
使用更好的引擎进行检测

由于检测器的准确性在很大程度上依赖于其特征提取网络,因此我们将骨干网络,如Resnet和VGG,称为检测器的“œEngine”�。这里我们介绍一些深度学习时代的重要检测引擎。
AlexNet(2012)
AlexNet是一个八层的深度网络,是开启计算机视觉深度学习革命的第一个CNN模型。
“VGG”(2014)
VGG是由牛津大学™的视觉几何小组于2014年提出的。它将模型“EUROURE™”的深度增加到16“EUREO”19层,并使用非常小的(3?3)卷积滤波器,而不是以前在ALEXNET中使用的5?5和7?7。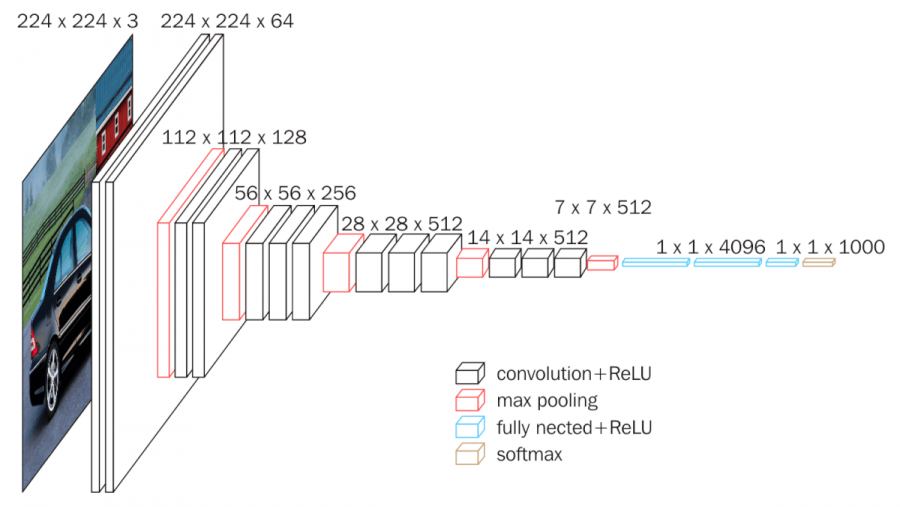
谷歌乐网(2016)
GoogleNet增加了有线电视新闻网™的宽度和深度(最多22层)。Inception系列的主要贡献是引入了因子分解、卷积和批处理标准化。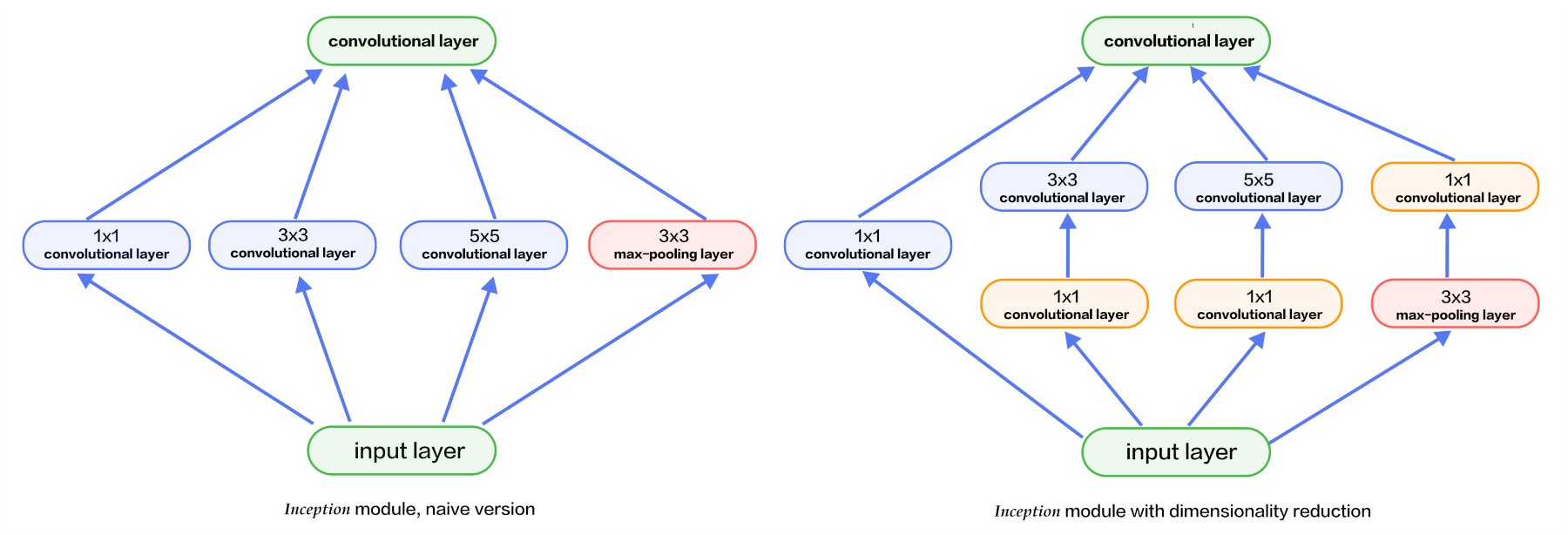
RESNET(2015)
RESNET是一种新型卷积网络体系结构,它比以前使用的体系结构要深很多(多达152层)。RESNET旨在通过参照层输入将其层重新表示为学习残差函数来简化网络的训练。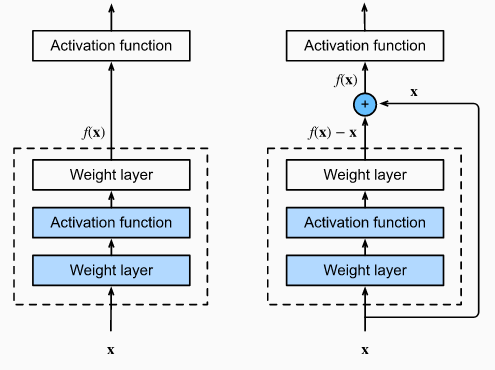
DenseNet(2017)
ResNet的成功表明,CNN的快捷连接使我们能够训练更深入、更准确的模型。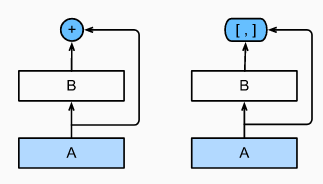
DenseNet的作者接受了这一观察结果,并引入了一种紧密相连的挡路,它以前馈的方式将每一层与每一层连接起来。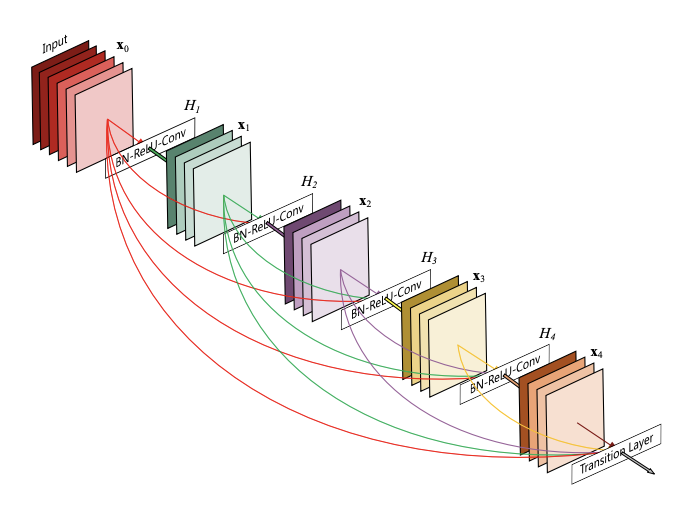
塞内特(2018年)
SENET的主要贡献是将全局池化和洗牌相结合,以了解特征映射在通道方面的重要性。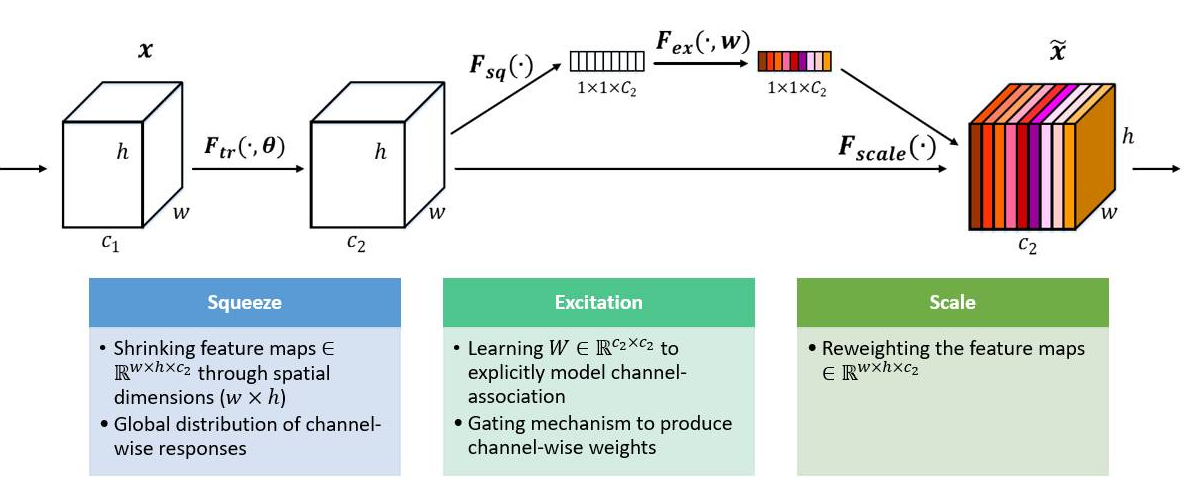
配备新引擎的物体探测器
近年来,许多最新的引擎已经应用于目标检测。例如,一些最新的目标检测模型,如STDN、DSOD、TinyDSOD和Pelee,都选择DenseNet作为它们的检测引擎。Mask RCNN作为最先进的分段模型,应用了下一代ResNet:ResNeXt作为其检测引擎。此外,为了加快检测速度,在MobileNet和Lighthead RCNN等探测器中也使用了由Incepion的改进版本Xception引入的沿深度可分离的卷积运算。
具有更好特征的检测
特征表示的质量是目标检测的关键。近年来,许多研究人员在一些最新引擎的基础上努力进一步提高图像特征的质量,其中最重要的两组方法是:1)特征融合和2)学习具有大接受范围的高分辨率特征。
为什么功能融合很重要?
不变性和等方差是图像特征表示中的两个重要性质。
- 分类的目的是学习高层语义信息,因此需要不变的特征表示。
- 由于目标定位的目的是区分位置和尺度的变化,因此目标定位需要等变表示。
由于目标检测包括目标识别和定位两个子任务,因此检测器同时学习不变性和等方差是至关重要的。近三年来,特征融合在目标检测中得到了广泛的应用。作为CNN模型,它由一系列卷积和汇聚层组成:
