
一段时间前,我正在研究一个对象检测问题,当时我了解到CNN关于对象检测问题的最先进的架构,称为“Mobilenet”。“Mobilenet”
Mobilenet是一种极其轻量级的模型,主要用于在移动设备上实现计算机视觉。但是这个CNN架构的特别之处在于一种被称为可分离卷积层的东西。这些可分离的卷积可以将卷积层中的可训练参数的数量减少高达90%。
最主要的是,两种类型的可分离卷积在社区中相当流行。
·空间可分离卷积·纵向可分离卷积
空间可分离卷积
在开始讨论空间上可分离的卷积之前,我们应该首先理解“空间”的一般含义。
任何在空间上与任何其他物体相关的东西都意味着这两个物体的位置起着重要的作用。想一想任何一幅图像,这幅图像中的像素彼此之间存在空间关系。如果我在这里和那里交换一些像素,那么图像将失去其意义。另外,如果我将此图像转换为数组,然后展平该数组,则该图像中的空间信息将丢失。(这种现象被称为空间损失,这就是人们首先提出卷积分层的原因)。
空间卷积将核的尺寸旋转,然后在图像上逐个执行卷积运算。假设我们有图像,而不是应用任何大小为3✖3的内核,我们将该内核分成大小为3✖1和1✖3的2个内核,然后应用卷积。
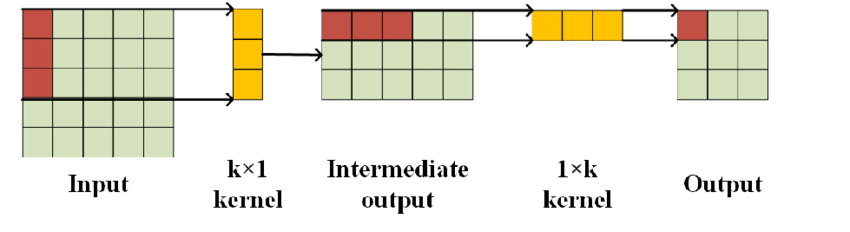
通过这样做,我们可以将卷积的数量从9个减少到6个,从而降低费用,但这种技术在大多数情况下并不是很有用,原因是这些类型的卷积不能捕获复杂的特征
沿深度可分的卷积
这些类型的卷积是移动网络体系结构科学家感兴趣的主要领域。mobile net
让我们想一想任何大小为7✖7✖3的图像和大小为3✖3✖1的内核,如果我们要将通道数从3增加到2 5 6,那么我们通常在图像上使用2 5 6个大小为3✖3的内核,并将它们堆叠在一起来创建维度为5✖5✖256的特征地图。但是在深度卷积中,我们把它分成两部分。
首先,我们通过保持通道不变来缩小图像的高度和宽度,然后通过保持高度和宽度不变来增加通道的数量
第1部分-恒定通道
让我们仅以上述示例为例,我们有一个大小为7✖7✖3的图像。我们将使用大小为3✖3✖1的3个核进行卷积。它将为我们提供大小为5✖5✖3的要素地图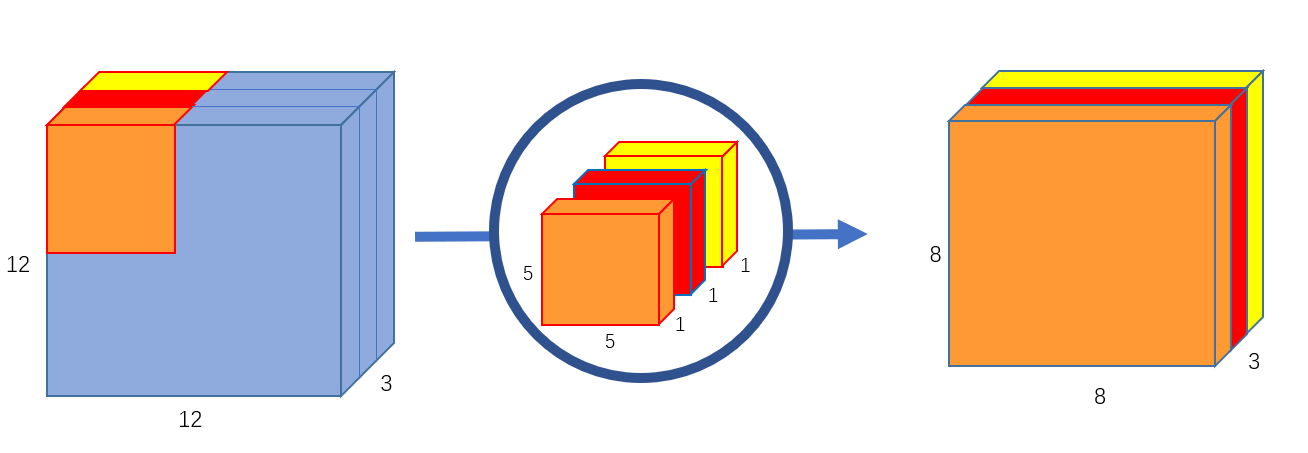
第2部分-固定高度和宽度
现在我们将把大小为1✖1的2 5 6个核函数与我们在第一部分中得到的大小为5✖5✖3的中间特征图进行卷积。它将给出大小为5✖5✖256的特征映射,因为1个✖1内核不会减小输入的大小。
你一定在想我们为什么需要这个,我们只需要用2 5 6个大小为3✖3的内核就可以很容易地一步实现上面的特征图,原因就是效率。让我们计算一下我们的计算机在这两种情况下必须做的乘法次数。
在简单卷积中,乘法次数为7*7*3*3*3*256,等于338,688。现在,在深度可分离卷积中,恒定通道部分的乘法总数为7*7*3*3*3*3,恒定高度和宽度部分的乘法总数为5*5*3*1*1*256。因此,深度卷积的总乘法为23169次,仅为上述方法的6.84%。
这里要记住的一件事是,这些可分离的技术在完全连接的层上不起作用。此外,在这里,我们仅在一个卷积中将通道数从3增加到256。在实际场景中,我们逐渐增加了通道数。因此,这些技术可能会也可能不会在计算中给出如此惊人的减少(在这里,它给出了100-6.84=93.16%的减少)
参考文献
- https://towardsdatascience.com/a-basic-introduction-to-separable-convolutions-b99ec3102728
- https://towardsdatascience.com/a-comprehensive-introduction-to-different-types-of-convolutions-in-deep-learning-669281e58215
- https://paperswithcode.com/method/depthwise-separable-convolution
- https://paperswithcode.com/method/mobilenetv1
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/24/%e5%8f%af%e5%88%86%e7%a6%bb%e5%8d%b7%e7%a7%af%e7%9a%84%e5%8d%95%e7%8b%ac%e6%8c%87%e5%8d%97-2/
