
論文連結:“协调注意力以实现高效的移动网络设计”《 Coordinate Attention for Efficient Mobile Network Design 》
作者與出處:
GitHub链路GitHub Link
引言
注意机制近年已被大量、廣泛地研究各種提升深度神經網路成效的方法,而其主要作用是告訴模型要“關注”的部分是甚麼,以及在哪裡。但當這種機制應用於輕量的模型架構時,會因為計算複雜度高,而出現延遲的現象.
當考量到計算資源有限的條件,發展出了SE注意事项(CVPR2018)、這種做法會先以2D全球池取得渠道維度上的特徵,再做渠道注意事项、用比較少的計算量取得最終效能上的提升:SE attention ( CVPR 2018 )
然而上述這種作法只考量信道间的資訊,忽略了位置信息,因此對於分段、检测等任務的成效就比較差。
而像是bam、cbam等近期一點的研究,有試圖探索Position Information的Attribute做法,主要是透過減少輸入資訊在Channel上的維度來減少計算量,並將這些資源用來計算空間維度上的注意:BAM CBAM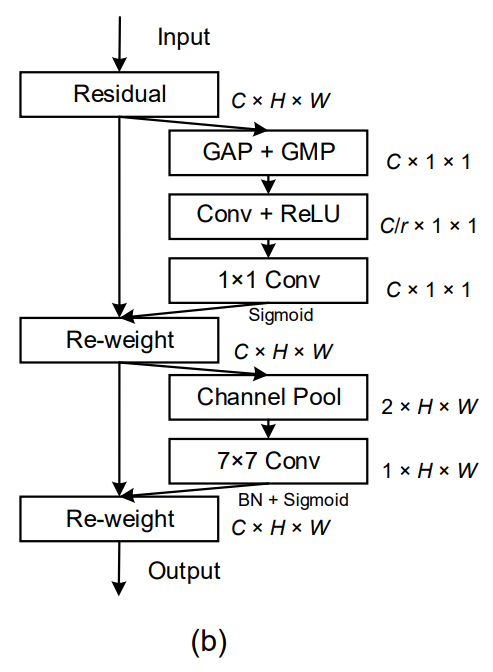
但這種做法又因為卷积本身的運作邏輯而只能看見局部資訊的關聯性,無法對Long-Range Dependents進行建模,這對於許多Vision任务來說,並不是件好事。
而該論文提出了一種新穎的注意机制、它可以將位置信息、嵌入於通道注意和注意机制(中,並使輕量的神經網路可以對很大的區域做到Attribute的效果,但並不會同時增加太多額外的計算量)。
為了避免2D Global Pooling的過程會損失Pooling Position Information,該論文將Channels Attribute分解成2個平行運算的1D特徵編碼過程,便可有效地在Attribute Map上整合座標資訊.
這2組1D特徵會分別對原始特徵圖的2個不同方向進行編碼,並捕捉远程依赖关系、而位置信息會在這個過程中被保留,最終只要將這2組1D相乘,便可取得坐标感知的注意图。由於這2組1D特徵的方向性類似於座標的概念,該論文稱之為协调注意。
該論文提出的坐标注意一共有下列3個優勢:
為了證明前述的優勢,該論文在3個不同任務上的常見資料集進行了實驗,並與其他注意事项做法進行比較:
黃色部分就是該論文提出的协调注意,細節就留在实验章節再呈現。
相关工作
移动网络架构
近年在移动网络的SOTA基本上基於2種作法:
HBONet在每個倒置残差挡路做降采样的操作,並對空間資訊進行重現。HBONet
洗牌NetV2則在反向剩余挡路的前後分別對频道進行拆分、洗牌等操作。ShuffleNetV2
MobileNetV3NAS(神经体系结构搜索)應用了演算法,在不同深度的設定中,找出倒置剩余挡路的最佳激活函数以及扩展率。MobileNetV3
類似作法還有MixNet、EfficientNet、ProxylessNAS等研究,也嘗試了不同的搜尋策略,試著找出沿深度可分离的卷积的最佳核大小,或是神經網路架構的扩展比、輸入解析度、寬度、深度等參數的最佳設定。MixNet EfficientNet ProxylessNAS
更近期一點的研究有重新思考Depthly可分离卷积的做法,加入了瓶颈的結構,並提出了移动下一步。MobileNeXt
注意机制
至於Attribute的相關研究,除了前面提過的SE Attribute、BAM、CBAM等作法,還有Genet、Gala、AA、TA等不同研究,嘗試延伸類似想法並在空間上設計更進階的Attribute作法.SE attention BAM CBAM GENet GALA AA TA
近期也有一系列非本地/自我注意的研究,可以做到空间或频道的非本地注意,並捕捉不同種類的特徵。但由於Self-Attendant模組本身的計算量龐大,因此不常被用在輕量的神經網路架構中(自我关注计划)。
而該論文提出的COLIBRATE ATNOTION不同於前述這些做法的地方在於,COLCOLATE ACTION透過將2D Global Pooling拆解成2組1D編碼的操作,以輕量的特性做到更好的Attribute效果.