- 较深层次的特征具有较强的不变性,但等价性较小。这虽然有利于类别识别,但在目标检测中存在定位精度不高的问题。
- 相反,较浅层的特征不利于语义的学习,但它包含了更多关于边缘和轮廓的信息,有助于对象定位。
因此,在CNN模型中集成深层和浅层特征有助于提高不变性和等变性。
不同方式的特征融合:处理流程
目前目标检测中的特征融合方法可以分为两类:1)自下而上的融合,2)自上而下的融合,具体如下: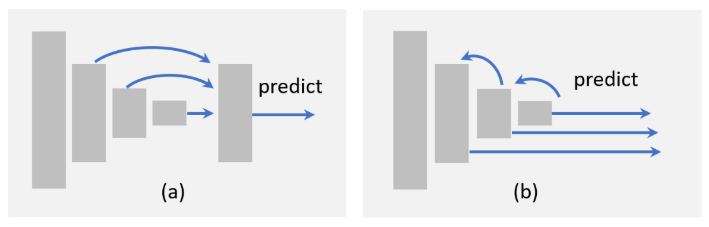
自下而上的融合通过跳跃连接将浅层特征前馈到更深的层[尺度可转换的目标检测,通过连接用于目标检测的特征图来增强SSD,用于单级检测的残差特征和统一预测网络,特征融合的SSD:小目标的快速检测]。相比之下,自上而下的融合将深层的特征反馈到浅层[用于目标检测的特征金字塔网络,用于目标检测的单炮细化神经网络,通过卷积神经网络扩展单炮多盒检测器的浅层部分,Beyond Skip Connections:Top-Down Modulation for Object Detect,RON:Reverse Connection with Objectty Prior Networks for Object Detect,SteirNet:Top-Down语义Aggregation for Accurate One Shotion Detect](用于目标检测的特征金字塔网络,用于目标检测的单炮精化神经网络,用于精确单炮检测的自顶向下语义聚合)。除了这些方法之外,最近还提出了更复杂的方法,例如,跨不同层编织特征[编织单镜头检测器的多尺度上下文]。Scale-Transferrable Object Detection Enhancement of SSD by concatenating feature maps for object detection Residual Features and Unified Prediction Network for Single Stage Detection Feature-Fused SSD: Fast Detection for Small Objects Feature Pyramid Networks for Object Detection Single-Shot Refinement Neural Network for Object Detection Extend the shallow part of Single Shot MultiBox Detector via Convolutional Neural Network Beyond Skip Connections: Top-Down Modulation for Object Detection RON: Reverse Connection with Objectness Prior Networks for Object Detection StairNet: Top-Down Semantic Aggregation for Accurate One Shot Detection Weaving Multi-scale Context for Single Shot Detector
