
引言
- 此篇為Vit的延伸閱讀,原始Vit的补丁使用固定大小且在圖像中並沒有重疊的部分,導致會少考慮到一些空間上的資訊,另外作者也發現原始Vit有“冗余注意”的現象,以上兩個問題導致輸出的功能图會有如下圖的問題,分別是缺少EDGE、LINE的特徵和有些全白或全黑的輸出。

- 因此作者提出了令牌到令牌模块解決鄰近补丁的本地结构資訊量的問題,並借鑒有线电视新闻网提出了深窄的变压器提升速度降低參數量。
方法
此篇提出兩個架構,第一個是令牌到令牌模块(T2T模块)、用來提取本地结构的資訊以及減少令牌的長度,第二個是T2T-VIT主干、把T2T的输出做注意、並使用深度窄的架構。
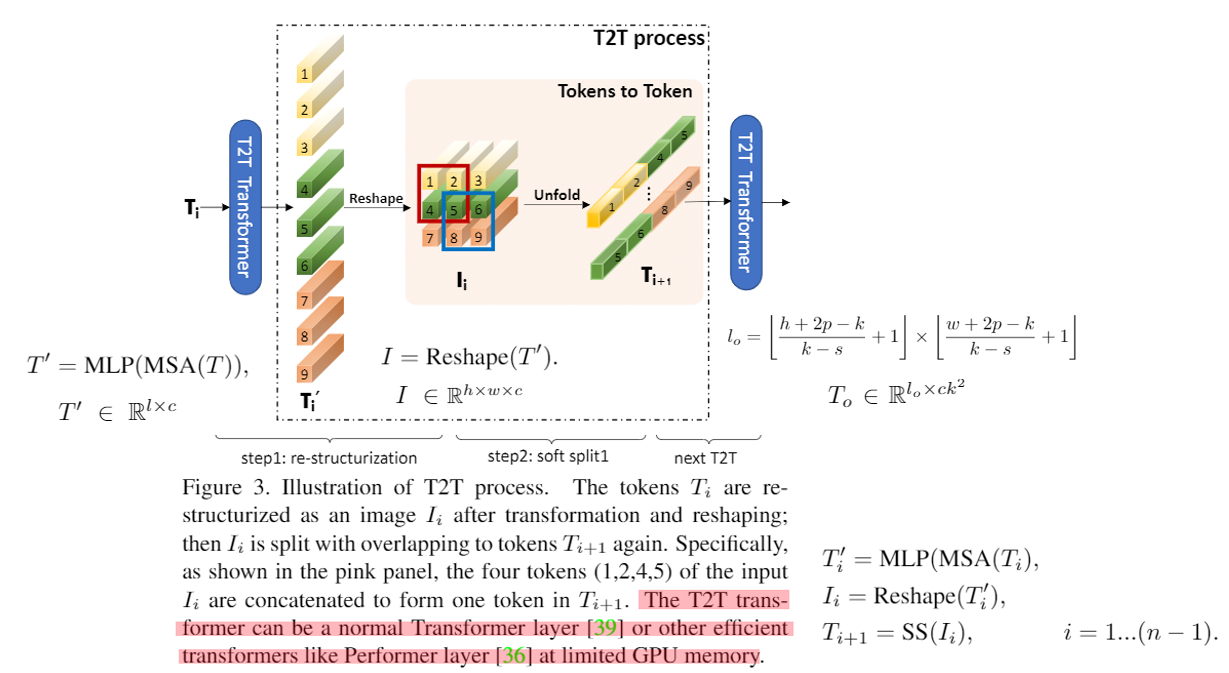
