

自从我开始研究机器学习的现实应用程序以来,我就开始痴迷于数据集的质量,并花了几个小时来确保在训练数据集时没有出错。在处理数据时,我意识到一件有趣的事情,那就是组织数据集可以提供一个窗口,让人们了解这些组织试图解决的问题的复杂程度。新发布的公共领域的数据集可以很好地帮助我们理解计算机视觉的发展,以及需要解决的问题的新途径。
像每年一样,我虔诚地浏览了CVPR的一大堆文件,但这一次我决定做一些不同的事情。今年,我特意查找了专门关于数据集或数据集质量管理的论文。令我意想不到的是,我一点也没有失望。佐治亚理工学院的约书亚·普雷斯顿(Joshua Preston)提供的这个工具[链接]对我今年探索大量论文非常有用。我发现了许多有趣的数据集和人们正在努力解决它们的巧妙方法。LINK
在这篇博客中,我简要总结了几篇我觉得很吸引人的数据集论文,并通读了所有这些论文,从中提取了一些很好的细节:
1.多时相城市发展空间数据集

这篇文章是CVPR中最有趣的数据集论文,因为它解决了一个非常困难的全球问题。这个数据集试图利用卫星图像分析来解决一个地区的城市化量化问题,这对那些没有基础设施和财政资源来建立有效的民事登记系统的国家来说是一个巨大的帮助。该数据集主要是使用在18至26个月的时间跨度内捕获的卫星图像来跟踪全球约101个地点的施工情况。随着时间的推移,有1100多万个注释对单个建筑和建筑工地进行了独特的像素级标记。
所有这一切可能会让它听起来像是一个稍微更具挑战性的对象分割和跟踪问题。但是等着看吧。分割是困难的,但这一次是类固醇分割。为了清楚起见,每帧大约有30多个对象。此外,与普通视频数据不同,由于天气、光照和地面季节性影响等原因,帧之间几乎没有一致性。这使得它比我们最喜欢的视频分类数据集(如MOT17和斯坦福无人机数据集)要困难得多。
虽然这可能是一个棘手的问题,但从全球福利的角度来看,解决它可能会带来很多好处。
[此处提供纸质链接][数据集链接][Paper Link Here] [Dataset link]
2.城市尺度三维点云语义分割:数据集、基准和挑战

今年的会议集中在3D图像处理及其相应的方法上。所以,这个名为Sensat Urban的数据集也并不令人惊讶,因为这个摄影测量3D点云的数据集比目前可用的任何开源数据集都要大得多。它的覆盖范围超过7.6公里。覆盖约克、剑桥和伯明翰的城市景观广场。每个点云都被标记为13个语义类别之一。这一数据集有可能推进对许多有前途的领域的研究,如自动化面积测量、智能城市和大型基础设施规划和管理。
在这篇论文中,他们还对点云中的颜色信息进行了实验,并证明了在颜色丰富的点云上训练的神经网络在测试集上能够更好地泛化。这实际上为这一领域未来应用的发展提供了一个重要的方向。
[这里有纸质链接][Github回购][Paper Link here] [Github repo]
3.口语时刻:从视频描述中学习联合视听表达
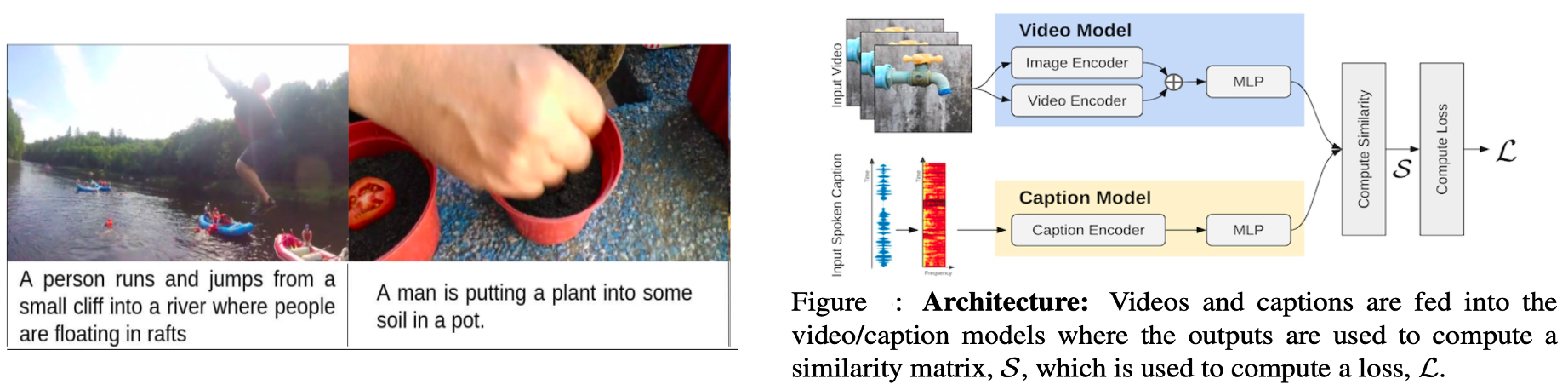
这是今年另一个最受欢迎的数据集,因为它对图像字幕和视频摘要问题采取了略有不同的方法。通常,对于这类任务,我们有像COCO这样的数据集,它们有图像及其附带的文本说明。虽然这种方法已经被证明是有希望的,但我们经常忘记,我们的视觉体验有很多丰富的总结都是在口语方面进行的。利用这种直觉,这个数据集建立了一个包含500K音频描述的短视频语料库,描述了广泛的不同事件。然而,他们并没有止步于展示一个令人惊叹的数据集,他们还提供了一个优雅的解决方案,使用自适应平均边距(AMM)方法来解决视频/字幕检索问题。
[这里有纸质链接][Paper Link here]
4.概念性12M:推动网络尺度图文预训练,识别长尾视觉概念

