
IEEE/CVF关于计算机视觉和模式识别(CVPR)的会议是世界上最顶尖的计算机视觉和机器学习会议之一。在这篇博客文章中,我们重点介绍了CVPR 2021在感知和深度学习方面的一些趋势和进展,以及它们在自动地图制作和自动驾驶车辆方面的潜在应用。the CVPR 2021
感知是自动地图制作和自动驾驶车辆的关键组成部分。在自动驾驶汽车中,多个车载传感器(光学相机、激光雷达和雷达)与人工智能和机器学习方法结合使用,以提取静电和动态对象,如标志、车道标线、行人、汽车等。在自动地图制作中,我们使用多源数据来创建现实的数字表示。地图制作的多源数据包括众包OEM传感器数据、工业捕获车辆传感器数据(LiDAR和街道图像)、俯视图像、仪表盘摄像头视频和其他街道图像来源。车道标记和道路边界用于构建车道模型。车道模型与标志、杆子和红绿灯一起有助于车辆定位。标志、车道标线、红绿灯、停车线和人行横道等功能对高级驾驶员辅助系统非常有用。其他地图要素包括建筑物、公路网等。Advanced Driver-Assistance System
来源:这里是Live Sense SDK演示HERE Live Sense SDK demo
深度学习目标检测与分割技术已广泛应用于图像特征提取和LiDAR自动识别。对于标志、红绿灯、行人和汽车等特征,通常采用深度学习的对象检测方法来检测对象的包围盒。对于诸如车道标记、道路边界、停车线、人行横道和建筑物等特征,通常使用语义分割或实例分割方法来为图像中的每个类别或每个对象创建像素级遮罩。语义分割将同一类的多个对象视为单个实体,而实例分割将同一类的多个对象视为不同的单独对象(或实例)。然后,常用图像处理方法提取车道标线、道路边界等线状特征的分割骨架,以及建筑物等特征的多边形向量。
