
问题表述:
有时我们想要找出图像中的内容,以便我们可以出于各种原因使用这些信息,例如:如果我们知道图像中有什么对象,它的范围和准确的位置,我们可以使用它来完成多项任务,比如在一张图像中对不同类型的对象进行分类,这在设计自动驾驶汽车时非常方便。近年来,我们使用深度学习模型对这样的复杂任务取得了更好的准确性。在这篇博客中,我们将看看这样一个模型,叫做YOLO(你只看一次)和它的第三个版本。
目标检测试图解决的任务是在一幅图像中检测多个目标,并通过在这些目标上绘制一个称为边界框的矩形来定位这些目标。一幅图像可以有多个对象,它们也可以有多个边界框。请看一看这张图片,以便更好地理解。
因此,我们的模型解决的任务是给我们一幅输入图像,它应该返回每个对象的边界框,这是对象和位置,第二个任务是分类,告诉它相应的类别标签,类别标签将根据问题的不同而不同。
YOLO-V3型号详情:
现在让我们来看看Yolov3机型的内部。该模型由多个部分组成,但首先要讨论的是骨干网络,它也被称为特征提取器,用于提取目标定位和分类所需的重要特征。它是一个完全卷积网络(FCN),这意味着它没有密集层或最大池层。在该型号的早期版本中,他们使用VGG和ResNet作为主干,但在Yolo V3中,他们使用名为DarkNet-53的FCN。这是一个53层的完全卷积网络,下面是相同的图像。
模型内部图像的典型输入大小为(416x416x3),该大小输入到模型中。
卷积挡路:

卷积挡路在这里意味着它在每个挡路旁边有提到的挡路大小的卷积运算,并且还定义了每个挡路的大小,如果在内核大小中看到‘3 x 3/2’,意味着步长等于2,因为我们在这里不使用最大池化运算,所以我们必须使用步长运算来减小图像大小您还会注意到,在输出列中的大小图像的大小也减少了2倍
在卷积运算之后,它被传递到BatchNormalization层,随后是LeakyRelu激活。
剩余挡路:
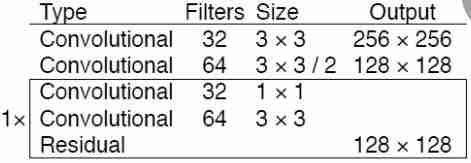
残差挡路的想法是从Resnet衍生出来的,在Resnet中,他们使用残留层,如果梯度没有提供太多信息,就允许它们跳过卷积操作。通过这样做,梯度的流动变得平滑,所有不重要的信息都被网络忽略了。
在暗网中,剩余的挡路的工作原理如下,正如你可以看到的,在一个更大的挡路内部有一些块,让我们称它为超级挡路,所以在这个超级挡路的内部有2个卷积块,分别具有不同的核大小(1,3)和滤波器数量(32,64),之后还有一个剩余的挡路。
因此,我们的超级挡路内部的输入是上图中的形状为128×128*64,在图像大小更改为128×128*64之后,它会传递给2个卷积块,因此剩余的挡路所做的就是将接收到的超级挡路(128×128*64)中的输入与第二个卷积挡路的输出连接起来,后者将输出与接收到的形状相同的张量(128×128*64)。所以它基本上是增加了快捷连接。
