
OpenCV简介、应用、图像处理基础、行人检测器和YOLO检测器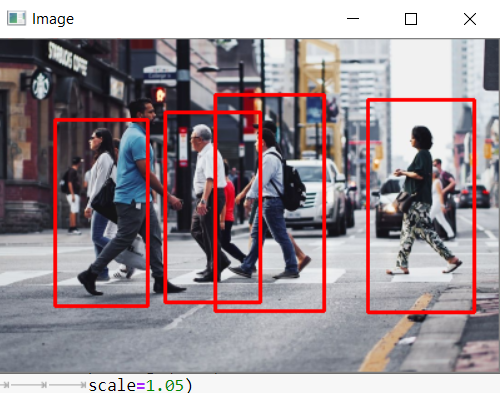
这篇文章最初发表在Omdena的博客上。你可以在那里找到所有需要的代码和一个附加的笔记本。Omdena’s blog
在我童年的日子里,我经常想照片编辑应用程序是如何知道头发或嘴唇的确切位置的,以便改变它们的颜色/色调。当报章曾经披露某一地区的确实人数时,警方又如何知道该地区是否过度挤迫呢?干脆开辆车把我们送到目的地怎么样,这样我爸爸就不用开车问问题了。有时我会认为这是某种魔术,或者说是我的幻想。我甚至记得,我奶奶过去常常让我微笑,否则相机不会给我拍照,也许她指的是面部表情识别:)
最近,我意识到通过人工智能和计算机视觉,这一切都是可能的。上个月,在进行了近一年的在线学习后,我访问了我的大学,很高兴地发现了面膜识别系统,该系统不允许人们在没有适当的口罩遮住面部和鼻子的情况下进入大学。甚至令人惊讶的是,谷歌照片是如何使用面部识别技术将图片分隔到不同的文件夹中,而且准确率几乎达到100%。
此外,Facebook算法甚至在我们标记人之前就识别出了他们。是什么让这一切成为可能?这是物体探测。目标检测已经得到了广泛的应用,仅仅通过观察图像就可以研究几乎所有可能的事情。这不是很令人兴奋吗?让我们先深入了解一下它的技术方面。
什么是物体检测?
物体检测是在静止图片或视频中找到真正的物体(如车辆、自行车、电视和人)的途径。它考虑的是图像中不同事物的肯定、限制和同一性,这使我们对图像的认知有了显著的提高,所有的事情都考虑到了这一点。它通常用于例如图像恢复、安全、监视等应用中。
目标检测技术的应用
- 面部识别:我们还可以识别肢体语言、面部语言、面部情感识别、Covid19面具检测等。人脸检测算法侧重于正面人脸的检测。它类似于对人的图像进行逐位匹配的图像检测。图像与存储在数据库中的图像匹配。
- 个人在人群中计数:这是一个重要的应用程序,最近在Omdena-iRAP挑战赛中使用。我们在那里建立了识别路上行人的模型,并进一步绘制了减少事故机会和拯救生命的模型。要了解有关这一挑战的案例研究,请阅读此处。
- 自动驾驶汽车:AI的另一个最有趣的话题。它的基础是物体检测,自动驾驶是让汽车决定下一步做什么,是加速、刹车还是转弯,它需要知道汽车周围所有物体的位置,以及需要物体检测的对象是什么,我们基本上会训练汽车检测已知的一组物体,如汽车、行人、交通灯、路标、自行车、摩托车等。
- 安全性:该对象的这一功能现在可以在我们的手机中找到,我们将图像存储在数据库中,当我们试图打开锁时,它会映射到地图上。它在一些复杂的设备上运行得非常好,只需看着你的眼睛就可以打开锁或挡路。
OpenCV简介
OpenCV是目前最流行的计算机视觉库之一。如果你想开始你在计算机视觉领域的旅程,那么透彻地理解OpenCV的概念是非常重要的。
我们会处理以下事项:
让我们从安装依赖项开始。我们需要OpenCV库来完成此操作,可以按如下方式进行安装。
pip安装openCV-python
让我们先来读一下图片:
#导入OpenCV库
导入CV2
#使用imread()函数读取图片
image=cv2.imread(‘image.png’)
#提取图片的高度和宽度
h,w=image.Shape[:2]
#显示高度和宽度
print(“Height={},width={}”.format(h,w))
输出:高度=191,宽度=264
#提取RGB值。
#这里我们随机选择了一个像素
#传入100,100作为高度和宽度。
(B,G,R)=图像[100,100]
#显示像素值
print(“R={},G={},B={}”.format(R,G,B))
输出:R=212,G=132,B=69
#我们也可以通过通道解压
#具体通道的取值
b=图像[100,100,0]
Print(“B={}”.format(B))
调整图像大小:
#resize()函数接受2个参数,
#图像和尺寸
resize=cv2.resize(image,(800,800))
输出:
#计算比例
比率=800/w
#创建包含宽度和高度的元组
DIM=(800,INT(h*比率))
#调整图片大小
RESIZE_Aspect=cv2.resize(image,dim)
#计算图片中心
中心=(带//2,小时//2)
旋转图像
#生成旋转矩阵
