
FairMOT已经发布了几个月,但它仍然是我以前见过的最引人注目的多目标跟踪模型。这种令人印象深刻的神经网络模型认识到了当前基于检测的目标跟踪模型中存在的最普遍的弱点,即重新识别在很大程度上依赖于检测。然而,作为一个专注于计算机视觉应用的硕士研究生,我很好奇它在应用领域是如何工作的,比如fps,mota,motp和idf1。
在FairMOT模型中推荐HRnet作为FairMOT的主干,其编码和解码对象信息的性能可靠。[以下是GTX1080Ti的HRnet->MOT17/20培训和MOT16测试的执行情况]。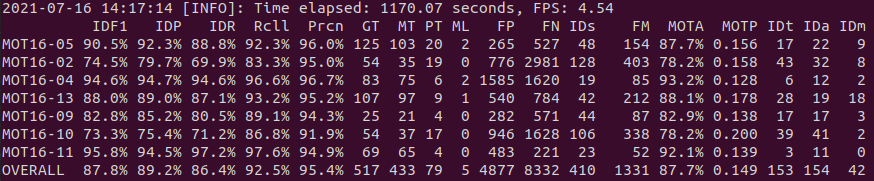
与MOT16的MOT挑战赛结果相比,IDF1、MOTA、MOTP、IdP、Prcn等指标远远超出了最好的结果。这里值得一提的是,在我的例子中,MOTP是使用py-motmetrics计算的,这意味着它遵循MOTP定义中的原始含义,即观测对象之间的平均距离,所以越低越好。py-motmetrics
然而,HRnet->fps有一个弱点。如果相机中的fps达到24 Hz,大约4 Hz fps就会远离应用。在这种情况下,HRNet中的处理速率不会跟随摄像机速率,从而遗漏目标信息,导致在真实场景中跟踪性能很差。
此外,说到训练细节和概率,由于GPU的限制,我不能在更大的数据集和更大的批量上进行实验测试,HRnet在3到4个纪元左右很早就超负荷了,这是很糟糕的。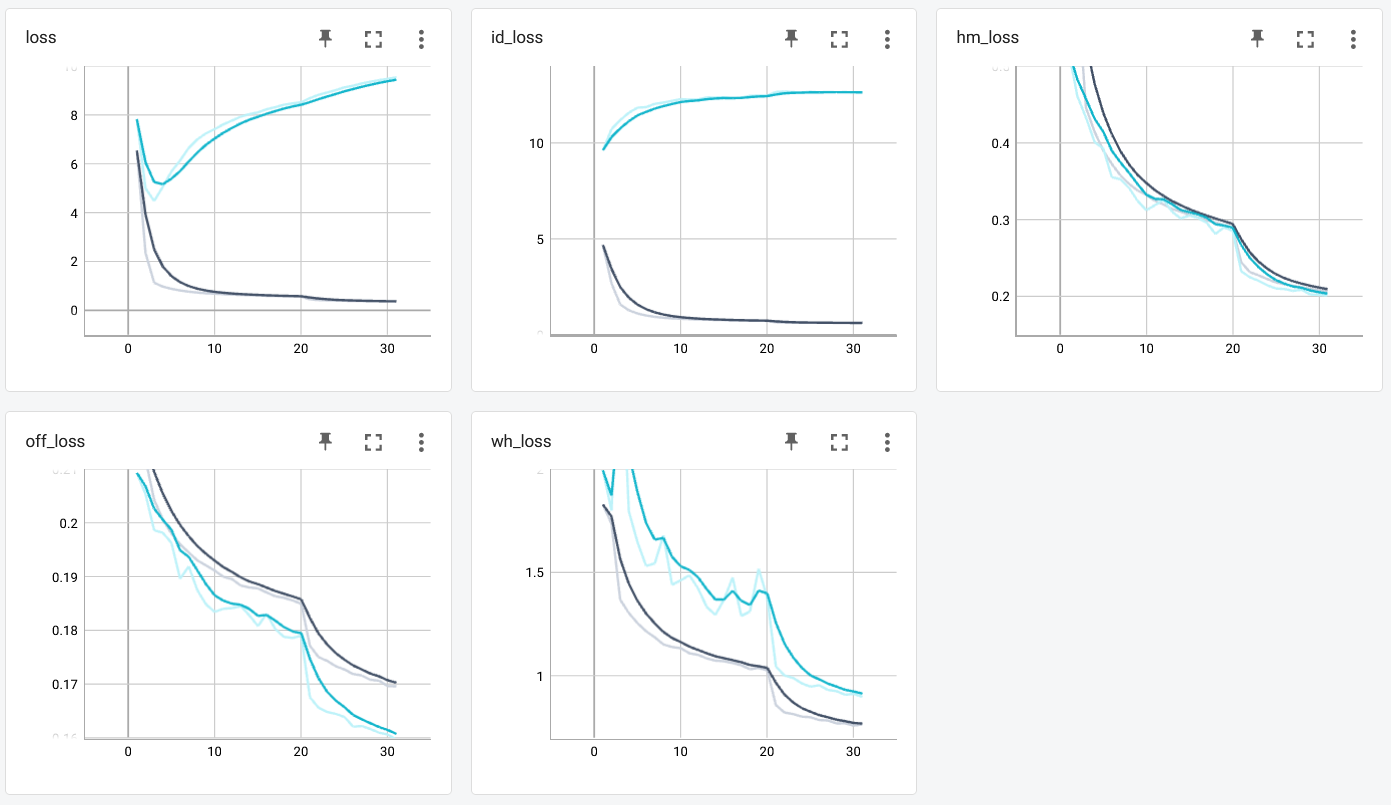
然而,如果你说让我们使用Val损失最小的纪元,那么不幸的是,你错了。这里指的是我在模拟后在FairMOT中分析的一件事,那就是ID丢失在这里看起来有点噪音。下面是我从上面的培训信息中发现的信息。
A.过度拟合:HRnet前期受ID丢失影响较大,4、5个时代后会向上拖累。
B.检测:HM损耗、OFF损耗和WH损耗保证了HRNet中BBOX的准确预测。具体而言,小的hm(热图)损失意味着HRnet能够以小的误差定位目标的位置;小的OFF损失意味着BBOX的位置与地面实际稍有偏离,从而使预测的BBOX能够完美地包含观测对象;小的wh损失意味着HRnet预测的BBOX的宽度和长度几乎是正确的。总而言之,这三个损失保证了MOTP在FairMOT模型中相当完美,因为这种情况下的BBOX预测将接近实际情况->良好的欠条。