由于不同层的特征地图在其空间和通道维度方面可能具有不同的大小,因此可能需要适应这些特征地图,例如通过调整通道的数量、对低分辨率地图进行上采样或将高分辨率地图下采样到适当的大小。要做到这一点,最简单的方法是使用最近的-或双线性-插值[用于对象检测的功能金字塔网络,超越跳过连接:用于对象检测的自上而下的调制]。此外,分数步进卷积(也称为转置卷积)[可视化和理解卷积网络,用于中高级特征学习的自适应反卷积网络],是最近流行的另一种调整特征地图大小和调整通道数量的方法。使用分数步进卷积的优点是它可以自己学习一种合适的方式来执行上采样。Feature Pyramid Networks for Object Detection Beyond Skip Connections: Top-Down Modulation for Object Detection Visualizing and Understanding Convolutional Networks Adaptive deconvolutional networks for mid and high level feature learning
不同方式的特征融合:基于元素的操作
从局部角度看,特征融合可以看作是不同特征地图之间的元素级操作。有三组方法:1)元素求和,2)元素乘积,3)拼接,如下所示。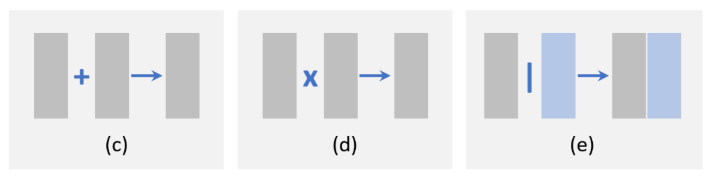
元素求和是进行特征融合的最简单方法。元素乘积与元素求和非常相似,唯一的区别是使用乘法而不是求和。基于元素的乘积的一个优点是它可以用来抑制或突出特定区域内的特征,这可以进一步有利于小对象检测[RON:Reverse Connection with Objecty Prior Networks for Object Detection,Face Attendence Network:一种用于遮挡人脸的有效人脸检测器,具有区域注意力的单镜头文本检测器]。特征拼接是特征融合的另一种方式。它的优点是可以集成不同区域的上下文信息[用于快速目标检测的统一多尺度深卷积神经网络、基于多区域和语义分割的CNN模型的目标检测、用于目标检测的关注上下文、用于小目标检测的R-CNN],缺点是增加了存储量。RON: Reverse Connection with Objectness Prior Networks for Object Detection Face Attention Network: An Effective Face Detector for the Occluded Faces Single Shot Text Detector with Regional Attention A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection Object detection via a multi-region & semantic segmentation-aware CNN model Attentive Contexts for Object Detection R-CNN for Small Object Detection
利用大接收视野学习高分辨率特征