虽然在深度学习对象检测和分割方面已经取得了许多进展,但在推理速度、模型精度和网络结构/表示方面仍有改进的机会。当在生产中大规模部署这些深度学习模型时,这些改进对于相关感知管道-™的关键性能指标(KPI)至关重要,例如延迟、质量、吞吐量和成本。在这方面,下面是CVPR 2021上最近提出的改进建议的摘录。
目标检测器主要分为两类:一级检测器和两级检测器。通常,单级检测器如YOLO(只看一次)和SSD(单次激发检测)优先考虑推理速度,而两级检测器(如较快的R-CNN(基于区域的卷积神经网络)和Mask R-CNN)优先考虑检测精度。
Scaled-YOLOv4目标检测器基于交叉状态部分(CSP)网络方法,减少了参数数量和计算量。与其他著名的探测器如EfficientDet、YOLOv4和Mask R-CNN相比,它在速度和精度之间实现了更好的平衡。它可以向上和向下扩展,适用于高端GPU、通用GPU或低端边缘设备等各种设备上的大型和小型网络。
亮点:
?œ…Scaled-YOLOv4比EfficientDet、YOLOv4和Mask R-CNN等其他著名检测器在速度和精度之间实现了更好的平衡。
?œ…截至2021年7月,在COCO实时目标检测排行榜上,缩放模型YOLOv4-Csp-P7和YOLOv4-Csp-P6分别是?œ?排名#2和#4?œ?Leaderboard of Real-Time Object Detection on COCO
?œ…YOLOv4-CSP-P7大型车型在MSCOCO 2017上以~16 FPS的速度在特斯拉V100上实现了56.0%的AP。与Mask R-CNN相比,在精度和速度上都有了显着的提高,后者在5FPS时达到了40.3%的AP。
?œ…小型型号YOLOv4-TINE在RTX 2080Ti上使用TensorRT-FP16以约1774 FPS的极快速度运行。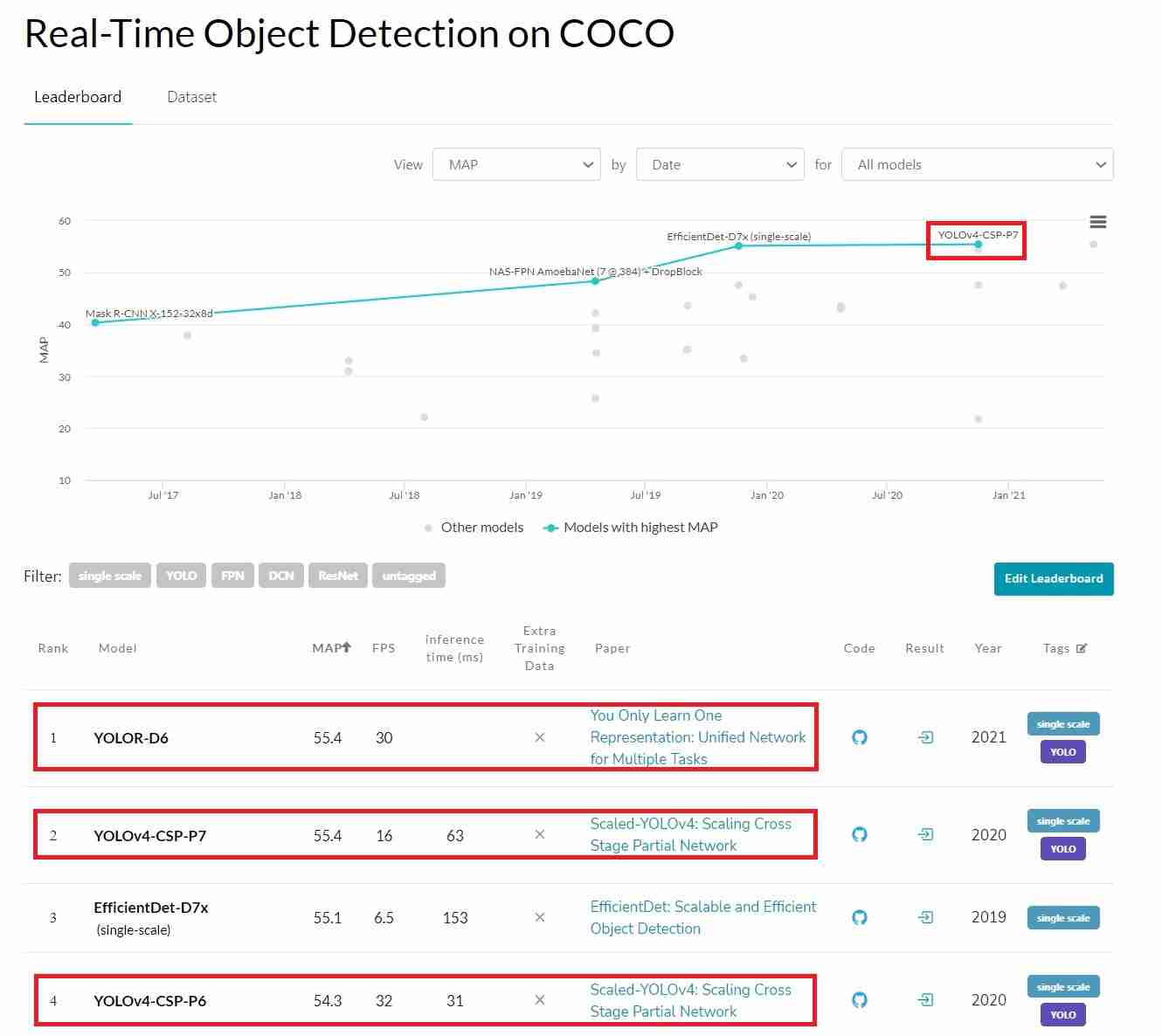