令牌到令牌:渐进式令牌化
- T2T变压器是指任意一種Vit的架構(作者採用Performer),概念很單純就是把变压器的输出重塑成像影像那樣然後做類似卷积的方式來減少令牌數量,然後加深深度,整體流程如图4,先软分裂之後再做兩次T2T,输入尺寸為224×224,输出尺寸為14×14,然後丟到T2T-VIT主干。
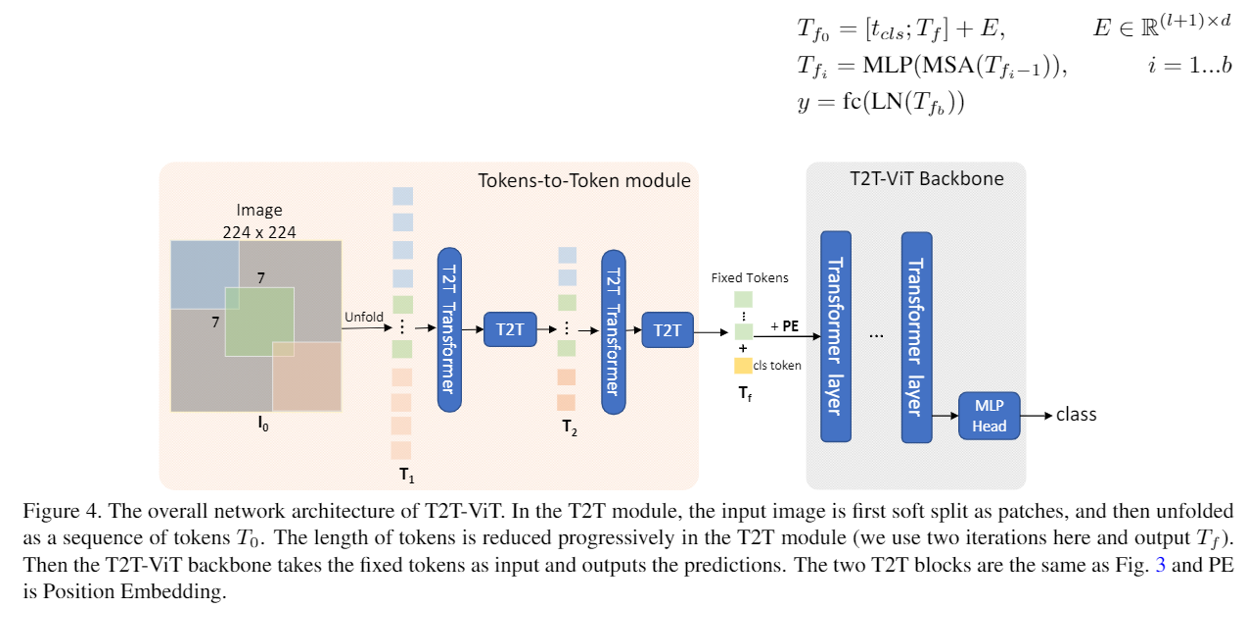
T2T-VIT主干
- 主要解決图2的“冗余注意”,並對变压器減少參數加深層數,原始的VIT-B/16有12個变压器层,768个隐藏维度,T2T-VIT-14則用14個变压器层,第384个隐藏维度實現深窄的架構,如下圖右邊,最後在經過MLP预测。