你可能已经注意到我们的超级挡路外面标着‘1x,2x,4x,8x’。这意味着整个巨型挡路会重复同样的次数。因为输入张量和输出张量的形状是相同的,所以我们可以毫无错误地重复该操作。
因此,一旦图像被传递到模型中,图像大小就缩小了32,因为正如您所看到的,在每个挡路之后,我们正在应用一个步长为2 5倍的卷积挡路,结果是2⁵=32。如果传递的图像形状是416x416x3,那么提取的特征形状将是13x13x1024(1024是上一个百万挡路内部的滤镜数量)。
现在我们已经成功地从主干网络中提取了特征,让我们继续前进。
3比例输出:
它通过自上而下的路径和横向连接,将低分辨率、语义强的特征与高分辨率、语义弱的特征结合在一起。
正如您在体系结构中看到的,从3个不同的大块(称为scale1,其张量形状为(52*52*256),scale2,其形状为(26*26*512),scale3,其形状为(13*13*1024))有三个输出到预测。实际上,这个想法取自另一种用于目标检测的模型–特征金字塔网络(FPN)。
模型输出公式:
到目前为止,我们已经看到了图像是如何通过网络传输的,所以现在让我们来看看模型的输出应该是什么。
直到我们将形状(416×416)的图像下采样为52×52,26×26,13×13。但是要理解这一点,让我们考虑一下输出特性挡路的13×13×1024OUTPUT,让我们看看下图。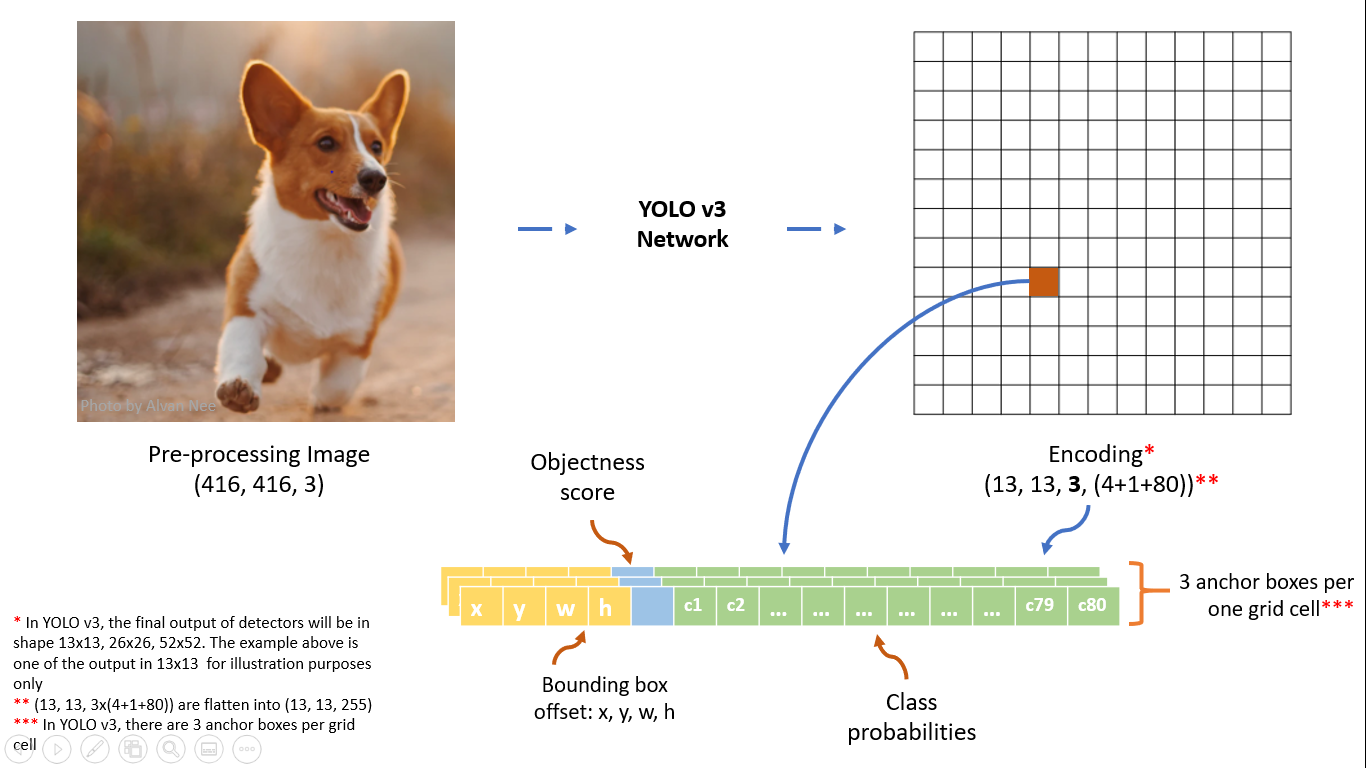
出于预测的目的,首先我们将把我们的图像分成13×13个块,在我们的情况下,如果输入图像是有形状的,那么总的块将是(416/13)*(416/13)=32*32,所以假设网格的每个挡路(用红色标记)将具有13的形状,并且将有32*32个这样的块。
因此,根据纸张,每个挡路将在每个网格单元格中包含3个锚定框,每个单元格将有85个值。让我来分析一下。
假设您正在MS-Coco数据集上进行对象检测训练,我们知道它有80组类。因此,这个数字85将分为4个边界框偏移量+1个劣势分数+80个类概率=85。
锚定箱:
锚框是一组具有一定高度和宽度的预定义边界框,其思想来源于YOLO-V2。他们在MS-Coco数据集上对边界框的维度进行k-Means聚类,以获得良好的模型先验。下图显示了我们在K的各种选择下得到的平均IOU。他们发现,k=5在召回率与模型复杂性之间提供了一个很好的值。
边界框偏移:
此单元格边框偏移量的tx和ty:x和y坐标。
tw和th:此单元格的边框的高度和宽度。
这些是对每个细胞的预测。请记住,这些不是实际的边界框坐标,它们只是偏移量、宽度和高度,我们将使用这些坐标计算实际的边界框。
客观性得分:
不可能每个锚盒中都有一个对象,因此为了捕获该信息,我们有一个二进制标签,如果对象存在于网格单元中,则该标签将为1,否则将为0。
类别概率:
现在我们已经检测到了对象,现在我们还需要这个对象的类型,如MS-Coco中的猫、狗、鸟等,因此如果我们的数据集中有80个不同的对象,那么每个类将有80个类概率值。
