
NLP和计算机视觉是机器学习中最受欢迎的应用,它可以让计算机了解我们作为人类是如何看东西和如何阅读的。在区分两组或更多组文档或图像的情况下,这将是一个漫长的过程。同时,预处理步骤还需要一种改进的矢量化数据质量,例如来自用于NLP的TDF-IF或用于图像的NumPy阵列。
以自然语言处理(NLP)为例,在去除停用词和标点符号之后,从具有数万个唯一单词和n-gram的数千个标签文档中进行。通过使用词频和倒排文档频率(TF-IDF),可以得到一个文档中词频的乘法稀疏矩阵及其在其他文档中可能存在的倒对数尺度的惩罚。由于有数以万计的单词和n元语法,这意味着有那么多变量将文档定义为特定的标签。选择正确的模式将是具有挑战性的。以下是基于这些数据构建的莎士比亚数据集的二维简化表示,该数据集按前10位说话人分组
https://raw.githubusercontent.com/ropensci/elastic_data/master/data/shakespeare_data.jsonhttps://raw.githubusercontent.com/ropensci/elastic_data/master/data/shakespeare_data.json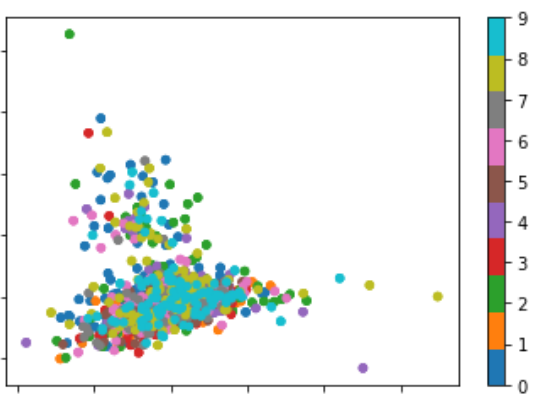
从另一方面来说。让我们看一个来自MNIST手写数字的常见示例。下面几乎有1800种不同风格的数字。
构成64个特征的每个数字都有8×8像素。每个点代表一个从0到16的数字。通过主成分分析(PCA)将64维空间简化为2维空间,我们可以得到如下所示的结果
当然,它还不是一个完美的可分离的代表。但是MNIST模型有一些莎士比亚数据集可以遵循的东西。不管这两个稀疏矩阵中的很大一部分,莎士比亚都比MNIST有更多的空白(数千个特征与8×8个特征)。MNIST做得很好的一件事是使用0到16灰度。这意味着当一个数字被写在受影响的书写区域和空白处之间的某个地方时,在1到15之间有边框或数字。我会把这些边界称为所谓的阴影。
这里是来自10个扬声器的1000个文档的示例,具有4000个独特特征(每个文档4个相等特征,每个扬声器100个文档),仅用于说明。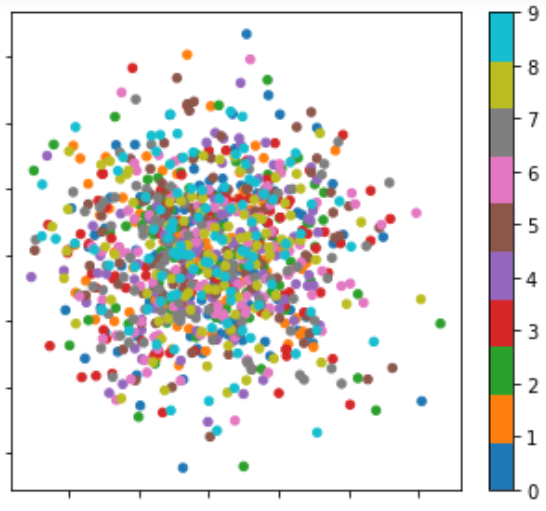