感受场是指对计算输出的单个像素有贡献的输入像素的空间范围。接受域较大的网络能够捕获更大规模的上下文信息,而接受域较小的网络可能更关注局部细节。
要素分辨率对应于输入和要素地图之间的下采样率。特征分辨率越低,就越难检测到小目标。
提高要素分辨率的最直接方法是移除汇聚图层或降低卷积下采样率。但是这会带来一个新的问题,由于输出步幅的减小,接收范围会变得太小。换句话说,这将缩小检测器的范围,并可能导致某些大型对象的遗漏检测。(™œSight-uro�)(这将缩小检测器的范围,并可能导致某些大型对象的遗漏检测)。
同时提高感受野和特征分辨率的一种可行方法是引入膨胀卷积(也称为。Arous卷积,或带孔的卷积)。膨胀卷积最早是在语义分割任务[基于扩张卷积的多尺度上下文聚合,扩张残差网络]中提出的。其主要思想是对卷积过滤进行扩展,并使用稀疏参数。Multi-Scale Context Aggregation by Dilated Convolutions Dilated Residual Networks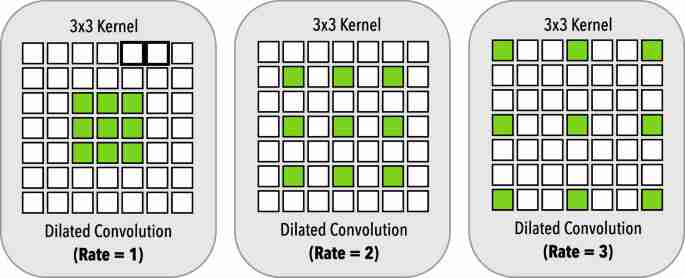
在左边,我们有扩张率r=1的膨胀卷积,相当于标准卷积。中间的扩张率r=2,右侧的扩张率r=3。所有扩张的卷积都有3?-3的核大小和相同的参数数。
例如,膨胀率为2的3奥3过滤与5奥5籽粒具有相同的接受野,但只有9个参数。膨胀卷积在目标检测中得到了广泛的应用,在不增加任何参数和计算量的情况下,有效地提高了检测精度。
超出滑动窗口
虽然目标检测已经从使用手工制作的特征发展到深度神经网络,但检测仍然遵循特征映射上的欧式œ滑动窗口-欧式�[可变形零件模型是卷积神经网络]的范例。最近,在滑动窗口之外建造了一些探测器。Deformable Part Models are Convolutional Neural Networks
作为子区域搜索的检测
子区域搜索提供了一种新的检测方式。最近的一种方法是将检测看作是一个路径规划过程,从初始网格开始,最后收敛到期望的地面真值框[G-CNN:基于迭代网格的对象检测器]。另一种方法是将检测视为改进预测边界框的角点的迭代更新过程[AttentionNet:Aggregating弱方向for Accurate Object Detection(AttentionNet:聚合弱方向以进行准确的对象检测])。G-CNN: an Iterative Grid Based Object Detector AttentionNet: Aggregating Weak Directions for Accurate Object Detection
作为关键点定位的检测

关键点定位是一项有着广泛应用的重要计算机视觉任务,如人脸表情识别[HyperFace:a Deep Multi-task Learning Framework for Face Detection,Landmark Location,Position Estim,and Gender Recognition],人体姿态识别[基于部分亲和场的实时多人2D位姿估计]等,由于图像中的目标可以由其地真值框的左上角和右下角唯一确定,因此检测任务可以等价地表示为一个成对的关键点定位问题这个想法最近的一个实现是预测角落的热图[CornerNet:将对象检测为成对的关键点]。