协调注意力
為了能夠較清楚地解釋协调注意,在這部分會先回顧一下SE注意在公式上的表述,再說明該論文的做法。SE attention
重温挤压与激发注意
由於一個標準的卷积本身很難對信道之間的關聯性進行建模,所以透過額外建立信道的相互依赖可以增加模型對各個信道的敏感度,並對最終進行分類決策有幫助。
此外,標準的卷积做法中,其實難以捕捉全球的資訊,而過程中採用全球平均池化也可幫助模型改善這個問題。
而SE注意事项本身可被分解成2個步驟:SE attention
若將輸入的特徵圖以X表示,那對第c個Channel進行Squeeze操作可被表述成:
而激励目的是要捕捉通道依赖关系,也就可表述成:
其中的zˆ是個变换函数: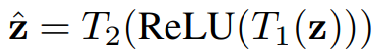
雖然目前有被廣泛應用於輕量的網路架構中,但就如同简介所提到的,這種做法缺乏對於位置信息的關注,後續會有實驗證明,該論文提出的坐标注意有改善這個缺點。
协调注意块
該論文提出的坐标注意一樣有2個步驟:
新浪挡路(整個Weibo的示意圖如下):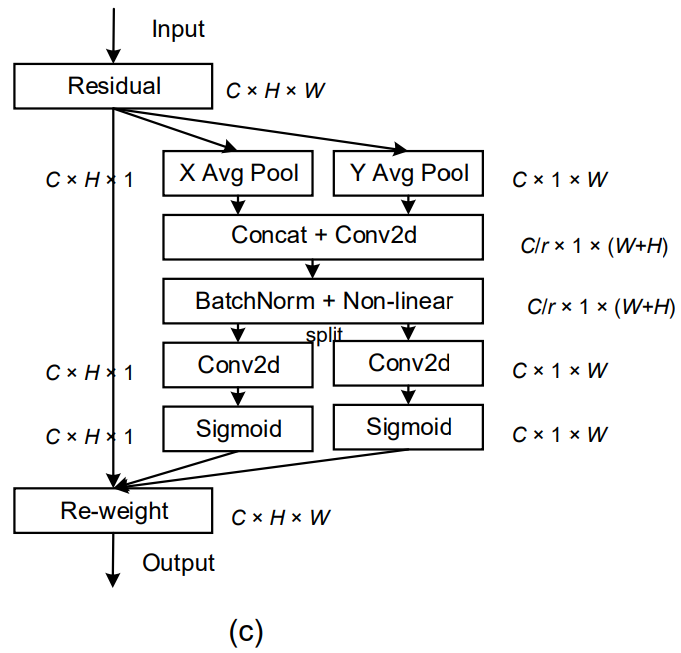
坐标信息嵌入
而上圖的坐标注意為了要讓模型在捕捉Long-Range的特徵時,可以同時帶有精準的Position Information,便將前面第一個公式拆解成一組1D特徵編碼操作,這組編碼分別在垂直與水平軸向進行Pooling的操作,公式可表述成: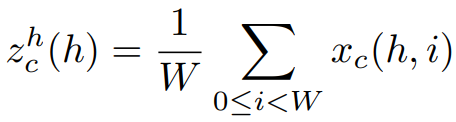

