

欢迎回来!在上一篇博客中,我们对数据进行了预处理,使其成为我们的模型能够理解的形式–数字。在这个博客里,我会写一些我做模特的步骤。last blog
迁移学习与移动网络
迁移学习是一个过程,在这个过程中,我们使用预先训练的模型并对其进行修改以满足我们的需要。
迁移学习的优势:
- 需要的数据相对较少
- 预定义的权重有助于提高精度
- 更容易、更快地进行培训
修改我们的标签
当我试图训练我的MobileNet模型时,我遇到了一个意外的错误,模型体系结构要求我们的标签采用数字的形式,而不是“c0”、“c1”等等。
我没有更改整个数据预处理步骤,而是删除了每个标签的第一个字符,并将剩余的字符转换为整数。
前面的代码是:Label=Cut[:Ind]这将返回“c0”。现在,它返回0。
经过这个小小的改变,我的模特训练正常了。
调整我们的图像大小
我还忘了调整图像的大小,从(480,640,3)调整到(224,224,3)。我在process_image()函数中通过添加tf.image.resize(image,(224,224))对此进行了更改
回调
回调是一种特殊函数,用于监视模型的训练,并以某种方式更改或记录。
我使用的回调是EarlyStopping回调。此回调监视模型在验证拆分上的准确性,如果模型的进度在某个“耐心”之后停止,则会停止训练。这有助于模型避免过度拟合(机器学习模式太好,不能泛化),因为它会在模型过度拟合之前停止模型。
构建和培训模型
正如我之前提到的,我正在使用MobileNet进行我的项目。我使用了这个项目的默认权重,即ImageNet,并对其进行了50个纪元的训练。我使用CategoricalCrossenropy作为我的损失函数(我们的模型有多么错误),使用Adam作为我的优化器(一种告诉模型如何改进的算法)。我的学习率是0.0023(亚当的一个参数;0.0023是一个任意数字)。我还在训练时使用了EarlyStopping回调,以防止过度适应。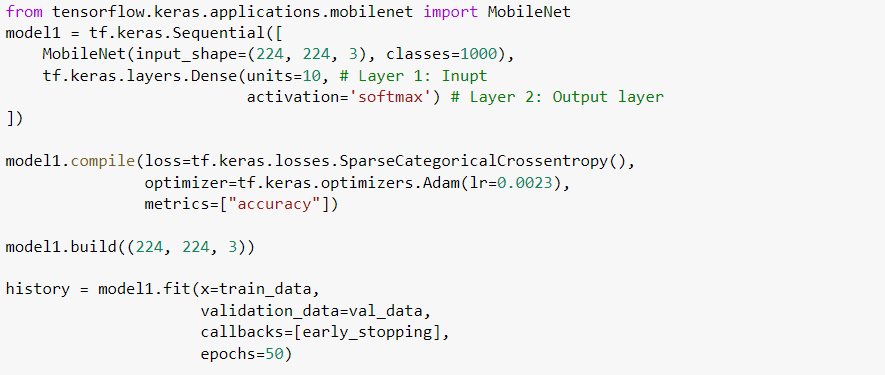
这位模特已经训练了14个纪元,我的回叫使它停了下来。对训练数据的最终准确率为51.22%,对验证数据的最终准确率为52.78%。
结论
我今天不能做很多事情,因为模型培训需要很多时间(部分原因是我忘了使用GPU)。明天我不能做任何事情,但是后天,我会通过调整一些超参数来改进这个模型。
今天就到这里吧。再见!
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/26/%e5%88%86%e5%bf%83%e9%a9%be%e9%a9%b6%e7%ac%ac%e4%b8%89%e5%a4%a9%e2%80%8a-%e2%80%8a%e5%bb%ba%e6%a8%a1%e7%ac%ac%e4%b8%80%e9%83%a8%e5%88%86/