该方法的优点是可以在语义分割框架下实现,不需要设计多尺度锚盒。HyperFace: A Deep Multi-task Learning Framework for Face Detection, Landmark Localization, Pose Estimation, and Gender Recognition Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields CornerNet: Detecting Objects as Paired Keypoints
本地化的改进
边界框细化
提高定位精度最直观的方法是包围盒细化,可以看作是对检测结果的后处理。虽然包围盒回归已经集成到大多数现代物体探测器中,但仍然有一些物体具有意想不到的尺度,无法被任何预定义的锚点很好地捕捉到。这将不可避免地导致对它们位置的不准确预测。
为此,最近引入了-EUROUREœ迭代边界框精化?�[Cascade R-cnn:深入研究高质量对象检测,Refinenet:迭代精化以精确定位对象,精炼速度更快-RCNN用于准确的对象检测],方法是将检测结果迭代地馈送到BB回归器中,直到预测收敛到正确的位置和大小。但是,也有研究人员指出,该方法并不能保证定位精度的单调性。Cascade R-CNN: Delving into High Quality Object Detection RefineNet: Iterative refinement for accurate object localization Refining faster-RCNN for accurate object detection
改进损失函数实现精确定位
在大多数现代检测器中,目标定位被认为是一个坐标回归问题。然而,这种范式有两个缺点。
- 首先,回归损失函数不对应于本地化的最终评估。例如,我们不能保证较低的回归误差总是会产生较高的IOU预测。
- 第二,传统的包围盒回归方法没有提供定位的置信度。当有多个BBâuro™彼此重叠时,这可能导致非最大抑制失败。
通过设计新的损失函数可以缓解上述问题。最直观的设计是直接使用借条作为本地化损失函数[UnitBox:A Advanced Object Detection Network]。其他一些研究人员进一步提出了一种IOU引导的NMS,以提高训练和检测阶段的定位[获得精确目标检测的定位置信度]。此外,一些研究人员还试图通过预测包围盒位置的概率分布来改进概率推理框架[LocNet:Improving Location Accuracy for Object Detection]下的定位。UnitBox: An Advanced Object Detection Network Acquisition of Localization Confidence for Accurate Object Detection LocNet: Improving Localization Accuracy for Object Detection
在分段中学习
最近的研究表明,结合语义分割的学习可以提高目标检测的效率。
为什么细分可以提高检测能力?