最近,由于预先训练的变压器和CNN架构的性能提高,模型预训练获得了巨大的流行。通常情况下,我们希望在具有巨大NO的相似数据集上训练模型。然后使用转移学习来利用下游任务的模型。到目前为止,唯一可用于预培训的大规模数据集是CC-3M数据集,用于视觉+语言任务,具有300万个标题。现在,谷歌研究团队通过放松对数据报废的限制,将这个数据集扩展到了1200万对图片-字幕对。更有趣的是生成数据集的方法。在数据集管理过程中使用Google Cloud Natural Language API和Google Cloud Vision API来过滤任务,这对任何未来的数据集管理任务都是一个很好的教训。使用12M数据集,图像字幕模型能够学习长尾概念,即在数据集中非常具体和罕见的概念。培训方法的结果相当令人印象深刻,如下所示。
[这里有纸质链接][Paper Link here]
5.EURO-PVI:密集城市中心的行人车辆交互

虽然关于全自动驾驶系统的讨论很多,但事实仍然是,它是一个非常困难的问题,多个问题要同时实时解决。其中一个关键部分是让这些自主系统理解行人对他们出现的反应的行为。直觉上,我们一直在这样做,但对机器来说,这样做可能是一个相当大的挑战。因此,密集环境下行人轨迹的预测是一项具有挑战性的任务。因此,Euro-PVI数据集通过在行人和骑自行车者轨迹的标注数据集上训练模型来解决这一问题。早些时候,斯坦福无人机、nuScenes和Lyft L5等数据集关注的是附近车辆的轨迹,但这只是自动驾驶系统整体情况的一部分。EURO-PVI通过交互时的视觉场景、交互过程中的速度和加速度以及整个交互过程中的整体坐标轨迹等信息,提供了交互的全面图像。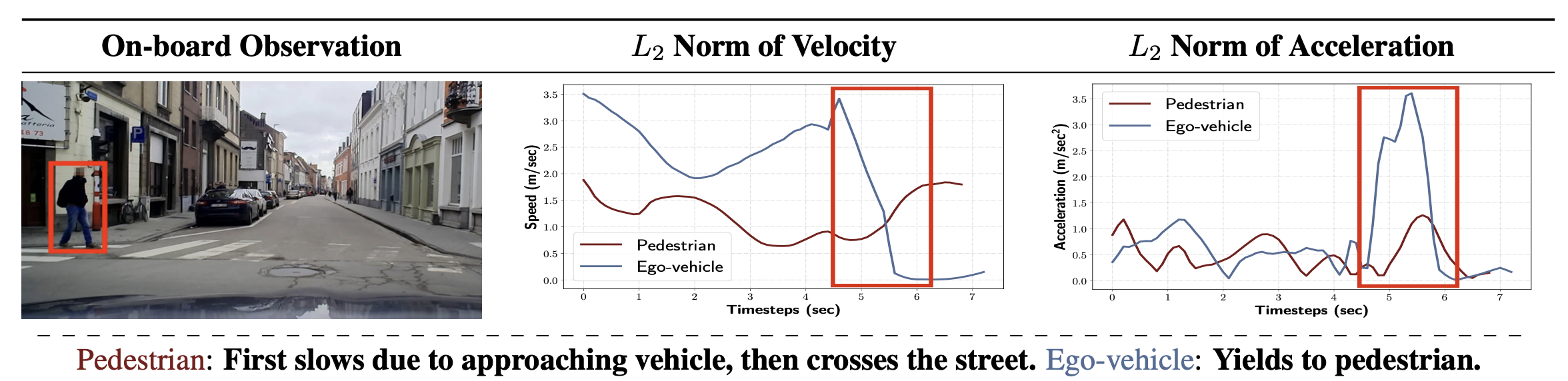
所有这些信息都必须由训练好的模型映射到相关的潜在空间。针对撞击在潜在空间中轨迹和视觉信息的联合表示问题,本文还提出了一种产生式结构的联合B-VAE,这是一种变分自动编码器,经过训练可以对参与者的轨迹进行编码并解码成未来的合成轨迹。
[这里有纸质链接][Paper Link here]
结论
总体而言,了解ML研究人员试图使用标记的数据集解决的有趣问题,以及机器学习和人工智能领域如何开始像重视算法一样重视数据集,是一次令人惊叹的经历。跟进即将召开的ICCV等会议上发布的数据集也将是一件有趣的事情。
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/27/datasetscvpr-2021%ef%bc%9a%e4%b8%8d%e5%ae%b9%e9%94%99%e8%bf%87%e7%9a%84%e9%97%ae%e9%a2%98-2/