上標h和w分別是指高、寬,也就是垂直與水平軸,目的就是希望模型在捕捉Long-Range Dependations的同時,可以保留位置信息,也就能對空間定位相關的任務更有幫助。
协调注意力生成
基於前述的2道公式,坐标注意會再進一步生成對應的注意图,這邊作者們有考量下列3個因素進行設計:
在實際運算上,會先將前2個公式得出的結果進行串接,並透過1×1卷积变换函数(F1)進行處理: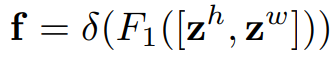
而最終輸出的f可表述成: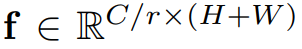
這邊的r是Reduce Ratio,用於控制這個挡路的大小。
接著會將這個f拆分成2沿著空間軸向拆分成2組張量: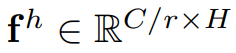

再透過另外2組1×1卷积变换(F_h、F_w)分別轉換成一樣信道數的張量:
這邊的g就是Attribute的權重,而协调注意挡路可被表述成: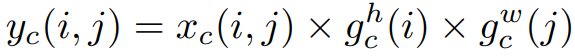
实施
該論文在實作上是對2個經典輕量模型架構:MobileNetV2(A)、MobileNext(B)嵌入协调注意挡路,示意圖如下:MobileNetV2 MobileNeXt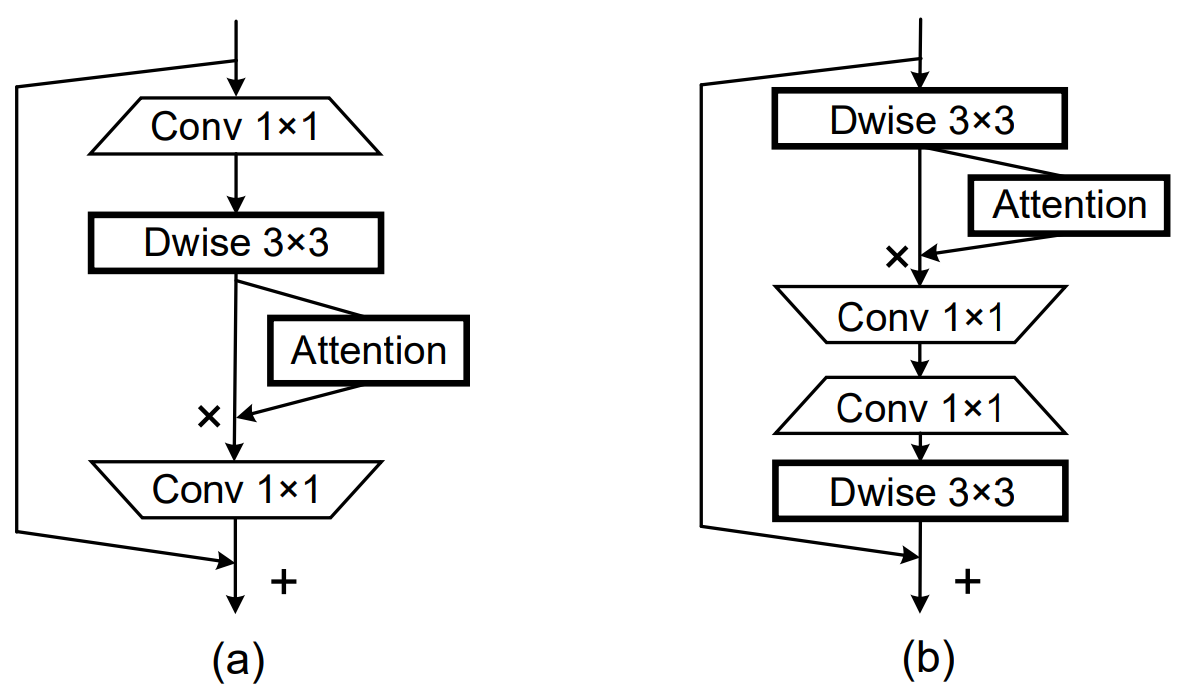
