
早期的黑暗知识
早期的目标检测(2000年以前)并没有遵循统一的检测理念。当时的探测器通常是基于低级和中级视觉设计的。
组件、形状和边缘
一些早期的研究人员将物体检测定义为物体成分、形状和轮廓之间的相似性度量。尽管最初的结果很有希望,但在更复杂的检测问题上,事情并没有很好地进行。
因此,基于机器学习的检测方法开始蓬勃发展。基于机器学习的检测经历了多个阶段,包括外观统计模型(1998年前)、小波特征表示(1998-2005)和基于梯度的表示(2005-2012)。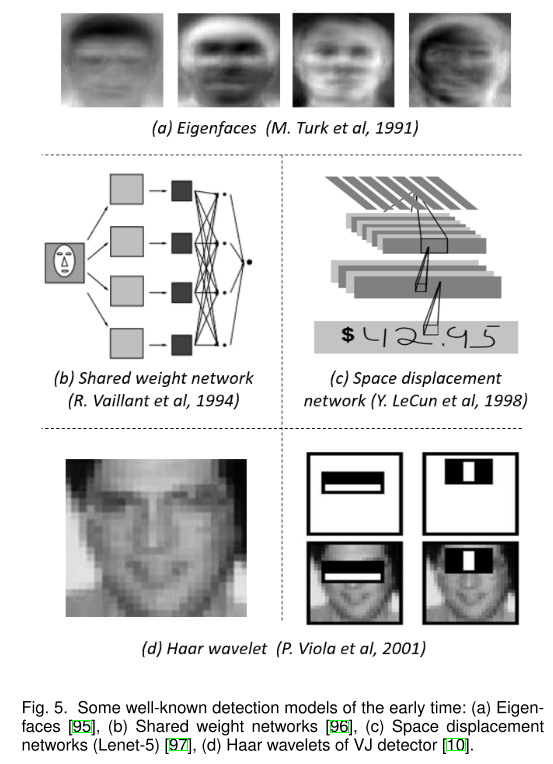
建立对象的统计模型,如图5(A)中所示的特征脸,是对象检测历史上基于学习的方法的第一波。与当时基于规则或基于模板的方法相比,统计模型通过从数据中学习特定于任务的知识,更好地提供了对象外观的整体描述。
从2000年开始,小波特征变换开始主导视觉识别和目标检测。这组方法的本质是通过将图像从像素变换为一组小波系数来学习。在这些方法中,Haar小波由于其计算效率高,在许多目标检测任务中得到了广泛的应用。图5(D)示出了由用于人脸的主播检测器学习的一组Haar小波基。
早期用于物体检测的CNN
使用CNN探测物体的历史可以追溯到20世纪90年代,Y.LeCun等人。(图5(B)-(C))在当时作出了很大贡献。由于计算资源的限制,当时的CNN模型比今天的模型要小得多,也浅得多。尽管如此,在早期基于CNN的检测模型中,计算效率仍然被认为是难以破解的难题之一。
多尺度探测的技术进展
具有“不同大小”和“不同纵横比”的目标的多尺度检测是目标检测的主要技术挑战之一。
特色金字塔+滑动窗口(2014年前)
像VJ检测器和HOG检测器这样的早期检测模型被专门设计为通过简单地构建特征金字塔并在其上滑动固定大小的检测窗口来检测具有“固定长宽比”的对象(例如,人脸和直立行人)。当时没有考虑“各种宽高比”的检测。
对于像Pascal VOC那样具有更复杂外观的对象的检测,“混合模型”是当时最好的解决方案之一,通过训练多个模型来检测具有不同长宽比的对象。除此之外,基于样本的检测通过为训练集的每个对象实例(样本)训练单个模型提供了另一种解决方案。
使用对象建议进行检测(2010-2015)
对象建议指的是一组与类别无关的候选框,它们可能包含任何对象。利用对象建议进行检测有助于避免在图像上进行穷尽的滑动窗口搜索。
目标建议检测算法应满足以下三个要求:1)高召回率,2)高定位精度,3)在前两个要求的基础上,提高准确率,减少处理时间。现代的提案检测方法可以分为三类:1)分段分组方法,2)窗口计分方法,3)基于神经网络的方法。
早期提出的检测方法遵循自下而上的检测理念,深受视觉显著性检测的影响。后来,研究人员开始转向低级视觉(例如,边缘检测)和更仔细的手工制作技能,以改善候选盒的本地化。2014年后,随着深度CNN在视觉识别领域的普及,自上而下、基于学习的方法在这个问题上开始显示出更多的优势。从那时起,对象建议检测已经从自下而上的视觉发展到“过度拟合到一组特定的对象类”,检测器和建议生成器之间的区别正在变得模糊。
深度回归(2013-2016)
近年来,随着GPU计算能力的提高,人们处理多尺度检测的方式变得越来越直截了当和蛮力。深度回归的思想是基于深度学习特征直接预测包围盒的坐标。该算法简单易行,但定位精度不高,特别是对于一些小目标。
多参考/多分辨率检测(2015年后)
多参考检测是目前最流行的多尺度目标检测框架。其主要思想是预定义一组参考框(也称为锚框)在图像的不同位置具有不同的大小和纵横比,然后基于这些参考预测检测框。
过去两年的另一种流行技术是多分辨率检测,即通过在网络的不同层检测不同尺度的对象。由于CNN在正向传播过程中自然形成一个特征金字塔,因此更容易探测到较深层的较大物体和较浅层的较小物体。
多参考和多分辨率检测现在已经成为最先进的目标检测系统中的两个基本构件。
包围盒回归的技术进展
包围盒回归是目标检测中的一项重要技术。它的目的是根据初始方案或锚定框改进预测边界框的位置。
不含BB回归(2008年前)
早期的检测方法如VJ检测器和HOG检测器大多不使用BB回归,通常直接将滑动窗口作为检测结果。为了获得物体的准确位置,研究人员别无选择,只能建造一个非常密集的金字塔,并在每个位置密集地滑动探测器。
从BB到BB(2008-2013)
BB回归第一次被引入目标检测系统是在数字信号处理器中作为后处理的挡路。该方法基于对象假设的完整配置来预测边界框,并将该过程表示为线性最小二乘回归问题。这种方法在帕斯卡标准下的检测中产生了显著的改进。