边界框表示法: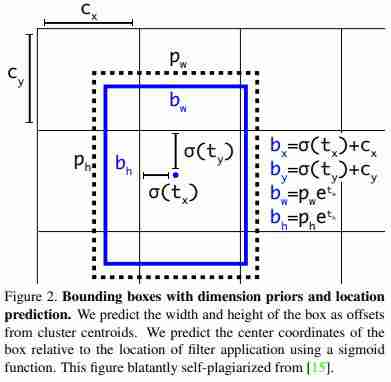
- 这里bx,by是x,y中心坐标,基本上我们将tx,ty值传递到sigmoid函数内部,将它们缩小到0-1之间,然后添加cx,cy,这是单元格网的左上角坐标。我们使用Sigmoid是因为如果预测高于1,那么边界框的中心可能会移动到另一个单元格中,这会打破YOLO背后的理论,因为如果我们假设红色方框负责预测对象,对象的中心肯定位于当前单元格中,而不是在其他任何地方。所以我们使用S字形将中心保持在单元格内部。
- bw,bh是我们的边界框的宽度和高度,如果包含对象的框的预测bx和by是(0.3,0.8),那么13 x 13特征地图上的实际宽度和高度是(13∗0.3,13∗0.8)。
- Tx,Ty,Tw,这就是我们在预测中得到的。
- Cx和Cy是栅格的左上角坐标。
- Pw和ph是盒子的锚点维度,这些预定义的锚点是通过对数据集运行K-Means聚类来获取的。
多比例输出:
在上面的解释中,我们只看到了对13*13特征图的预测。同样的概念也适用于26*26和52*52要素输出,通过在不同的网格维度上应用变换,我们实际上是在检测不同大小的对象。在13*13网格中,我们可以检测非常小的对象,而在26*26网格中,我们可以检测中等大小的对象,而对于52*52网格,我们可以检测较大的对象,通过将这些输出连接在一幅图像上,我们可以得到所有这三种对象的结果。
在每个比例下,每个栅格单元使用3个预定义锚点预测3个边界框,从而使使用的锚点总数达到9个。(锚点因比例不同而不同)。
非最大抑制
因此,对于输入图像,模型预测(52*52+26*26+13*13)*3=10647个框,这是很多的。对于撞击,我们局部地丢弃分类概率小于0.5的框,并且对同一对象周围的多个包围框使用“非最大抑制”技术。对于过滤,我们使用IOU(交集对并集)分数,它基本上计算了实际框和预测框之间有多少重叠,并通过比较特定对象的实际边界框和所有预测边界框,将其用于过滤不需要的边界框。
因此,我们需要的输出形状是13*13*425(5*(80+4+1)),其中5是锚框的数量,但是我们有13*13*1024的特征映射。因此,要将特征转换为我们想要的输出,我们只需使用1×1卷积层进行此转换。
13*13*1024(要素地图)-→(1*1*425conv)-→13*13*425(输出)
现在我们的模型完成了。现在我们可以训练它了。
谢谢
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/19/%e6%9c%ac%e9%a2%86%e5%9f%9f%e7%9a%84%e7%9b%ae%e6%a0%87%e6%a3%80%e6%b5%8b%e7%8e%b0%e7%8a%b6-yolo-v3/
