
FairMOT是一個新型的One-Stage模型,並且使用Re-ID讓物件追蹤更加準確,在MOT挑战赛有絕佳表現,接著我們就來看看他是怎麼辦到的
CVPR 2020
引言
近年來的多目標檢測大多是以Tracking by Detect的方式進行,分成兩個步驟,先用目標檢測的模型找出所有物件,然後再對找出來的物件擷取特徵,以利後面追蹤他。接著就有人使用面具R-cnn添加Re-ID分支,模型執行到投资回报時進入Re-ID,這麼做跟两阶段模型比起來大幅減少執行時間,卻也喪失精準度,因為投资回报不是物件的一個明確範圍
锚定造成的不公平
現存的Track R-cnn和JDE模型使用基于锚的偵測物件,但基于锚的架構不適合使用Re-ID
在Track R-cnn中,由於是採用先找到包围盒而後去在Box中取出Re-ID,這會讓模型專注於找出精準的bbox忽略了Re-ID萃取的質量,這種先檢測後Re-ID的架構使Re-ID無法公平的學習
基于大多數锚点的的方式是,找出物件附近的區域,然後萃取特徵,但當很多物件距離很近時,就有可能不小心萃取到其它物件的特徵,或是範圍過大而萃取到被景特徵
此時論文只萃取中心點的特徵效果會更好
紫色的點和紅測的點特徵都可以取出,但如果使用锚的方式,會不小心拿到別人的特徵
鄰近的锚定訓練時,有可能抓到同一個物件,這會給訓練帶來一些不確定性。加上物件偵測的萃取細緻程度不夠,那些不夠細緻的要素地图拿來當Re-ID辨認用的要素地图,準確度不足
特征造成的不公平
通常目標檢測和Re-ID共享了大部分的特徵,但我們知道目標檢測需要的深層特徵,才能辨別這到底是甚麼物件,Re-ID需要的僅是淺層特徵,在同一種物件不同實例間辨別
我們可以將多層特徵融合再一起,然後分成兩的分支,一個為檢測分支,另一個為重新ID分支,兩個分支像多層融合特徵中各取所需,融合具有不同感受野的層的特徵的多層融合也提高了處理對象尺度變化的能力
由特征尺寸引起的不公平
以往的Re-ID都會萃取到很高維度的特徵,這雖然對辨識精準度有幫助,但其實低維度特徵對Re-ID會更適合,理由如下
FairMOT概述
我們提出的模型FairMOT來解決三個公平問題,他不同於以往模型的先檢測後重新ID的方式,同時重視這兩項工作
- 面對以前单级所遇到的問題,這些問題以往常被忽視
- 使用无锚点的公平框架,且效能優於之前的方法
- 針對超大資料集提出自监督学习
除了在MOT 15、16、17、20都達到最好的表現,單個GPU腾讯通2080 Ti上的速度更可高達30 FPS
相关工作
簡介一下使用Deep Learning和Deep Learning的方法,以及跟我們的方法比較
非深度学习MOT方法
最知名的Sort和欠条追踪器,Sort的方法是使用卡尔曼过滤預測這個物件在下一幀上的位子,利用匈牙利演算法把這兩幀的物件匹配,如果這兩個物件的Cost最小,就把這兩個物件匹配在一起,賦予相同ID
欠条跟踪器超直觀,先用像是YOLO檢測器把所有物件的框框的找出來,兩幀的物件匹配方式,哪兩個框框距離最近,有最大欠条就匹配起來,但這兩中方法在物件大量重疊時,結果會大爆爛
深度学习MOT方法
像上面講過的跟踪的检测就是屬於两阶段的方法,好處是可以選擇檢測最好的模型和匹配最好的模型,壞處是因為兩個步驟所以速度慢方法