实验
实验设置
該論文的實驗過程採用Pytorch作為開發框架,Baseline的模型架構多以MobileNetV2為主,部份實驗還有採用MobileNext、Efficiency Net-b0,以下為其他相關實驗設定:MobileNetV2 MobileNeXt EfficientNet-b0
- 优化器:sgd(衰减和动量=0.9)
- 权重衰退:0.00004
- 初始学习率:0.05%(採用余弦学习时间表)
- 批量:256
- 纪元:200
(有提到使用4張Nvidia GPU但並未說明確切型號)
由於除了基本的分類任務外,也有進行物件偵測、語意分割等下游任务的實驗,所以採用的資料集有ImageNet、可可、帕斯卡VOC和城市景观。
消融研究
這部份是為了確認COLISTRIBLE AUTICATION的不同Component對整體的貢獻,所以分別對只有垂直或水平軸Attribute的情況進行實驗,並與SE AtSE attention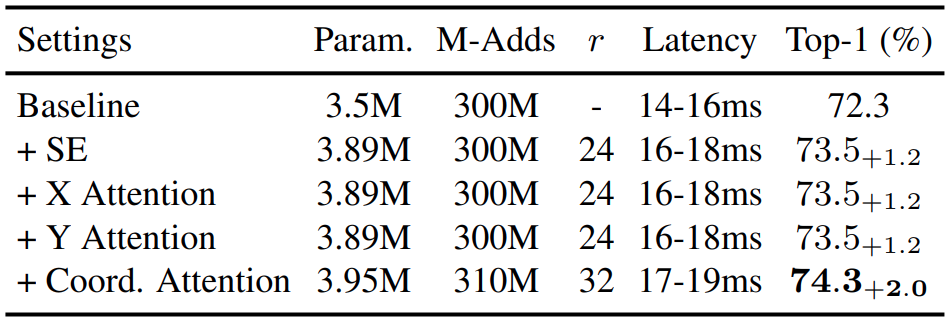
從上表可看出,任一軸向的Attribute成效都和SE Attribute近似。而當兩者同時採用時,雖然會稍微增加參數量,但可得到更好的結果.SE attention
