, 23, 32) 128
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 11, 11, 32) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 11, 11, 32) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 9, 9, 64) 18496
_________________________________________________________________
batch_normalization_3 (Batch (None, 9, 9, 64) 256
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 4, 4, 64) 0
_________________________________________________________________
dropout_2 (Dropout) (None, 4, 4, 64) 0
_________________________________________________________________
flatten (Flatten) (None, 1024) 0
_________________________________________________________________
dense (Dense) (None, 64) 65600
_________________________________________________________________
dropout_3 (Dropout) (None, 64) 0
_________________________________________________________________
dense_1 (Dense) (None, 128) 8320
_________________________________________________________________
dense_2 (Dense) (None, 2) 258
=================================================================
Total params: 123,970
Trainable params: 123,682
Non-trainable params: 288
_________________________________________________________________我定义了指定何时保存模型的检查点,并实现了提前停止,以提高培训过程的效率。
我使用ADAM作为优化器,因为它提供了更好的结果。由于我们的模型只有两类,所以我使用二进制交叉熵作为我们模型的损失函数。我对模型进行了50次迭代训练。但是,只要预测的准确性不受影响,您可以根据自己的喜好自由使用许多不同的参数。
这是一个绘制损失和精确度的函数,我们将在训练模型后得到该函数。保存模型,并使用定义的函数绘制结果。
结果
损耗/精确度与时代之比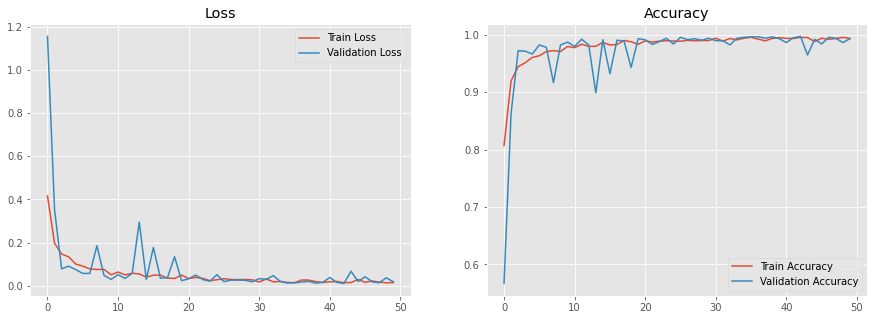
该模型达到了大约70%的验证准确率,考虑到数据集的大小和我们将模型保持在轻量级以供部署的事实,这是相当不错的。
预测
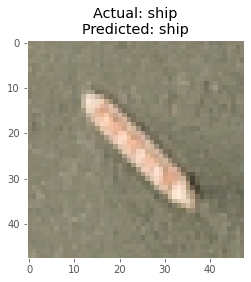
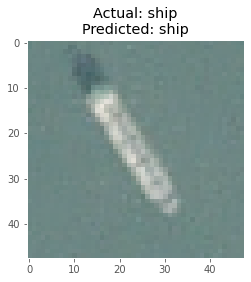
在使用模型进行预测后,我从测试图像中获取了一批8幅图像,并用相应的真实标签和预测标签绘制了它们。
以下是该模型做出的一些预测: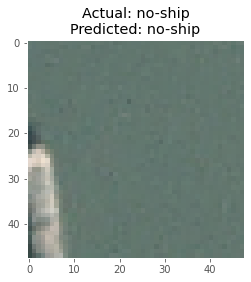
结论
在本文中,我演示了如何使用从零开始构建的ConvNet,通过深度学习从航空图像中检测港口中的船只。这个简单的用例可以用作更复杂的框架中的一个模块,用于实现目标检测,其中可以从单个场景图像中检测和标记船只。
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/11/%e5%88%a9%e7%94%a8%e6%b7%b1%e5%ba%a6%e5%ad%a6%e4%b9%a0%e4%bb%8e%e8%88%aa%e6%8b%8d%e5%9b%be%e5%83%8f%e4%b8%ad%e6%a3%80%e6%b5%8b%e8%88%b9%e8%88%b6-2/