- 细分有助于类别识别。边缘和边界是构成人类视觉认知的基本要素。由于语义分割任务的特征很好地捕捉了对象的边界,因此分割可能有助于类别识别。
- 分段有助于精确定位。对象的地面真实边界框由其明确定义的边界确定。由于对象边界可以很好地编码在语义分割特征中,通过分割进行学习将有助于精确的对象定位。
- 分段可以作为上下文嵌入。日常生活中的物体被不同的背景所包围,如天空、水、草等,所有这些元素都构成了一个物体的语境。结合语义分割的上下文将有助于目标检测,例如,飞机更有可能出现在空中而不是水面上。
分段如何改进检测?
- 在丰富的功能中学习。最简单的方法是将分割网络视为固定的特征提取器,并将其集成到检测框架中作为附加特征[通过多区域和语义分割感知的cnn模型进行对象检测,Stuffnet:Using?euro˜Stuffâuro™to Improach Object Detection,Context priming and Feedback for First R-cnn(通过多区域和语义分割感知的cnn模型进行对象检测,上下文启动和反馈以提高R-cnn速度)]。它很容易实现,但是分段网络可能会带来额外的计算。
- 使用多任务丢失函数进行学习。另一种方式是在原始检测框架之上引入额外的分割分支,并用多任务丢失函数(分割丢失+检测丢失)来训练该模型[Mask R-cnn,StuffNet:Using?uro˜Stuff?™to Improach Object Detection]。在大多数情况下,分段早午餐将在推理阶段被移除。这样,检测速度不会受到影响,但训练需要像素级的图像标注。为此,一些研究人员采用了œ弱监督学习�的想法:他们不是基于像素级注释掩模进行训练,而是简单地基于边界框级注释来训练分割早午餐[人脸注意网络:用于遮挡人脸的有效人脸检测器,具有丰富语义的单镜头对象检测]。
旋转和比例变化的鲁棒检测
目标旋转和尺度变化是目标检测中的重要挑战。由于CNN学习到的特征并不是旋转不变、尺度变化很大的,所以近年来,很多人在这个问题上下了功夫。
旋转鲁棒检测
目标旋转在检测任务中非常常见。解决这一问题的最直接的方法是数据增强,使得任何方向的目标都能被增强的数据很好地覆盖[航空图像中基于深卷积神经网络的方向鲁棒目标检测]。另一种解决方案是为每个方向训练独立的检测器[基于在线样本的全卷积网络用于遥感图像中的飞机检测、多类地理空间目标检测和基于部分检测器集合的地理图像分类]。除了这些传统的方法外,最近还出现了一些新的改进方法。Orientation robust object detection in aerial images using deep convolutional neural network Online Exemplar-Based Fully Convolutional Network for Aircraft Detection in Remote Sensing Images Multi-class geospatial object detection and geographic image classification based on collection of part detectors
- 旋转不变损失函数。旋转不变损失函数学习的思想可以追溯到20世纪90年代[模式识别中的变换不变性–切线距离和切线传播]。最近的一些工作引入了对原始检测损失函数的约束,以使旋转目标的特征保持不变[RIFD-CNN:旋转不变和Fisher鉴别卷积神经网络用于目标检测,学习旋转不变卷积神经网络用于VHR光学遥感图像目标检测]。
- 旋转校准。另一种方法是对候选对象进行几何变换[基于渐进校准网络、空间变换网络、监督变换网络的实时旋转不变人脸检测]。这对于多级检测器特别有用,在多级检测器中,早期的相关性将有利于后续的检测。这一思想的代表是空间变换网络(STN)。STN现在已经用于旋转文本检测和旋转人脸检测。
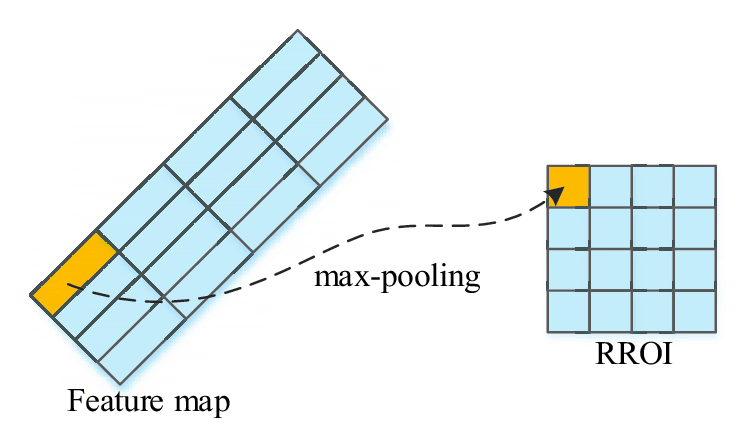
- 轮换ROI合并。在两阶段检测器中,特征池的目的是提取任意位置和大小的目标建议的固定长度的特征表示,首先将该建议均匀地划分成一组网格,然后将网格特征连接起来。由于网格剖分是在笛卡尔坐标下进行的,因此特征对于旋转变换并不是不变的。最近的一项改进是在极坐标下对网格进行网格划分,以便特征对旋转变化具有鲁棒性[基于在线样本的全卷积网络用于遥感图像中的飞机检测]。
尺度稳健检测
规模适应性训练。如图19(A)所示,大多数现代探测器将输入图像重新缩放到固定大小,并在所有尺度上反向传播对象的损失。然而,这样做的一个缺点是会出现欧元œ规模不平衡的欧元�问题。在检测过程中构建图像金字塔可以缓解这一问题,但不能从根本上缓解这个问题[R-FCN:基于区域的全卷积网络的目标检测,用于图像识别的深度残差学习]。最近的一项改进是图像金字塔的尺度归一化(SNIP)[目标检测中的尺度不变性分析(SNIP)],其在训练和检测阶段构建图像金字塔,并且仅反向传播某些选定尺度的损失,如图19(B)所示。一些研究人员进一步提出了一种更有效的训练策略:利用高效重采样(Sniper)[Sniper:Efficient Multi-Scale Training]进行剪裁,即将图像裁剪并重新缩放到一组子区域,以便从大批量训练中受益。R-FCN: Object Detection via Region-based Fully Convolutional Networks Deep residual learning for image recognition An Analysis of Scale Invariance in Object Detection — SNIP SNIPER: Efficient Multi-Scale Training