来源:COCO实时目标检测排行榜Leaderboard of Real-Time Object Detection on COCO
值得注意的是,同一作者简姚望博士在他们最近的论文“你只学一个代表”中又有了很大的改进:多任务的统一网络。YOLOR达到了与YOLOv4-CSP-P7相当的精度,推理速度几乎翻了一番。它现在是排行榜上的œ?排行榜第一名?œ?看到AI/ML技术如何以如此快的速度发展,令人兴奋。You Only Learn One Representation: Unified Network for Multiple Tasks
现有的深度学习建筑物提取方法一般分为两类。第一类通过U-Net或DeepLabv3等语义分割神经网络生成栅格概率图。然后通过轮廓检测和多边形简化将概率图矢量化。通常需要昂贵的后处理步骤来处理常见的分割伪像,例如平滑的角点。另一类深度分割方法直接学习(多边形)矢量表示,例如使用RNN(递归神经网络)的PolyMapper。这些方法通常局限于没有洞的简单多边形,不能处理复杂的建筑物和带有普通墙的相邻建筑物。
Girard等人提出的多任务学习方法。通过向标准分割模型学习额外的帧场输出,解决了上述挑战。帧场不仅提高了分割性能,导致更锐利的角点,而且还提供了快速多边形化算法的输入,该算法处理有洞的复杂建筑和相邻建筑之间的公共墙的情况。
亮点:
?œ…用于建筑物提取的分割和帧域学习的多任务学习方法
?œ…学习帧场与对象切线对齐,这样可以改进分段,从而获得更锐利的角点。
?œ…提出了一种利用框架场的快速多边形化方法,可以很自然地处理复杂建筑物和相邻建筑物。
?œ…该方法需要地面真实多边形建筑注释。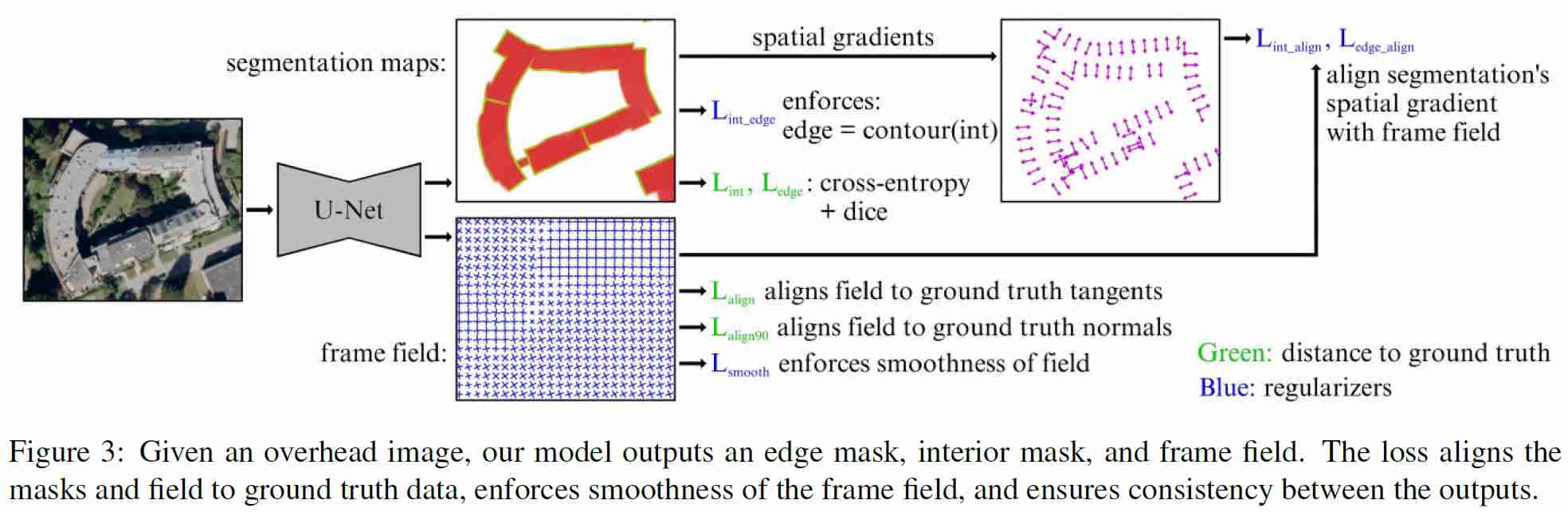
资料来源:Girard等人。Girard et al.