為了驗證不同架構上的泛用性,該論文除了在MobileNetV2的架構上進行實驗外,也有將协调注意放到MobileNext來看其成效,實驗結果分別為下列2個表格:MobileNetV2 MobileNeXt
由於MobileNet本身在架構設計上有設置一個寬度參數α(Width Multiier)來調整模型架構的壓縮程度,所以上下兩組實驗會有“-1.0”、“-0.75”、“-0.5”等註記,就是α的設定值。MobileNet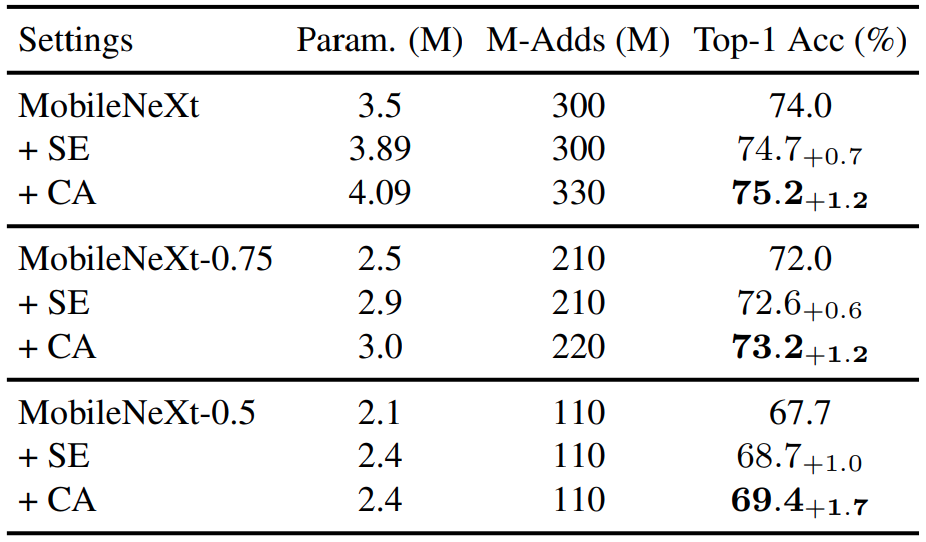
從上方2組實驗可看出,协调注意不論在沙漏瓶颈挡路或是倒置剩余挡路都比SE注意表現得更出色。SE attention
另外該論文也有對Reduce Ratio的設定進行實驗: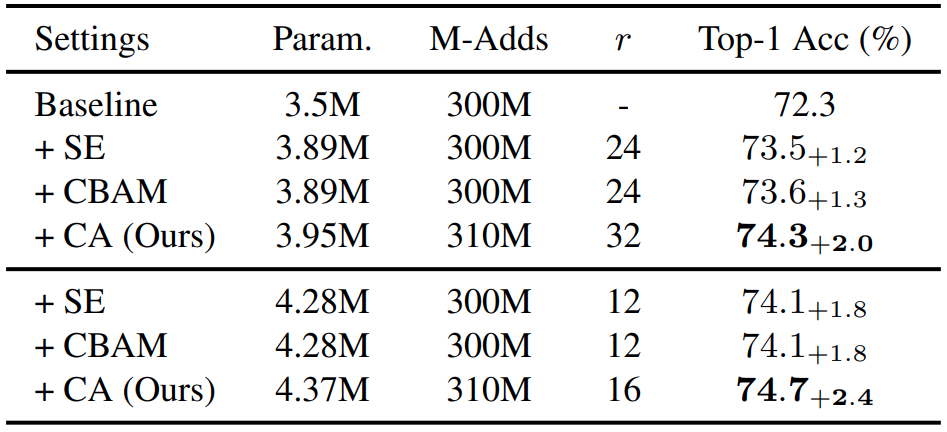
上表可看出,即便壓縮幅度減少,协调注意仍然比其他方法優秀
与其他方法的比较
以上的表格都有跟類似方法(SE Attribute、CBAM)進行比較,但除了數據的結果外,該論文也對Attribute的結果進行可視化的比較:SE attention CBAM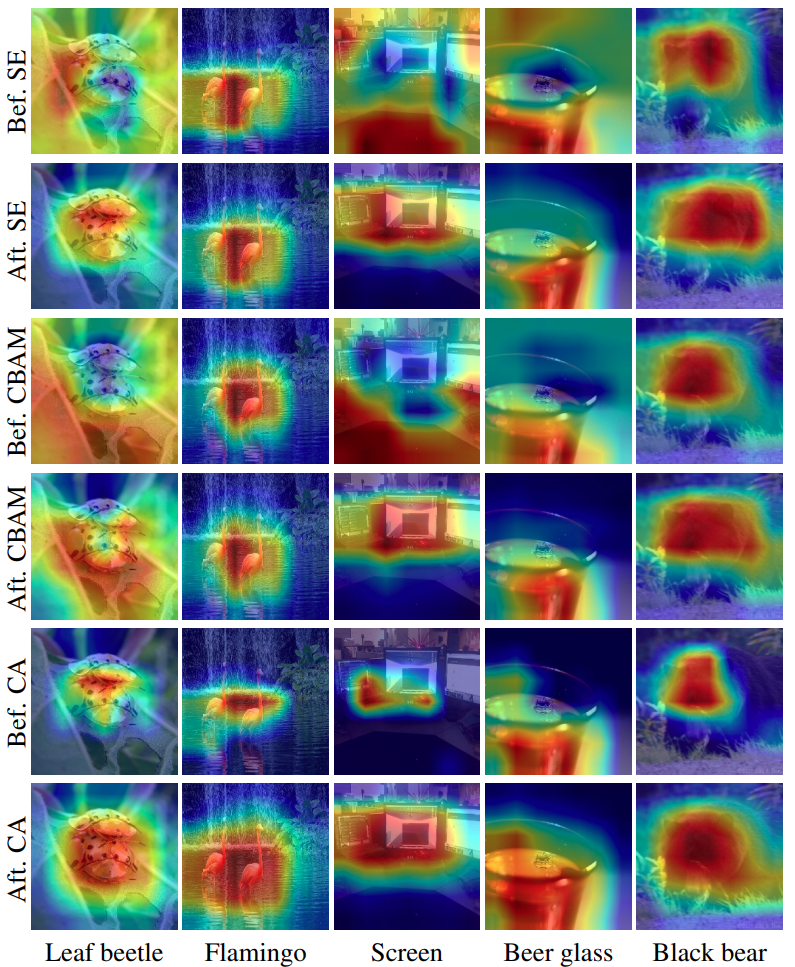
可看出第5、6個的結果在定位上更準確,原因就是COLCOLATE ACTION在做GLOBAL POOLING時,會照X、Y軸向各自做一次,所以可將Position Information保留得更完善.