而One-Stage網路雖然比較快,但模型匹配精準度往往輸給两阶段,原因是在One-Stage中的Re-ID沒有受到公平對待,此篇論文提出的FairMOT模型在兩個任務之間取得平衡,速度與精準度都明顯提高
FAIRMOT
架構圖
主干网络
使用Resnet-34作為骨架,在精準度與速度之間取得平衡,深层聚合這項技術也有融合在其中,加強深層網路間的融合,如上圖所示,他具有更多從低级功能到高级功能的跳过连接,結構相似於功能金字塔网络。其中所有的上採樣層都可以換成可变形卷积,根據物件的大小動態調整視野域Deep Layer Aggregation deformable convolution
經由上述改動生成的模块命名為DLA-34,輸入圖片大小H x W,輸出維度C x(H/4)x(W/4)
检测科
檢測分支是基於CenterNet進行改造,也可使用其它无锚的方法、检测的三個平行的Head分別計算热图、盒偏移量和中心偏移量、分別對dla-34的輸出套用3 x 3卷积(带256个通道)CenterNet 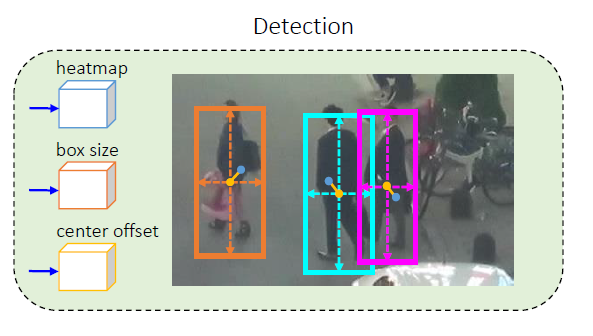
這個Head負責估計物件中心點的位子,維度為1 x高x宽,地面实况的計算如下
由此可知中心點座標為x相加除以2和y相加除以2,但要考慮Backbone的Strike是4,所以做標還要除以4,變成以下這樣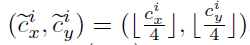
接著我們希望中心的點的值在訓練的時後呈現1、中心點旁邊的值以指數方式遞減,由下列的式子表達.Mxy是地貌地图應該要長得樣子
接著就可以算损失函数、使用的是焦点损失
M Head是估計出來的值,α和β是焦损的可調參數
Size Head用來估計物件的寬和高,长方体偏移用來估計物件實際的中心點位子偏移,因為Stride 4的關係,利用长方体偏移找出真正的中心點座標
以下為Size Head的地面真相,很直觀,相減找出寬高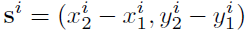
长方体偏移算法如下,一個有無條件捨去,一個沒有,兩個相減
最後可以得出這兩個分支机构的丢失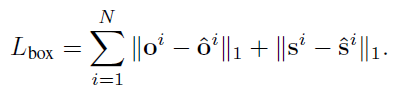
o Head和的Head是估計結過,使用L1丢失
重新标识分支机构
這個分支的目標,是要讓模型能夠區分不同對像,理想上,同目標運算出來的值要越相近越好,不同目標經過運算出來的值要差越多越好
維度為128x高x宽,意思是每個像素都有128通道
重新标识丢失
總共有k的类和N個物件,預測出來每個类的特徵如下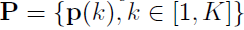
损失計算方式為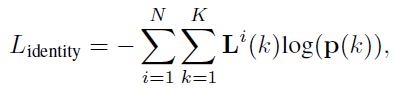
L(K)是Ground Truth类的One-Hot的結果
培训FairMOT
將上述所有的Loss加起來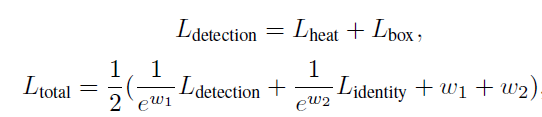
ω1和ω2是平衡這兩個任務的可學習參數
訓練時具體來說,就是給模型很多個物件和他們的ID,Box的位子這些資訊供模型訓練,還有做一些增强,並且先行用CrowdHuman訓練,最後用MOT的資料Finetune