为了从Dashcam视频或街道级图像序列中提取特征,通常需要检测和跟踪连续帧中的对象来确定对象的3D位置。现有的视频实例分割(VIS)方法通常遵循检测跟踪范例。它在很大程度上依赖于图像级实例分割模型来分割和分类每个单独帧的实例。然后,在该组实例上运行跟踪算法,以执行跨连续帧的数据关联。
Wang等人。提出了一种基于Transformers的VIS框架,将VIS任务看作一个直接的端到端并行序列解码/预测问题。VisTR将连续图像帧的视频剪辑作为输入,并直接按顺序输出一系列实例预测。在自然语言处理(Natural Language Processing,NLP)中,转换器被广泛用于序列到序列的学习。本文是首次使用Transformers对视频实例进行分割。
亮点:
?œ…�VISTR构建在Transformers之上,它将VIS任务建模为直接的端到端序列预测问题。
?œ…�VISTR的灵感来自于facebookâuro™之前为物体检测所做的detr(检测变压器)工作。
?œ…�引入了一种新的实例序列匹配和分割策略,用于在序列级别对实例进行监督和分割。
?œ…�VISTR在Youtube-VIS数据集上使用单一模型实现了方法中最好的AP和速度。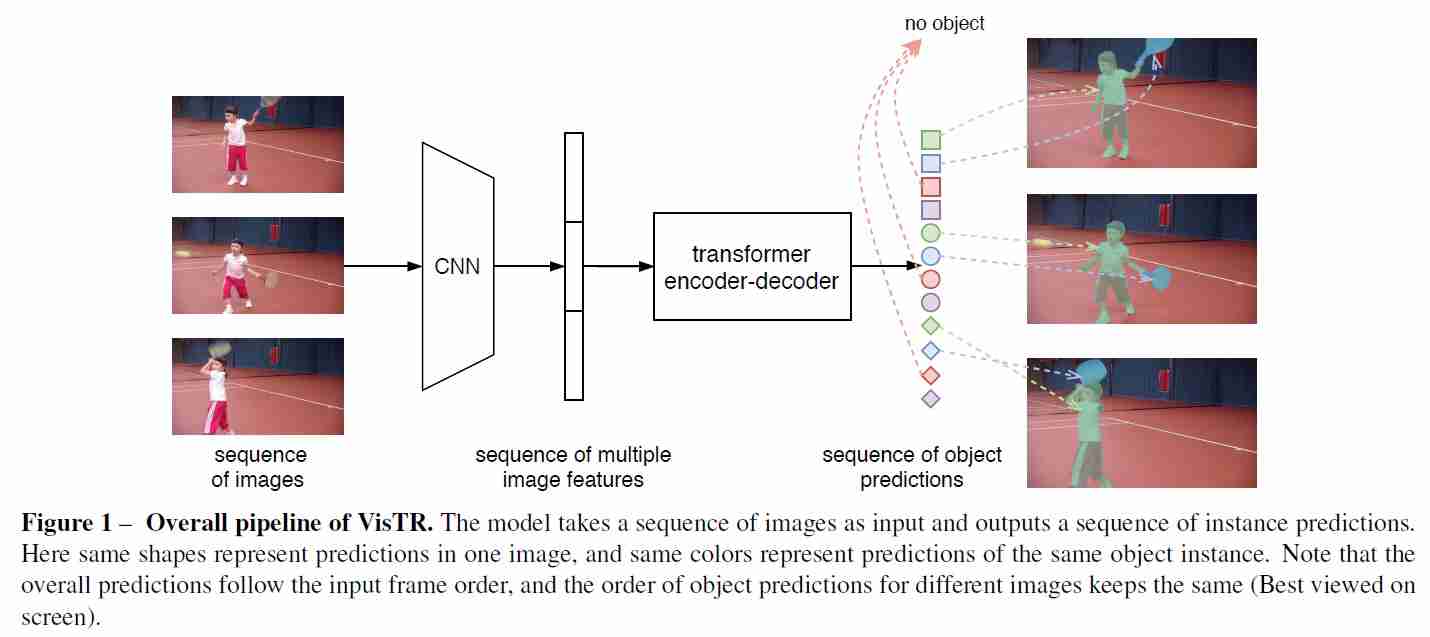
资料来源:王等人。Wang et al.
在这篇博客文章中,我们讨论了在CVPR 2021上提出的感知方面的最新改进。提取是基于监督学习的,这通常需要大量的人工标记数据。我们将在下面的博客中讨论半监督学习和自我监督学习的主题。
想知道更多关于自动地图制作中的人工智能和机器学习的知识吗?跟我们走,机器学习和人工智能在数字制图中的应用。👈Machine Learning & AI in Digital Cartography
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/24/%e6%84%9f%e7%9f%a5%e5%9c%a8%e8%87%aa%e5%8a%a8%e5%9c%b0%e5%9b%be%e5%88%b6%e4%bd%9c%e5%92%8c%e8%87%aa%e5%8a%a8%e9%a9%be%e9%a9%b6%e8%bd%a6%e8%be%86%e2%80%8a-%e2%80%8acvpr2021%e4%b8%ad%e7%9a%84%e6%bd%9c/