从功能到BB(2013年后)
在2015年推出速度更快的RCNN后,BB回归不再作为单独的后处理挡路,而是与检测器融合,采用端到端的方式进行训练。同时,BB回归已发展为基于CNN特征直接预测BB。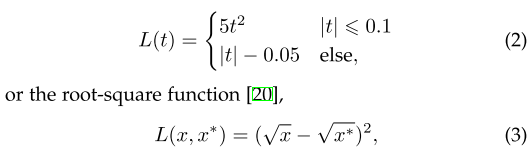
为了获得更稳健的预测,通常使用平滑L1函数作为其回归损失,它比DPM中使用的最小二乘损失对异常值具有更强的鲁棒性。一些研究人员还选择对坐标进行归一化,以获得更稳健的结果。
语境启动的技术进展
视觉对象通常嵌入到与周围环境的典型上下文中。我们的大脑利用物体和环境之间的联系来促进视觉感知和认知。上下文启动长期以来一直被用来改进检测。
利用本地上下文进行检测
局部上下文是指要检测的对象周围区域中的视觉信息。人们很早就认识到,局部上下文有助于改进对象检测。
利用全局上下文进行检测
全局上下文利用场景配置作为对象检测的附加信息源。对于早期的对象检测器,集成全局上下文的一种常见方式是集成组成场景的元素的统计摘要,如Gist。现代基于深度学习的检测器有两种方法:(1)利用较大的接受域(甚至比输入图像还要大);(2)利用CNN特征的全局汇集操作。
情景互动
语境交互性是指通过视觉元素的交互作用所传达的信息,如约束和依赖关系。对于大多数对象检测器,对象实例是单独检测和识别的,而不利用它们之间的关系。最近的一些研究表明,可以通过考虑上下文交互来改进现代目标检测器。最近的一些改进可以分为两类:(1)探索单个对象之间的关系;(2)探索对象和场景之间的依赖关系的建模。
非最大值抑制的技术进展
由于相邻窗口通常具有相似的检测分数,因此本文使用非最大值抑制作为后处理步骤,以去除复制的边界框并获得最终检测结果。在过去的20年中,网络管理系统逐渐发展成以下三组方法:1)贪婪选择,2)包围盒聚合,3)学习网络管理系统。
贪婪选择
贪婪选择是一种老式但最流行的NMS目标检测方式。该过程背后的思想简单而直观:对于一组重叠检测,选择具有最大检测分数的边界框,同时根据预定义的重叠阈值(例如0.5)移除其相邻框。以贪婪的方式迭代地执行上述处理。虽然贪婪选择现在已经成为网管系统事实上的方法,但它仍有一些改进的空间。
BB聚集
BB聚合是NMS的另一组技术,其思想是将多个重叠的边界框组合或聚类到一个最终检测中。这种方法的优点是它充分考虑了对象之间的关系和它们的空间布局。
学习网管系统
最近受到广泛关注的一组NMS改进正在学习。其主要思想是将网管系统看作是一个过滤,用于对所有原始检测进行重新评分,并以端到端的方式将网管系统作为网络的一部分进行训练。与传统的手工NMS方法相比,这些方法在改善遮挡和密集目标检测方面显示了良好的效果。
硬质负压开采的技术进展
目标检测器的训练本质上是一个不平衡的数据学习问题。在基于滑动窗口的检测器的情况下,背景和对象之间的不平衡可能与每个对象的10个⁴∼10⁵背景窗口一样极端。现代检测数据集要求对目标的纵横比进行预测,进一步增加背景数据将不利于训练,因为极大的不平衡比高达10⁶∼10⁷。在这种情况下,使用所有容易的负片会使学习过程不堪重负。硬负挖掘(HNM)旨在解决训练过程中数据不平衡的问题。
引导
目标检测中的Bootstrap是指从一小部分背景样本开始训练,然后在训练过程中迭代添加新的错误分类背景的一组训练技术。在早期的目标检测器中,最初引入Bootstrap的目的是为了减少对数百万个背景样本的训练计算量。后来,它成为解决数据不平衡问题的DPM和HOG检测器的标准训练技术。
基于深度学习的检测器中的HNM
在深度学习时代后期,由于计算能力的提高,Bootstrap在2014-2016年间的目标检测中很快就被抛弃了。为了缓解训练期间的数据不平衡问题,像FASTER RCNN和YOLO这样的检测器只需在正窗口和负窗口之间平衡权重。然而,研究人员后来注意到,权重均衡并不能完全解决数据不平衡的问题。为此,2016年后,Bootstrap重新引入基于深度学习的检测器。另一种改进是设计新的损失函数,通过重塑标准交叉熵损失,使其更多地关注硬的、分类错误的例子。
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/22/%e2%80%8a-%e2%80%8a%e7%9b%ae%e6%a0%87%e6%a3%80%e6%b5%8b20%e5%b9%b4%e8%ae%ba%e6%96%87%e9%98%85%e8%af%bb%e7%bb%bc%e8%bf%b0%e4%ba%94/