另外,該論文為了進一步證明协调注意的優勢,有另外在原本就有使用SE注意的EfficientNet-b0的架構上做替換模組的實驗:SE attention EfficientNet-b0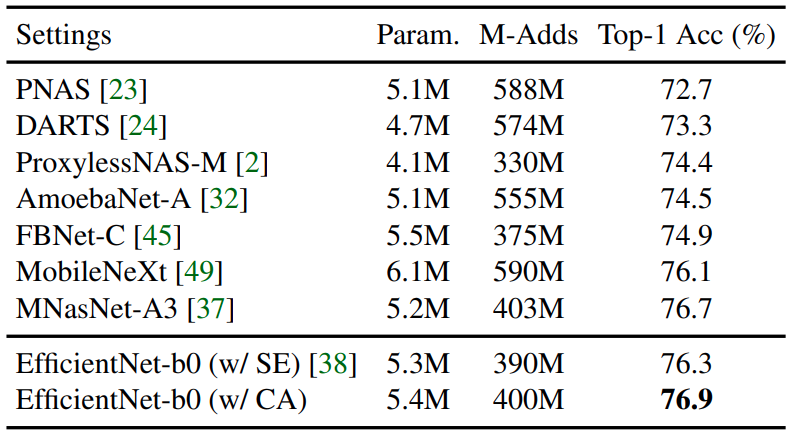
結果一樣是协调注意的效果比較好。
目标检测
至於在物件偵測的部份、Baseline是用固态硬盘精简版、依據不同資料集有些設定上的差異:SSDLite
可可:
- 批次大小:256(同步批次标准化)
- 初始学习率:0.01(余弦学习时间表)
- 迭代次数:1,600,000次
帕斯卡VOC:
- 批量:24
- 初始学习率:0.001(在160,000、200,000 Iteration除以10)
- 迭代次数:240,000次
- 权重衰退:0.9
在Coco資料集的結果如下:
不難看出採用协调注意可在增加些微參數量的情況下,得到一定幅度的精準度提昇。
另外值得注意的是,MobileNetV3、MnasNet-A1等架構其實是基於神经体系结构搜索技術所找出的模型架構,而該論文的作法可讓MobileNetV2有接近這類模型的成果。
另外在Pascal Voc資料集的結果如下: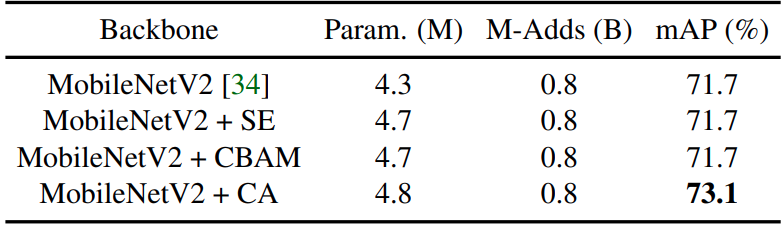
和Coco資料集的實驗結果近似,從分類任務轉換到物件辨識任務的過程,协调注意有較佳的泛用性。
语义切分
而在語意分割的任務上,也以MobileNetV2原論文採用的DeepLabV3進行實驗,但為了減少運算量有做微調:將原本aspp(ATORS空间金字塔池)的3×3卷积算子替換成沿方向可分离的卷积。其餘相關實驗設定如下:MobileNetV2 DeepLabV3
- 权重衰退:0.00004
- 输出步幅:16或8
- 扩张率:對應Output Stride分別是{6,12,18}或{12,24,36}
在Pascal Voc的結果如下:
結果與物件偵測任務上的趨勢接近,採用协调注意有提昇不少準確度。另外在Cityscapes資料集的結果如下: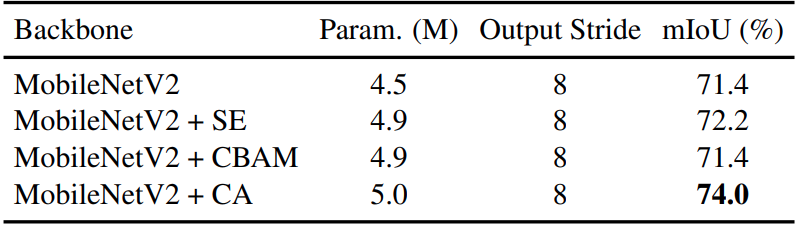
协调注意改善的幅度又更明顯。
结论
該論文針對輕量的神經網路架構提出一個新穎的Attribute作法:协调注意力。
這種方法除了繼承先前通道注意的效用外,還可同時就精準的位置資訊捕捉远程依赖关系。
而其實驗結果不論在分類、物件偵測或語意分割等任務上,都取得比其他類似的注意了,作法更好的成果。
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/19/%e8%ab%96%e6%96%87%e9%96%b1%e8%ae%80cvpr2021%e2%80%8a-%e2%80%8a%e5%8d%8f%e8%b0%83%e6%b3%a8%e6%84%8f%e5%8a%9b%ef%bc%8c%e5%ae%9e%e7%8e%b0%e9%ab%98%e6%95%88%e7%9a%84%e7%a7%bb%e5%8a%a8%e7%bd%91%e7%bb%9c/