尺度自适应检测。大多数现代检测器使用固定配置来检测不同大小的物体。例如,在一个典型的基于CNN的检测器中,我们需要仔细定义锚的大小。这样做的一个缺点是配置不能适应意外的比例变化。为了改进对小对象的检测,在最近的一些检测器中提出了一些自适应放大技术,以自适应地将小对象放大到较大对象的动态放大网络(Dynamic Zoom-in NetworkœFast Object Detect in Large Image,Adaptive Object Detect Using Neighency�Zoom Forecast)[œ�(用于大图像中快速对象检测的动态放大网络,使用邻接和缩放预测的自适应对象检测])。最近的另一项改进是学习预测图像中对象的比例分布,然后根据该分布自适应地重新缩放图像[ScaleNet:在超市及更远的地方引导对象建议生成,尺度感知的人脸检测](ScaleNet:Guide Object Proposal Generation in Supermarket and Beyond,Scale-Aware Face Detection)。Dynamic Zoom-in Network for Fast Object Detection in Large Images Adaptive Object Detection Using Adjacency and Zoom Prediction ScaleNet: Guiding Object Proposal Generation in Supermarkets and Beyond Scale-Aware Face Detection
从头开始培训
大多数基于深度学习的检测器首先在大规模数据集(比如ImageNet)上进行预训练,然后在特定的检测任务上进行微调。人们一直认为预训练有助于提高泛化能力和训练速度,问题是,我们真的需要对ImageNet上的检测器进行预训练吗?实际上,采用预先训练好的网络进行目标检测存在一定的局限性。
- 第一个限制是ImageNet分类和目标检测之间的差异,包括它们的损失函数和尺度/类别分布。
- 第二个限制是域失配。由于ImageNet中的图像是RGB图像,而检测有时会应用于深度图像(RGB-D)或3D医学图像,因此预先训练的知识不能很好地迁移到这些检测任务中。
近年来,一些研究人员试图从头开始训练物体探测器。为了加快训练速度和提高稳定性,一些研究人员引入密集连接和批量归一化来加速浅层的反向传播[DSOD:Learning Deep Supervised Object Detector From ScratchDet:Training Single-shot Object Detector From ScratchDet]。K.He等人最近的一项工作。[重新思考ImageNet预训练]通过探索相反的机制,进一步质疑了预训练的范式:他们报告了好胜在COCO数据集上使用随机初始化训练的标准模型进行目标检测的结果,唯一的例外是增加了训练迭代的次数,以便随机初始化的模型可以收敛。即使只使用10%的训练数据,来自随机初始化的训练也具有令人惊讶的鲁棒性,这表明ImageNet预训练可以加快收敛,但不一定提供正则化或提高最终检测精度。DSOD: Learning Deeply Supervised Object Detectors from Scratch ScratchDet: Training Single-Shot Object Detectors from Scratch Rethinking ImageNet Pre-training
对抗性训练
生成性对抗网络(GAN)已被广泛应用于图像生成、图像风格转换、图像超分辨率等计算机视觉任务。近年来,GaN也被应用于目标检测,特别是提高了对小目标和遮挡目标的检测能力。
GAN已经被用来通过缩小小和大之间的表示来增强对小对象的检测[感知生成对抗网络用于小对象检测,SOD-MTGAN:通过多任务生成对抗网络的小对象检测]。为了改进被遮挡对象的检测,最近的一个想法是通过使用对抗性训练来生成遮挡掩模[A-Fast-RCNN:Hard Positive Generation via Adversary for object Detection(A-Fast-RCNN:Hard Positive Generation via Adversary for object Detection])。对抗网络不是在像素空间中生成样本,而是直接修改特征以模拟遮挡。Perceptual Generative Adversarial Networks for Small Object Detection Sod-mtgan: Small object detection via multi-task generative adversarial network A-Fast-RCNN: Hard Positive Generation via Adversary for Object Detection