在线推理
說明模型推理階段以及如何進行檢測和重新ID特徵的關聯
網路輸入圖片大小為1088×608,就跟JDE模型相同。我們使用网管找尋高於閥值的那些關鍵點,接著估計框框大小和偏移量
首先,將第一幀的物件外觀結果記起來,到了第二幀,把第二幀檢測出來的物件外觀與第一幀被記起來的那些外觀進行匹配,使用Cosine Distance比對外觀差距,使用Bartite比對檢測框位子,使那些匹配的物件賦予同一個ID,也有使用卡尔曼过滤來預測當前幀的軌跡,這能防止過遠的物件匹配在一起,這些重新ID都會隨著時間更新,以應對角度的改變
实验
這個結果是把萃取重新ID的結構替換,看哪一種方式比較好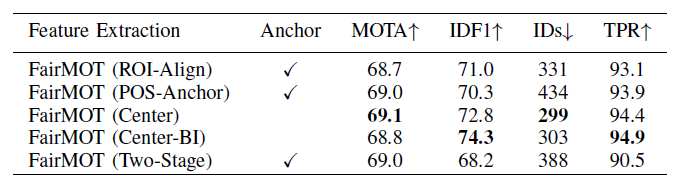
他們也有把Backbone替換,結論是DLA-34在追蹤任務上比ResNet-34還要優秀,而且ResNet-50竟然只有比ResNet-34還一點點而已,可見得重點不是在模型深度,凸顯特徵融合的重要性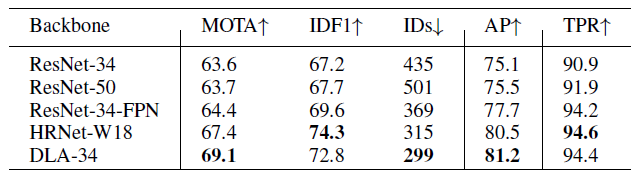
底下的RENET-34-DET是只有列车检测沒有列车Re-ID,這對真阳性率根本是一場災難,但是沒有訓練Re-ID的模型在檢測任務上分數反而比較高,這實驗說明检测和Re-ID兩個存在衝突關係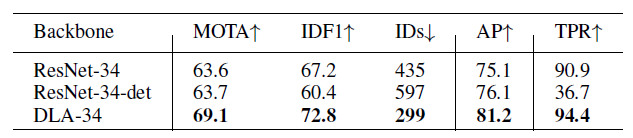
接下來他們做Re-ID維度的實驗,512維的辨識能力最佳,證明高維度可以帶來高辨識能力,但隨著維度遞減,MOTA竟然升高,這主要是檢測衝突導致,維度下降時,檢測的得分AP會上升,最後他們取用64維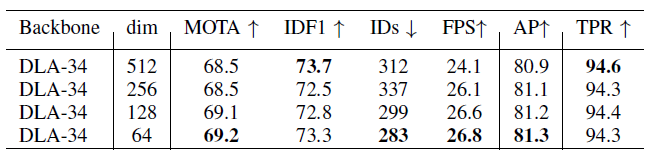
他們還有把物件連結的方法做比較,當物件被遮擋時,Re-ID變不可靠,就得依賴Box IOU和卡尔曼过滤做一些位子上的預測來補足
自我监督学习、不清楚他怎麼做的,要去看看他給的参考、論文的原文是這樣說的reference
我们将数据集中的每个对象实例视为单独的类,将同一对象的不同转换视为同一类中的实例。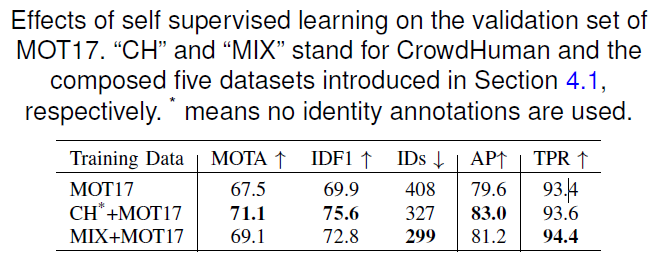
最後顯示在每個移动电话挑战赛上的結果
下面這張熱影像能讓我們知道无锚点的優勢,和這篇論文的重新ID策略確實有顯著的效果
底下是一些MOT視覺化的結果
结论
這篇論文主打把以往的兩步驟追蹤變成單一個一步驟,先是提出了Detect會影響Re-ID的質量,所以把他們變成平行的Branch,但我有個問題,如果不先找出物件,Re-ID要怎麼知道去哪裡抓取Feature?詳細可能還要去看看程式碼
現在行人偵測都把FairMOT當成基准,因為他實在太強了,不但精準還能在腾讯通2080Ti(4萬台幣)這種普通顯示卡做到实时(30FPS),現在說精準度比FairMOT還要高的模型,使用V100(40萬台幣)來執行,FPS也才10幾,希望他這麼厲害的模型能夠對我的碩士論文有幫助
代码
這是官方的程式碼喔~
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/22/fairmot%e8%a9%b3%e7%b4%b0%e4%bb%8b%e7%b4%b9/
