
虽然NLP的大部分成功可以归功于Transformer架构“注意力就是您所需要的一切”,但它在图像分析领域的应用仍然有限。当涉及到计算机视觉时,CNN架构仍然是最受欢迎的方法之一。在本文中,我将重点介绍使用图像补丁作为输入的Vision Transformer,以及用于图像分类的转换器体系结构的编码器部分。最后,我将展示如何使用拥抱脸界面轻松实现此架构。
内容:
- 变压器架构
- 视觉变形金刚
- Python实现
- 比较-CNN与VIT
- 前进的道路
变压器架构
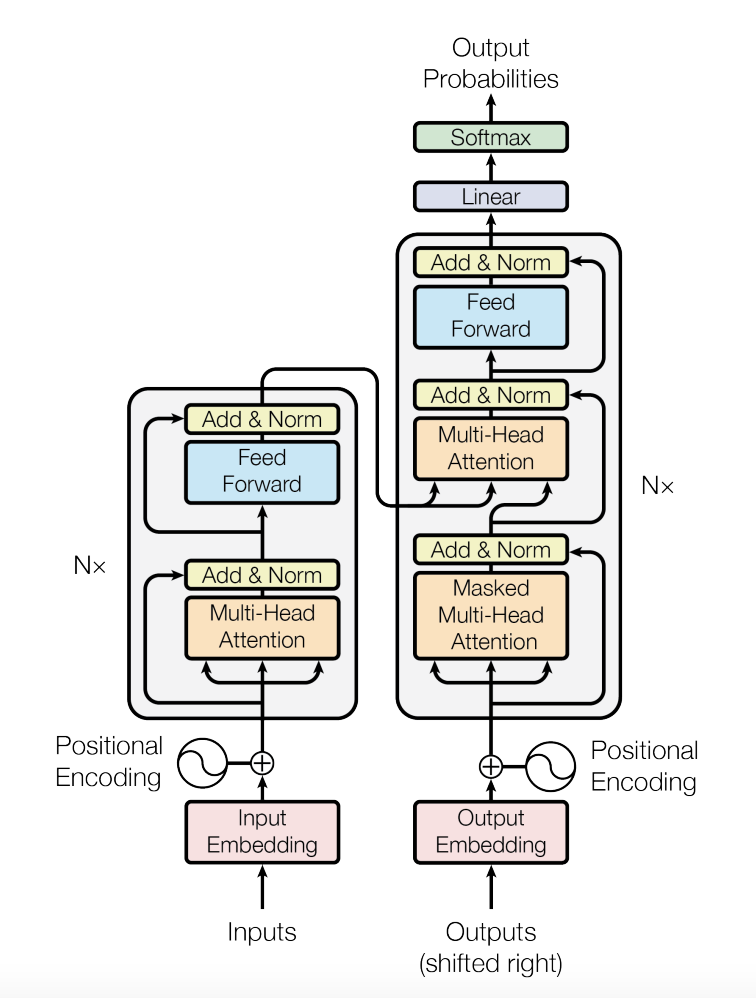
在深入研究Vision Transformer之前,我们需要了解变压器体系结构的基本概念及其工作原理。我不会更深入地研究它,但我会提到几个对理解视觉变形金刚很重要的领域。
变压器架构由编码器和解码器两部分组成。在本文中,我将重点介绍转换器的编码器部分,因为这部分将在Vision Transformer中用于图像分类任务。
编码器将嵌入的文本作为输入,将其通过6个相同的层,每个层由2个子层组成。第一子层是多头自关注机制,第二子层是全连接前馈网络。注意力机制可以被视为3个加权向量(k、q、v)的列表,每个加权向量基于输入文本中的单词的重要性被分配不同的权重。有关更多详细信息,我建议您阅读本文:
视觉转换器(VIT)
现在,我们了解了标准转换器体系结构是如何工作的,让我们看看如何将其用于图像分类任务。VIT不采用1D标记嵌入序列,而是采用位置嵌入和补丁嵌入之和,这两个位置嵌入和补丁嵌入是平坦化的2D补丁的线性投影的D维序列。视觉转换器学习在位置嵌入的相似性中对图像内的距离进行编码,即越接近的块往往具有更相似的位置嵌入。自我关注层帮助模型学习信息,甚至是从整个图像的最低层。最后,编码的输入通过MLP(多层感知)层,该层预测K个类别中的1个。
模型训练分为两步:第一步,在大数据集上对模型进行预训练,然后为了对较小的下游任务进行精调,去掉预先训练好的预测头,用D×K前馈层代替。
Python实现
现在我们了解了视觉转换器的工作原理,让我们使用流行的拥抱脸界面来实现用于图像分类的基本的预先训练的VIT模型。
from transformers import ViTFeatureExtractor, ViTForImageClassification
from PIL import Image
import requests上述代码也可以从拥抱脸网站轻松找到:
上面的代码加载VIT特征提取器和VIT图像分类函数,以使用Google开源的预先训练的模型。VIT特征提取器将图像作为输入,并将其转换为位置嵌入的16×16块,以使其适合于将其馈送到模型中。在图像分辨率为224×224的ImageNet数据集上预先训练的“Google/Vit-base-patch16-224”模型被用来预测1000个ImageNet类中的一个。
比较-CNN与VIT
虽然Vision Transform的表现令人难以置信,但它的大部分成功都要归功于大规模的预训练数据集。作者声称,在一个小的数据集上,CNN的表现仍然比VIT好得多,但随着训练数据样本的增加,VIT的表现优于所有其他最先进的模型。
前进的道路
现在,由于图像分类变换模型的存在,可以对自监督训练方法进行更多的探索。在序列到序列变换模型中,还可以开发一种基于变换的目标检测和图像分割任务。最后,进一步扩展VIT可以减少微调时间并提高性能。
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/20/%e8%a7%86%e8%a7%89%e5%8f%98%e5%bd%a2%e9%87%91%e5%88%9a%ef%bc%9a%e5%bd%b1%e5%83%8f%e4%b8%ad%e7%9a%84%e6%b3%a8%e6%84%8f%e5%8a%9b/