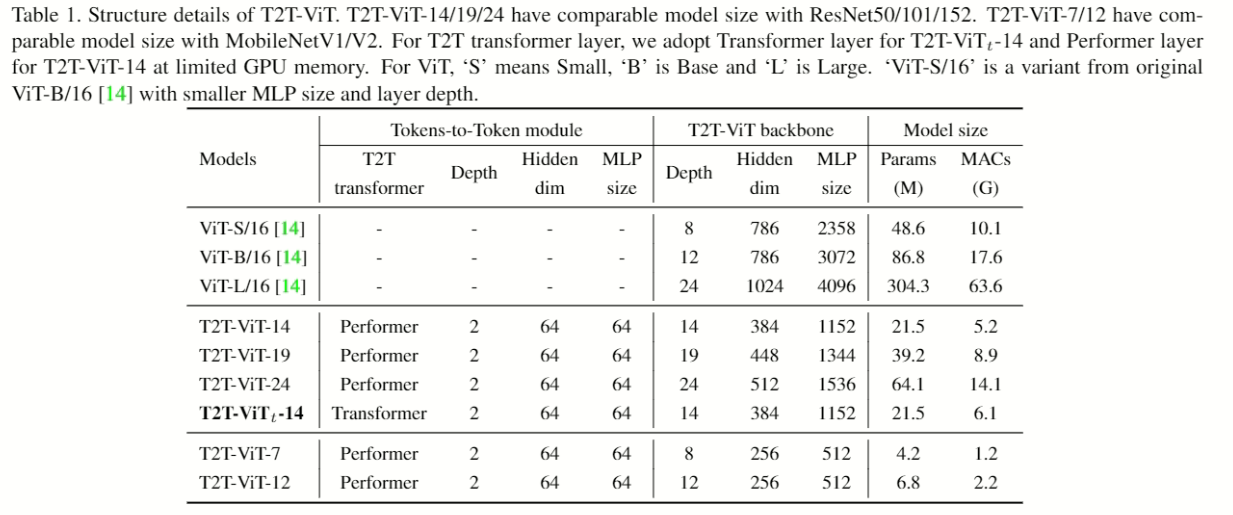
实验
- T2T-VIT-XX後面的XX表示变压器的層數和對應比例的隐藏尺寸,為了實驗公平比較其他型号故意用成參數量差不多進行比較。
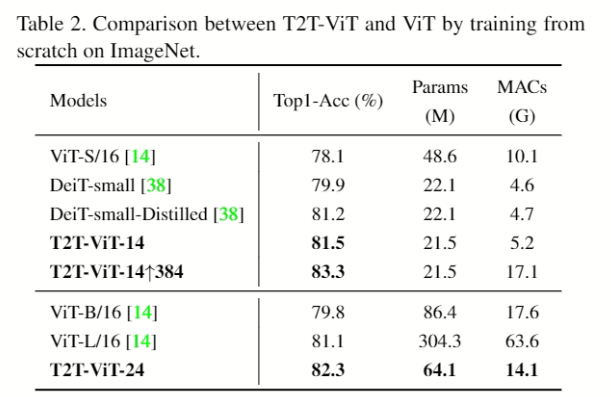
在ImageNet上从头开始培训
- 384的是指输入图像分辨率,[38]是用蒸馏的型号。
- 基于為了實驗公平比較有线电视新闻网的的模型故意用成參數量差不多進行比較,這邊比較的是Resnet。
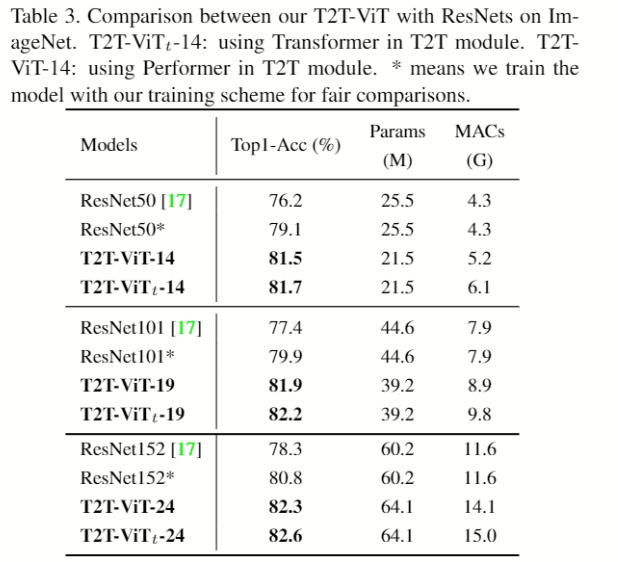
- 這邊比較ModbileNet.