除了这些工作之外,针对快速R-œ对象检测器的稳健物理攻击[ShapeShifter:鲁棒物理攻击](ShapeShifter:Robust Physical Attative Attack on Fird R-�Object Detector)最近引起了越来越多的关注,其目的是研究如何利用敌意示例来攻击检测器。这一课题的研究对于自动驾驶尤为重要,因为在保证其对对手攻击的鲁棒性之前,不能完全信任它。ShapeShifter: Robust Physical Adversarial Attack on Faster R-CNN Object Detector
弱监督目标检测
现代物体检测器的训练通常需要大量的人工标记数据,而标记过程耗时、昂贵且效率低下。弱监督目标检测(WSOD)旨在通过只使用图像级注释而不使用包围盒来训练检测器来解决这一问题。
最近,多示例学习已被用于弱监督对象定位和多重多示例学习,We Do-euro™t Need Not Bound-Box:Training Object Class Detectors Use Only Human Verify(只使用人工验证来训练对象类检测器)。多示例学习是一组有监督的学习方法[支持向量机用于多示例学习,解决带轴平行矩形的多示例问题]。多实例学习模型接收一组带标签的袋子,每个袋子包含许多实例,而不是使用单独标记的一组实例进行学习。如果将一幅图像中的候选对象看作一个包,以图像级标注作为标签,那么WSOD可以表示为一个多示例学习过程。Weakly Supervised Object Localization with Multi-fold Multiple Instance Learning We don’t need no bounding-boxes: Training object class detectors using only human verification Support Vector Machines for Multiple-Instance Learning Solving the multiple instance problem with axis-parallel rectangles
类激活映射是最近针对弱监督对象定位、弱监督级联卷积网络的软建议网络WSOD(Soft Proposal Networks for Wly Supervised Object Location,弱监督级联卷积网络)的又一组方法。对细胞神经网络可视化的研究表明,细胞神经网络的卷积层在没有对目标位置进行监控的情况下,起到了目标检测器的作用。类激活映射揭示了如何使CNN在接受图像级标签[用于区分定位的学习深度特征]的训练的情况下仍具有定位能力。Soft Proposal Networks for Weakly Supervised Object Localization Weakly Supervised Cascaded Convolutional Networks Learning Deep Features for Discriminative Localization
除了上述方法外,其他一些研究人员还将WSOD作为一种建议排序过程,选择信息量最大的区域,然后使用图像级标注对这些区域进行训练。WSOD的另一个简单方法是遮蔽图像的不同部分。如果检测分数大幅下降,则对象被覆盖的概率很高[深网自学对象定位]。此外,交互式标注在训练过程中考虑了人的反馈,从而提高了WSOD[We Doâuro™t Need Not Bound-Box:Training Object Class Detector Only Human Verify](我们不需要包围盒:仅使用人类验证来训练对象类检测器)。最近,生成性对抗性训练已被用于WSOD(生成性对抗性学习面向快速弱监督检测)。Self-taught object localization with deep networks We don’t need no bounding-boxes: Training object class detectors using only human verification Generative Adversarial Learning Towards Fast Weakly Supervised Detection
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/25/%e2%80%8a-%e2%80%8a%e7%9b%ae%e6%a0%87%e6%a3%80%e6%b5%8b20%e5%b9%b4%e8%ae%ba%e6%96%87%e9%98%85%e8%af%bb%e7%bb%bc%e8%bf%b0%e4%b8%83/