https://farius.s3.us-east-2.amazonaws.com/pca/test_farius.csv上面的链接显示了一个遵循MNIST样式的数据集的示例,它使用最大刻度16来强化每个文档中标记到特定说话人的特定特征的存在。逐渐地,从最薄到最厚,比例为8,4,2,1的阴影会逐渐增加。
下面是添加最细阴影8时的聚类效果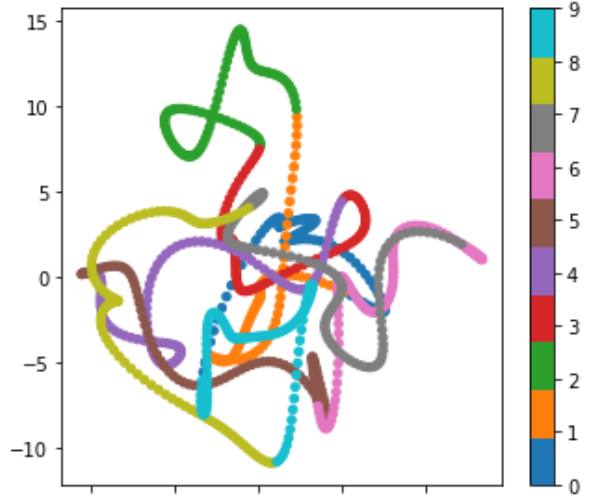
下面是添加下一个阴影4时的聚类效果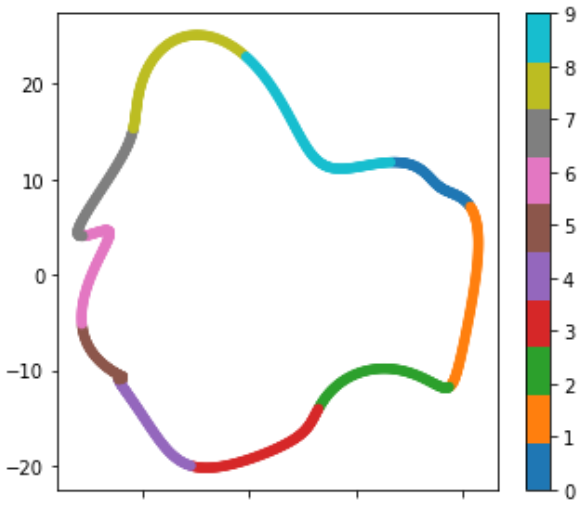
https://colab.research.google.com/github/FariusGitHub/DataScience/blob/master/PCA.ipynbhttps://colab.research.google.com/github/FariusGitHub/DataScience/blob/master/PCA.ipynb
请参考上面的链接来模拟添加阴影的效果
结论
在不考虑搜索最佳预测模型的情况下,稀疏矩阵可以得到相应的改进。按照从最大可能到最小可能的顺序填充每个文档中相对于彼此的空白特征将使主成分分析呈现更好的可分离性聚类。
简而言之,这项技术更像是一种线性回归,因为我从每个文档中选择了一个唯一的特性。这对于NLP来说可能比对于计算机视觉更有可能。但在任何情况下,其想法都是用有意义的信息来丰富稀疏矩阵,填充相对于彼此的空白特征。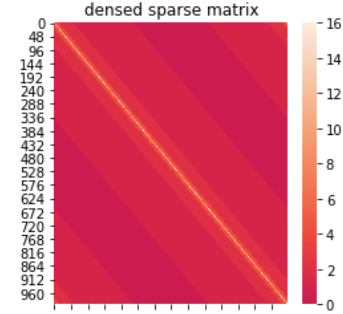
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/17/%e4%b8%80%e7%a7%8d%e6%94%b9%e8%bf%9b%e7%9a%84nlp%e5%92%8c%e8%ae%a1%e7%ae%97%e6%9c%ba%e8%a7%86%e8%a7%89%e5%8f%af%e5%88%86%e7%a6%bb%e8%81%9a%e7%b1%bb%e7%ae%97%e6%b3%95-2/