Matrix=cv2.getRotationMatrix2D(center,-45,1.0)
#执行仿射变换
ROTATED=cv2.warpAffine(image,Matrix,(w,h))
绘制矩形:
#我们复制的是原图,因为这是就地操作。
output=image.copy()
#使用Rectangle()函数创建矩形。
Rectangle=cv2.rectangle(OUTPUT,(1500,900),(600,400),(255,0,0),2)
它包含5个论点-
- 图像
- 左上角坐标
- 右下角坐标
- 颜色(BGR格式)
- 线宽

行人探测器:

(来自Pinterest的图像:用作代码的示例图像)
我们将使用OpenCV收集一个主要的行人检测器来获取图片。行人识别是一个重要的探索领域,因为它可以提升步行者保险框架的有用性。
我们可以从人体图像中移除头部、两只手臂、两条腿等特征,并通过它们来建立人工智能模型。在设置之后,该模型可以用于识别和跟踪图片和视频动作中的个人。在任何情况下,OpenCV都有一个与生俱来的程序来感知步行的人。它有一个预先安排的HOG(定向梯度直方图)+线性支持向量机模型来识别图片和视频运动中的步行者。
定向梯度直方图
此计算检查每个像素的直接包络像素。目标是检查当前像素从合并像素中脱颖而出的模糊程度。图形的绘制和摇晃显示了图像变暗的过程。它会重复图像中每个像素的循环。最后,每个像素都会被震动所取代,这些震动被称为渐变。这些倾斜度显示了光从光到弱的运动。通过使用这些倾斜度,计算执行进一步的检查。
为此,我们需要引入OpenCV和imutils。它可以按如下方式安装。
pip安装openCV-python
PIP安装imutils
注意:在Neighborhood框架上使用Jupyter Notebook,而不是Google CoLab,因为Colab不支持某些OpenCV功能。
代码:
导入CV2
导入imutils
#初始化养猪人
#检测器
HOG=cv2.HOGDescriptor()
hog.setSVMDetector(cv2.HOGDescriptor_getDefaultPeopleDetector())
#阅读图片
image=cv2.imread(‘img.jpg’)
#调整图片大小
image=imutils.resize(image,
宽度=最小(400,image.Shape[1]))
#检测中的所有区域
#里面有行人的图片
(Regions,_)=hog.DetectMultiScale(image,
winStride=(4,4),
填充=(4,4),
比例=1.05)
#绘制图片中的区域
对于(x,y,w,h)区域:
cv2.Rectangle(image,(x,y),
(X+w,y+h),
(0,0,255),2
#显示输出画面
cv2.imshow(“Image”,image)
cv2.waitKey(0)
cv2.delestroyAllWindows()
输出: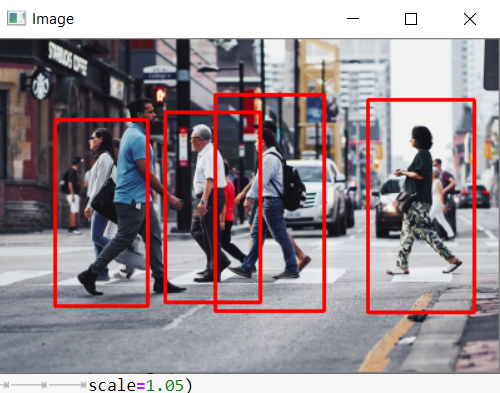
完整代码请参考:https://github.com/OmdenaAI/Tutorials/tree/Computer-Visionhttps://github.com/OmdenaAI/Tutorials/tree/Computer-Vision
YOLO简介
YOLO是物体探测器的重要类型之一。YOLO与大多数其他对象检测体系结构不同,因为它的操作方式完全不同。大多数方法将模型转换为不同大小和位置的图像。图像的高分区域被称为检测。另一方面,YOLO只使用一个神经网络来处理整个图像。该网络将图像划分为区域,并计算每个区域的边界框和概率。这些边界框由预测的概率加权。
总而言之,我们可以说,目标检测为计算机视觉和人工智能带来了新的面貌,造福于社会。目标检测的使用我们已经看到了目标检测在我们的日常生活中的应用。学习了Open CV和YOLO的基础知识,构建了完整的行人检测模型。
原创文章,作者:fendouai,如若转载,请注明出处:https://panchuang.net/2021/07/30/%e4%bb%8estratch%e5%ad%a6%e4%b9%a0opencv%e6%9e%84%e5%bb%ba%e8%a1%8c%e4%ba%ba%e6%a3%80%e6%b5%8b%e5%99%a8-2/