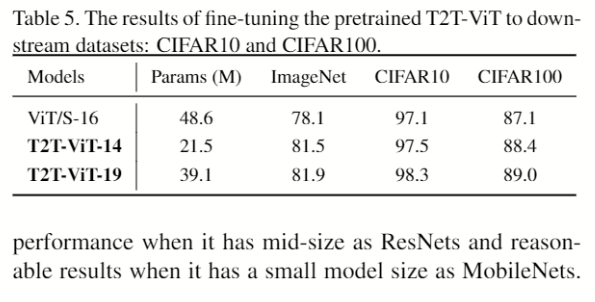
关于CIFAR10/100的迁移学习
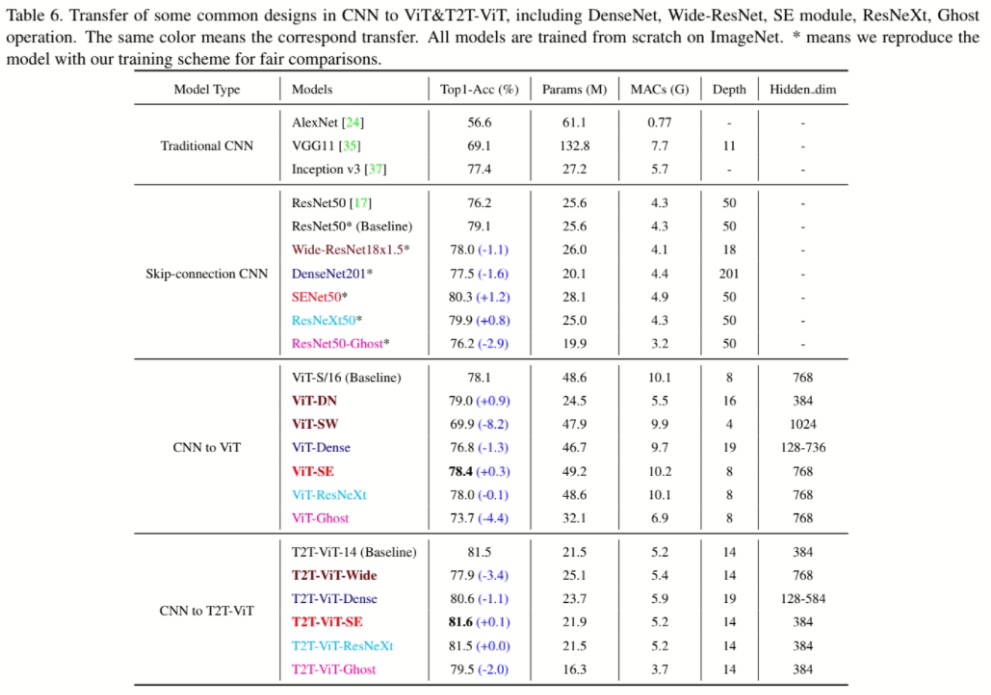
从CNN到VIT
- 透過不同有线电视新闻网的架構強化VIT做實驗,可以看到VIT-DN(深窄)效果好又減少參數量,因此有套用到T2T-VIT的架構中,表格提到的相關架構可參考此文章或論文。
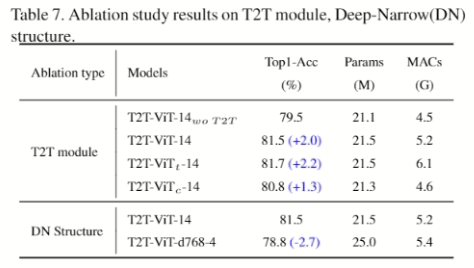
消融研究
- Wo T2T表示沒有T2T模块,_t的是用一般变压器,_c是把T2T改成3個卷积层,d768-4是指隐藏尺寸768、4层。
参考文献
[arxiv]arxiv
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/17/%e4%bb%a4%e7%89%8c%e5%88%b0%e4%bb%a4%e7%89%8cvit%ef%bc%9a%e5%9c%a8imagenet%e4%b8%8a%e4%bb%8e%e5%a4%b4%e5%bc%80%e5%a7%8b%e5%9f%b9%e8%ae%ad%e8%a7%86%e8%a7%89%e5%8f%98%e5%bd%a2%e9%87%91%e5%88%9a/
赞 (0)
使用OpenCV在Jupyter笔记本电脑中显示实时网络摄像头源
« 上一篇
2021年7月17日 am5:08
通过使用纹理组合多幅图像来校正曝光过多的图像
下一篇 »
2021年7月18日 am5:01