C.Re-ID:ID损失较大,一开始看起来过于合适,但整个ID相关指标看起来相当不错,这在这里很奇怪。然而,在对跟踪ID进行分析后,这里有一些站在这种情况背后的线索。
c.1数据处理阶段的ID采集->虽然使用了交叉熵来计算ID损失,但与固定类别标签数的分类任务不同,ID的数量会随着数据集的增加而增加。通常,ID的数量高达2260或7760个,这远远超过ImageNet中的分类数量,这一特性会给ID丢失带来压力。
C.2ID唯一性->在MOT15/16/17/20中,这里有一个特定人员的唯一ID。在分类中,我们可以为所有人调用标签1,而在跟踪中,我们不能。这项财产给身份证遗失带来了一些麻烦。例如,Video1中的Michael被标记为ID 1,他只在几帧后出现,然后当Michael在Video1中消失后,此ID将不能再使用,因为不会再有另一个人看起来与Michael相同。换句话说,这里并不是两个外表完全相同的人,所以模型在验证时很难精确地预测被观测对象的ID,这使得这种情况下的CrossEntropy变得非常困难。然而,在分类中,模型可以很容易地将人类的外表与其他类型区分开来,这使得交叉熵在这种情况下变得非常容易。因此,ID唯一性很容易成为GPU中的垃圾存储。
C.3FairMOT中的卡尔曼过滤->福尔曼过滤确保ID连接正常。即使HRnet不能准确预测正确的身份证作为基本事实,卡尔曼过滤也保证唯一的身份证能够与一个人保持一致。
通过考虑C.1&C.2和C.3,交叉熵丢失可以在某种程度上表示身份丢失,但它并不能准确地表示公平多对象跟踪,因为有一些问题需要考虑。因此,作为ID丢失的交叉熵意义较小。
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/22/fairmot%e4%b8%ad%e7%9a%84hrnet%e5%88%86%e6%9e%90/
